ざっくりいうと
- Chainerで畳み込みニューラルネット(CNN)を書いた
- AlexNetというILSVRC2012のトップのCNNを模倣した
- 実際に画像分類をしてみた
AlexNetとは
↓の論文で提案されているニューラルネット。ILSVRC2012で性能トップ。その後、AlexNetを深化させた、オックスフォード大のVGGというネットワークが登場し性能向上。(2016年現在、さらに性能を上回るGoogLeNetとかもある。人間より精度が良いらしい。)
↓Chainerのサンプルもある。
今回は、このAlexNetの劣化版のネットワークを書いて実際に画像分類をさせてみた。劣化の理由は、単にメモリ不足を解消するためネットワークの次元数を減らしたからである。
今回作ったネットワークが以下。
cnn.py
class cnn(Chain):
def __init__(self):
super(cnn, self).__init__(
conv1=L.Convolution2D(3, 48, 3, stride=1),
bn1=L.BatchNormalization(48),
conv2=L.Convolution2D(48, 128, 3, pad=1),
bn2=L.BatchNormalization(128),
conv3=L.Convolution2D(128, 192, 3, pad=1),
conv4=L.Convolution2D(192, 192, 3, pad=1),
conv5=L.Convolution2D(192, 128, 3, pad=1),
fc6=L.Linear(2048, 1024),
fc7=L.Linear(1024, 1024),
fc8=L.Linear(1024, 10),
)
self.train = True
def clear(self):
self.loss = None
self.accuracy = None
def forward(self, x_data, t_data):
self.clear()
x, t = chainer.Variable(x_data, volatile=False), chainer.Variable(t_data, volatile=False)
h = self.bn1(self.conv1(x), test=not self.train)
h = F.max_pooling_2d(F.relu(h), 3, stride=2)
h = self.bn2(self.conv2(h), test=not self.train)
h = F.max_pooling_2d(F.relu(h), 3, stride=2)
h = F.relu(self.conv3(h))
h = F.relu(self.conv4(h))
h = F.relu(self.conv5(h))
h = F.max_pooling_2d(F.relu(h), 2, stride=2)
h = F.dropout(F.relu(self.fc6(h)), train=self.train)
h = F.dropout(F.relu(self.fc7(h)), train=self.train)
h = self.fc8(h)
self.loss = F.softmax_cross_entropy(h, t)
self.accuracy = F.accuracy(h, t)
if self.train:
return self.loss, self.accuracy
else:
return h.data, self.accuracy
Chainerのサンプルと見比べるとわかるが、カーネル数とフィルタサイズを小さくしている。
画像データ
↓のCIFAR-10 datasetを使った。
これは飛行機や動物といった10クラスの画像が、1クラスあたり6000枚あるデータセットだ。1枚の画像サイズは$32\times 32$で、RGBの3チャネルを持っている。親切なことにpythonでデータを読み込み、配列に格納するサンプルも書かれている。ただし、この方法で読み込んだデータの構造は、最初の$1024 (=32\times 32)$個の要素がR、次の$1024$がG、次の$1024$がBという並びになっているので、ChianerのConvolution2D()関数が読み込みる形に変換する必要がある。
以下のサイトを参考にして次にように変換した。
x_train = x_train.reshape((len(x_train), 3, 32, 32))
また、$6000$枚$\times 10$クラスの合計$60000$枚のうち、今回は$10000$枚を学習データ、$10000$枚をテストデータとして使った。学習データ数を増やせばもっと精度が向上できるだろう。
性能評価
学習ループを20epoch回した時の結果。精度は56%程度だった。
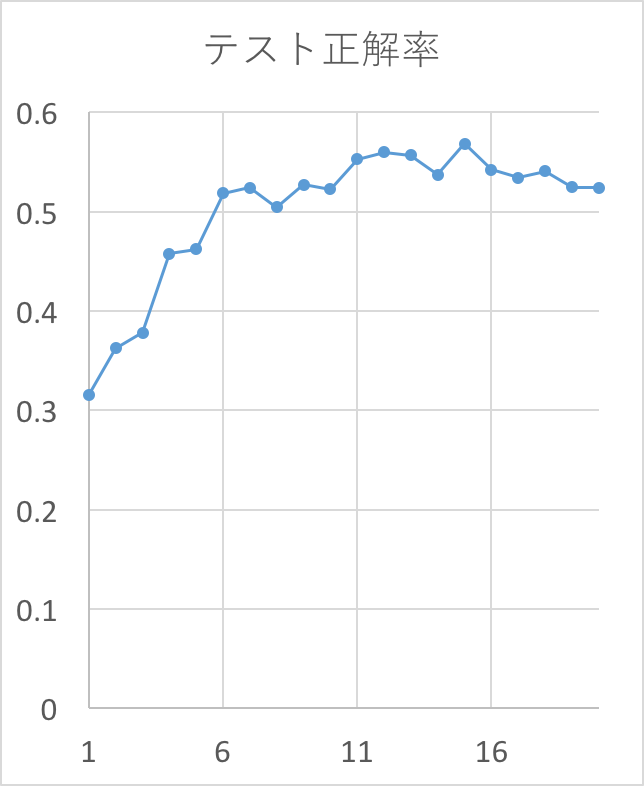
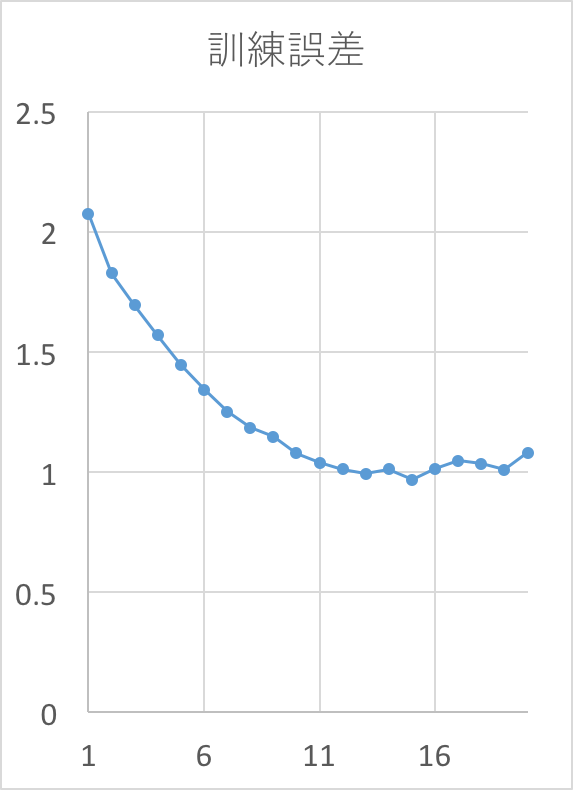
コード全体
cnn.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
__version__ = '0.0.1'
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import re
import logging
logger = logging.getLogger(__name__)
handler = logging.StreamHandler()
logger.setLevel(logging.DEBUG)
logger.addHandler(handler)
import pprint
def pp(obj):
pp = pprint.PrettyPrinter(indent=1, width=160)
str = pp.pformat(obj)
print re.sub(r"\\u([0-9a-f]{4})", lambda x: unichr(int("0x"+x.group(1),16)), str)
import os, math, time
import numpy as np
import cPickle as pickle
import copy
import chainer
from chainer import cuda, Function, gradient_check, Variable, optimizers, serializers, utils, Link, Chain, ChainList
import chainer.functions as F
import chainer.links as L
import subprocess
def unpickle(f):
import cPickle
fo = open(f, 'rb')
d = cPickle.load(fo)
fo.close()
return d
def load_cifar10(datadir, n_batch):
train_data = []
train_target = []
if n_batch > 5:
return -1
# load train data
for i in range(1, n_batch+1):
d = unpickle("%s/data_batch_%d" % (datadir, i))
train_data.extend(d["data"])
train_target.extend(d["labels"])
# load test data
d = unpickle("%s/test_batch" % (datadir))
test_data = d["data"]
test_target = d["labels"]
train_data = np.array(train_data, dtype=np.float32)
train_target = np.array(train_target, dtype=np.int32)
test_data = np.array(test_data, dtype=np.float32)
test_target = np.array(test_target, dtype=np.int32)
# normalization
train_data /= 255.0
test_data /= 255.0
return train_data, test_data, train_target, test_target
"""
CNN with Batch-Normalization
"""
class cnn(Chain):
def __init__(self):
super(cnn, self).__init__(
conv1=L.Convolution2D(3, 48, 3, stride=1),
bn1=L.BatchNormalization(48),
conv2=L.Convolution2D(48, 128, 3, pad=1),
bn2=L.BatchNormalization(128),
conv3=L.Convolution2D(128, 192, 3, pad=1),
conv4=L.Convolution2D(192, 192, 3, pad=1),
conv5=L.Convolution2D(192, 128, 3, pad=1),
fc6=L.Linear(2048, 1024),
fc7=L.Linear(1024, 1024),
fc8=L.Linear(1024, 10),
)
self.train = True
def clear(self):
self.loss = None
self.accuracy = None
def forward(self, x_data, t_data):
self.clear()
x, t = chainer.Variable(x_data, volatile=False), chainer.Variable(t_data, volatile=False)
h = self.bn1(self.conv1(x), test=not self.train)
h = F.max_pooling_2d(F.relu(h), 3, stride=2)
h = self.bn2(self.conv2(h), test=not self.train)
h = F.max_pooling_2d(F.relu(h), 3, stride=2)
h = F.relu(self.conv3(h))
h = F.relu(self.conv4(h))
h = F.relu(self.conv5(h))
h = F.max_pooling_2d(F.relu(h), 2, stride=2)
h = F.dropout(F.relu(self.fc6(h)), train=self.train)
h = F.dropout(F.relu(self.fc7(h)), train=self.train)
h = self.fc8(h)
self.loss = F.softmax_cross_entropy(h, t)
self.accuracy = F.accuracy(h, t)
if self.train:
return self.loss, self.accuracy
else:
return h.data, self.accuracy
if __name__ == '__main__':
from argparse import ArgumentParser
parser = ArgumentParser(description='RAE')
parser.add_argument('--data_dir', type=unicode, default='', help='directory path to the cifar10 data')
parser.add_argument('--n_data', type=int, default=1, help='# of data')
parser.add_argument('--n_epoch', type=int, default=20, help='# of epochs')
parser.add_argument('--batchsize', type=int, default=1, help='size of mini-batch')
parser.add_argument('--gpu', type=int, default=-1, help='GPU ID (negative value indicates CPU)')
args = parser.parse_args()
"""
Get params
"""
# the number of training itaration
n_epoch = args.n_epoch
# the size of mini batch
batchsize = args.batchsize
# define cupy
xp = cuda.cupy if args.gpu >= 0 else np
"""
Load data
"""
print 'load CIFAR-10 dataset'
x_train, x_test, y_train, y_test = load_cifar10(args.data_dir, args.n_data)
N_train = y_train.size
N_test = y_test.size
print N_train, N_test
x_train = x_train.reshape((len(x_train), 3, 32, 32))
x_test = x_test.reshape((len(x_test), 3, 32, 32))
"""
Prepare Acnn model
"""
model = cnn()
"""
Setup optimizer
"""
optimizer = optimizers.SGD()
optimizer.setup(model)
"""
Setup GPU
"""
if args.gpu >= 0:
cuda.get_device(args.gpu).use()
model.to_gpu()
"""
Training Loop
"""
for epoch in range(1, n_epoch + 1):
print "epoch: %d" % epoch
perm = np.random.permutation(N_train)
sum_loss = 0
for i in range(0, N_train, batchsize):
x_batch = xp.asarray(x_train[perm[i:i + batchsize]])
y_batch = xp.asarray(y_train[perm[i:i + batchsize]])
optimizer.zero_grads()
loss, acc = model.forward(x_batch, y_batch)
loss.backward()
optimizer.update()
sum_loss += float(loss.data) * len(y_batch)
print "train mean loss: %f" % (sum_loss / N_train)
sum_accuracy = 0
for i in range(0, N_test, batchsize):
x_batch = xp.asarray(x_test[i:i + batchsize])
y_batch = xp.asarray(y_test[i:i + batchsize])
loss, acc = model.forward(x_batch, y_batch)
sum_accuracy += float(acc.data) * len(y_batch)
print "test accuracy: %f" % (sum_accuracy / N_test)