これは何?
SkyWay に WebRTC GW が labs リリースされ(わーい)、WebRTC 使ってほんと色んなことができるようになったので、OpenCVなんかと組み合わせて顔検出やってみたよという記事
SkyWay WebRTC GWって?
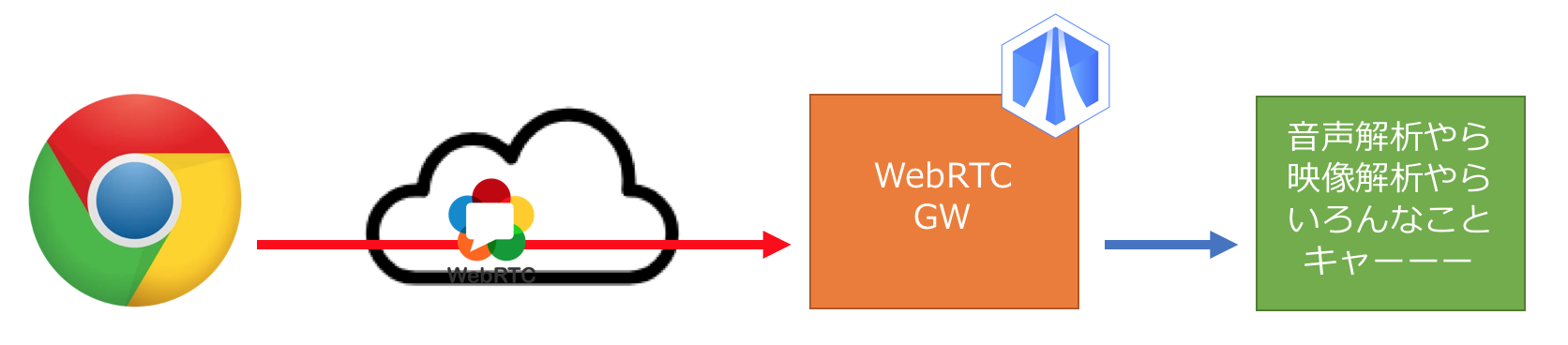
WebRTCのプロトコルゲートウェイ。例えば、WebRTC で暗号化送信されてきたメディアデータを RTP の生データとして取り出すことができる。解析処理とか加工処理とか自由自在。AIとかMLと組み合わせれば音声認識やら映像解析やら好き放題できちゃう。たまらん。
頑張れば、オレオレ Amazon Echo や Google Home だって作れちゃうぞ!きっと 1 2
この記事を読めば作れるもの
論より証拠。デモサイトをチェック
https://34.221.167.183:9001/
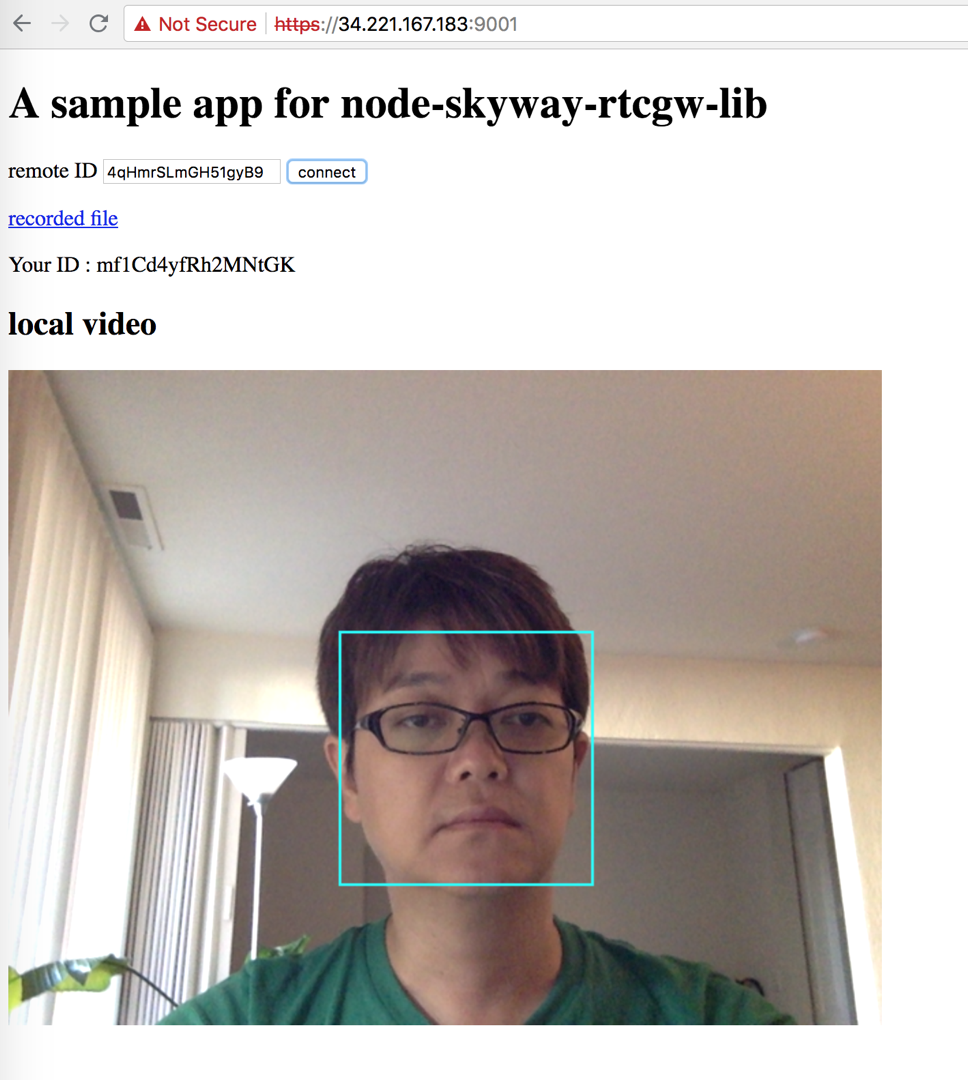
connect ボタンを押すと、クラウドに deploy した SkyWay WebRTC GWに繋がる3。そんで、裏側のごにょごにょで、顔検出した結果が表示されるっていうシンプルなデモ。
あと、音声も録音されてて、画面上部の recorded file から確認できる(リロードしたり、タブ閉じれば音声ファイル消すようにしてあるのでご安心を)
こういうサービスを、どうやったら作れる?っていうのがこの記事。レポジトリは https://github.com/rtc-iot-tech/node-skyway-rtcgw-lib
作り方
サンプル app が /examples 以下にあるので、そのコードの重要なところをピックアップして作り方を紹介。
Overview は下図の感じ。
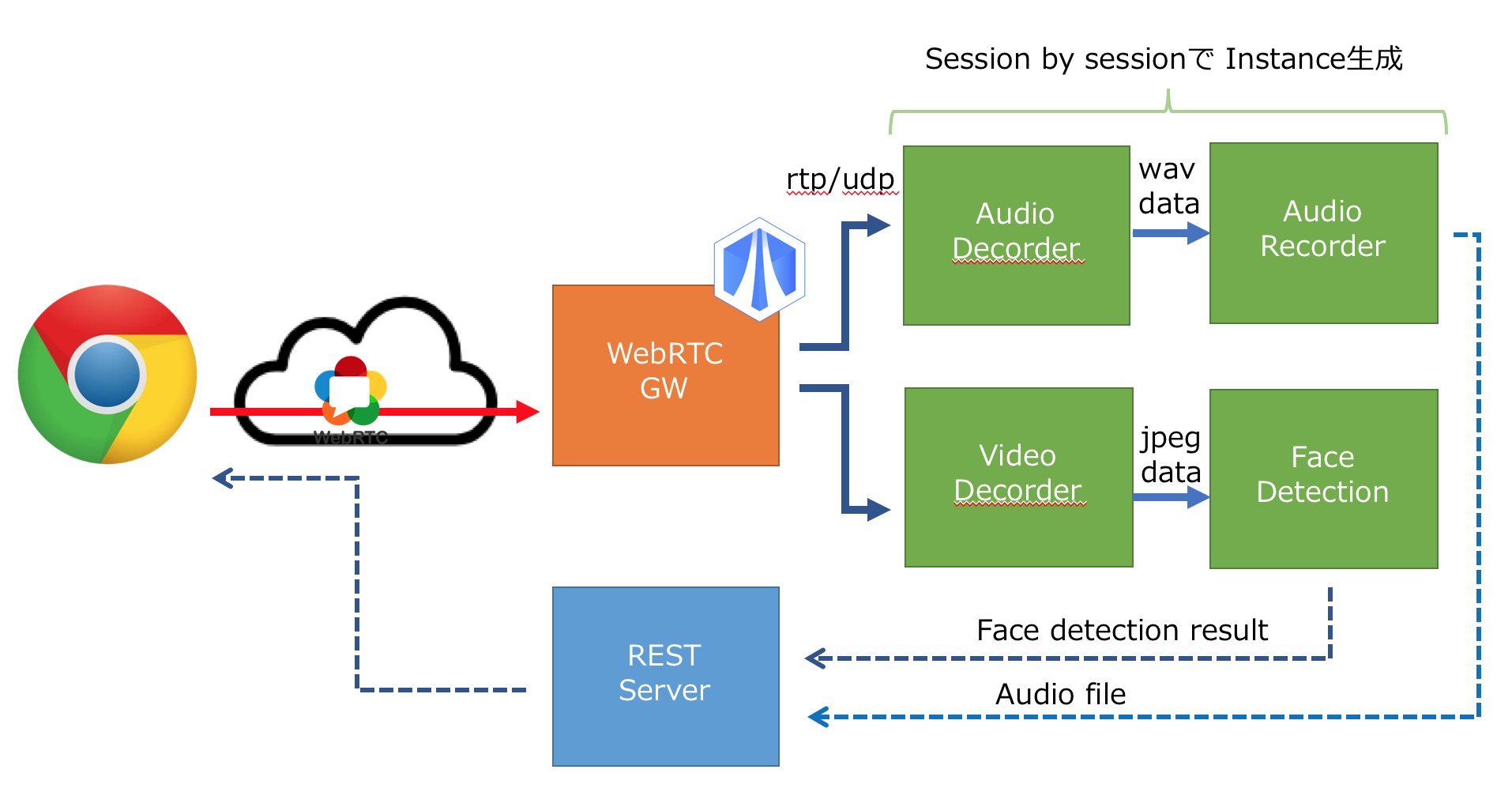
SkyWay WebRTC GW の制御
SkyWay WebRTC GW 自体は、一つのプロセスになっていて、外部プロセスから REST で制御してやる必要がある。REST を直接叩くより、それをラップしたライブラリになってると便利なので、それの node 版を試しに作って見たというのが、 https://github.com/rtc-iot-tech/node-skyway-rtcgw-lib
これを使って、クライアントからの call の都度、メディアデコーダーとかの各種インスタンスを呼び出してる
rtcgw = await open({
'key': APIKEY
})
const local_id = rtcgw.getPeerId();
server.setPeerId(local_id);
console.log(`setup completed with WebRTC GW. your peer id is ${local_id}`)
rtcgw.on('call', async call => {
///////////////////////////////////////
// make answer
const localStream = await getUserMedia( {video: true, audio: true} )
const redirect_params = {
video: { ip_v4: "127.0.0.1", port: getPort() },
audio: { ip_v4: "127.0.0.1", port: getPort() }
}
await call.answer( localStream, redirect_params );
///////////////////////////////////////
// execute scenario, session by session
const remoteStream = call.getRemoteStream()
const status = await call.status()
// meta includes client peer_id as token property.
const meta = JSON.parse( status.metadata );
const scenario = new Scenario()
await scenario.start( remoteStream, meta, server );
skyway-js の WebRTC コーディングに慣れている人なら、割と読みやすいと思う(裏側で REST が走ってるので、 async/await が多用されているあたりが今風っぽいところw)。重要なのは、クライアントが繋がると call イベントが発生するのでそれをハンドルして、処理モジュールインスタンスを作っているところ。
redirect_params で、WebRTC 経由で受信した映像/音声ストリームを rtp/udp の何番ポートで出力するかを指定している。で、この辺のパラメータ 4 とともに
call.anwser()
で応答しつつ、 scenario.start() で RTP/udp データを処理するデコーダや顔検出、録音モジュールのインスタンスをシナリオ生成している。
デコーダ周り
シナリオファイル内で
this.audioDecorder = AudioDecorder.deploy( { port: remoteStream.audio.port } );
this.videoDecorder = VideoDecorder.deploy( { port: remoteStream.video.port } );
と、音声/映像デコーダーが起動されている( port には、前述の rtp/udp のポート番号が指定されている )
videoDecorder のほうだけ解説すると 5 以下のパイプラインスクリプトを node-gstreamer-superficial に喰わせてるだけ6。udpsrc で rtp を受信したのち、rtp と h264 の復号を行ったのち、フレームごとの jpeg データを jpegenc で生成する、それを appsink を使って、データとして取り出せるようにしている。メディア処理に gstreamer まじで便利。たまらない。
const caps= [
"application/x-rtp",
"media=(string)video",
"clock-rate=(int)90000",
"encoding-name=(string)H264"
].join(',');
const script = [
`udpsrc port=${port} caps=${caps}`,
'queue',
'rtph264depay',
'avdec_h264',
'videoconvert',
'jpegenc',
'appsink max-buffers=1 name=sink'
].join(" ! ");
OpenCV 使った 顔検出(Face Detection)
appsink により毎フレームの jpeg データが生成されると、以下のように data イベントとしてそれを取得できる。あとは、これに OpenCV を喰わせてやると、顔検出ができる。30fpsで顔検出プロセスを動かすのは、ちと厳しい&無駄なので、毎秒におとして顔検出を動かしている。
this.videoDecorder.on('data', async data => {
const curr = parseInt( Date.now() / 1000 );
// every 1 second
if( this.last < curr ) {
this.last = curr
const result = await FaceDetector.detect(data)
server.setResult( meta.peer_id, result )
}
});
顔検出のコードは以下の通り。ここでは、node-opencv を使っている7。 readImage() で jpeg の読み込みを行ったのち、 im.detectObject() で顔検出を行っている。ちなみに、 FACE_CASCADE の部分を書き換えると(body検出とか)検出対象を変えることができる。
cv.readImage(jpeg, (err, im) => {
if( !err ) {
const size = im.size()
const width = size[1], height = size[0]
im.detectObject(cv['FACE_CASCADE'], {}, (err, res) => {
if(!err) resolve({
size: { width, height },
rectangles: res
})
else reject(err)
});
} else {
reject(err)
}
})
録音
録音については特にコードの解説はしないけど、そんなに難しくない(audio Decorderで生成された wav のチャンクデータをファイル保存してるだけ)ので、レポジトリ を参照してほしい。
終了処理とか
これもコード解説しないけど、WebRTCセッション終了時に、これまでで起動した gstreamer とかのプラグインをきちんと終了しないと残念なことになりかねないので、お掃除は忘れずに(詳しくはレポジトリを参照)
あと、解析結果を REST で取得できるようにとかごにょごにょしてるけど、この辺もレポジトリを参照。
サンプルの動かしかた
https://github.com/rtc-iot-tech/node-skyway-rtcgw-lib#how-to-setup に、gstreamer や opencv のセットアップ含め書いておいたので、それを参照してほしい。
一点、
/examples/index.js と /examples/public/app.js
で各自取得した APIKEY に書き換えるのを忘れずに!(deploy先のURLやアドレスを 利用可能domain に設定するのも忘れずに!)
最後に
今回紹介したのは簡単な解析系だけど、デコーダー以降の部分を色んなエンジンに変更することで、より高次な処理ができるようになります。
例えば、AWS の Rekognition APIや、GCP の Speech API とbindすれば更に wktk なことに。もちろん、独自のエンジンをかましてやるのも wktk。たまらん。
あと、OpenCV で(簡易な顔検出とか)を行い、ここで検出されたら Rekognition API に投げる・・・てな prefilter 的な組み合わせもありかも8。色んな組み合わせ方を考えられるようになるのが、WebRTC GW のいいところ。
-
上の図ではクラウド経由の絵になってるけど、WebRTC GWは別にクラウド上じゃなくても構わない(ロケーションフリー)。その辺が P2P の面白いところ ↩
-
今回のデモは、EC2(オレゴン)にdeployしてます ↩
-
今回のケースだと、
localStream(WebRTC GWからクライアントに返すメディアストリーム)はいらないんだけど、勢いで作ったライブラリが何かしら指定するつくりになってるので、ご容赦を ↩ -
audioDecorder は使ってる gstreamer の plugin が違うだけなので ↩
-
gstreamer を nodeで扱うbindingライブラリ ↩
-
opencv を nodeで扱うbindingライブラリ ↩
-
Rekognition API とか相当やすいけど、塵も積もればなんとやら ↩