こんにちは
簡単に自己紹介をします。去年まで東京のデジハリで1年間デザインやプログラミングの勉強をしていました。今年の8月から株式会社たき工房 でプログラマーをしています。個人ではTouchDesignerで映像制作やVJをしています。(Twitter)
入社してから初めて作ったコンテンツがこちらです!11/17に大阪で行われたdotFes2019というイベントに出展しました。当日はたくさんの人に楽しんでもらえて大盛況でした!(動画は制作途中のものです)
クスールさんと合同で
— komakinex (@komakinex) November 12, 2019
「ブロックに表示されている漢字を、ボードに書いてカメラに認識させると、そのままボードを動かしてブロックを引き抜くことができるゲーム」を作ってます!これは1週間前のデモ #dotFes #dotFes2019 #madewithunity #TouchDesigner pic.twitter.com/W3Q11eS3c6
自分はディスプレイ画面のシステムと、プレイヤーが持つホワイトボードの検出し、文字が書かれた部分を画像で保存するという部分を担当しました。その過程で初めてPythonやOpenCVを触り、TouchDesignerで実装しました。
同じような工程で顔認識できそうだなと思い、やってみました。
出来上がり
顔認識!#TouchDesigner #OpenCV pic.twitter.com/q1XvTdZH1y
— komakinex (@komakinex) November 30, 2019
顔認識した部分にモザイクをかける処理をしています。
サンプルファイル
↓ここにあります↓
https://github.com/komakinex/TD_AdventCalendar2019_facedetect
Perform Modeにすると顔検出が働かない事に関しての追記 2020/5/10
突然失礼します
— AIT (@AIT_iam) May 9, 2020
こちらのbaseの顔認識した部分にピンク色の四角を表示させるものをPerform Modeで実行すると、初めに四角が表示された後、四角が顔を追従してくれないのですが、Perform Modeでずっと顔を追従させるにはどうしたらよいでしょうか
お時間あるときでよいので教えていただけると嬉しいです
face_detect DATは、PostCookを使っているので、参照しているface_pre TOPのCookに変更があった後に処理が走るようになっています。なので顔検出が働いていないのは、face_pre TOPのCookに変更がないからだと考えられます。
face_pre TOPにCookが走った時(face_pre TOPの映像に変化があった時)に、顔検出するようになっているのですが、階層が変わるとface_pre TOPが動かなくなってしまうので、顔検出の処理が止まっている、ということです。
TouchDesignerのCookについては@kodai100 さんの記事がわかりやすいです。
https://qiita.com/kodai100/items/be672ea8978e443867b0
TouchDesignerの仕様で、表示していない階層のTOPは特定のTOPを除いて、Cookが止まっています。
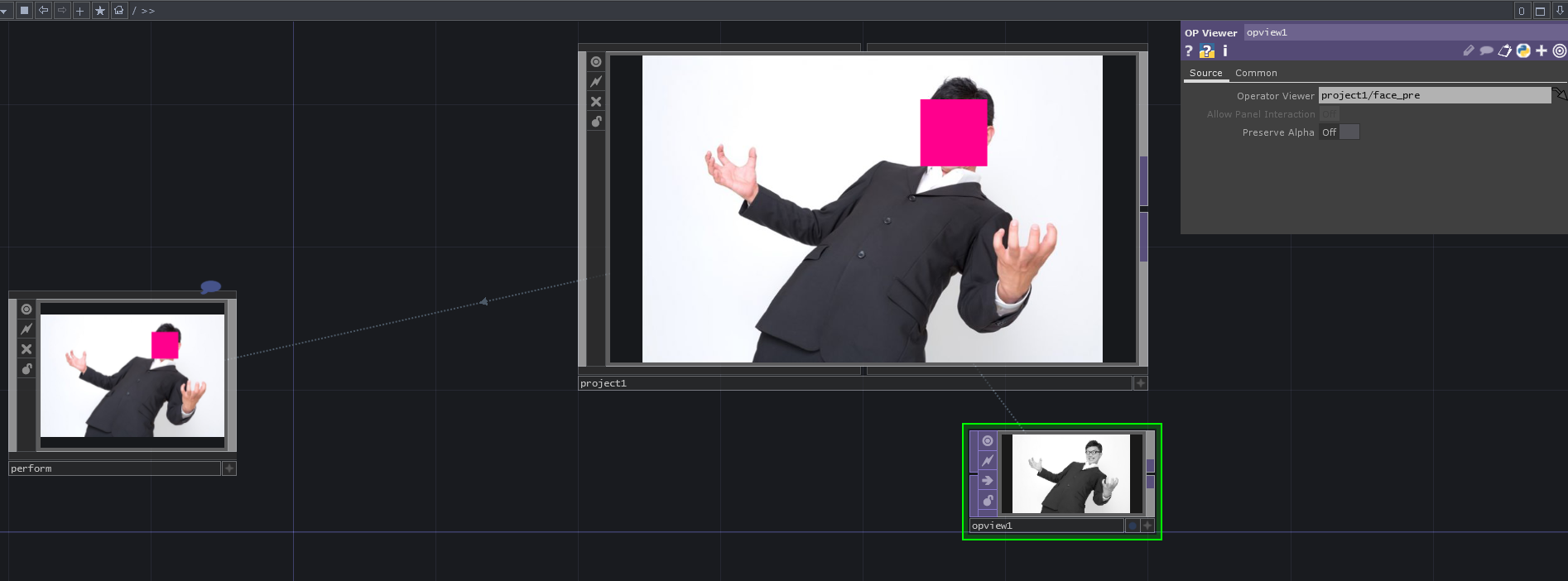
サンプルファイルのface_detectP.toeを見てもらうと、Opviewer TOPでface_pre TOPを、Perform Modeのときに表示されるCOMP(project1)と同じ階層で見えるようにしています。
こうすることでPerform Modeにした時でもface_pre TOPのCookが走り続けるので顔検出が働くようになります。
また、CHOPでのCookに対する処理だと@shiyuugo さんのこちらの記事が参考になります。
https://qiita.com/shiyuugo/items/cc043b3cafd594ee8aa4
追記終わり
動作環境
Windows10
TouchDesigner 099 2019.19930
TouchDesigner 099 2020.22080
macOS 10.14.6
TouchDesigner 099 2019.20140
TouchDesigner 099 2020.22080
で確認済みです!
説明
OpenCVや顔認識についての詳細な説明は省きます!
大まかな流れを説明した後、サンプルファイルの、認識した顔のうち1つだけにマスクを被せるbase、認識した顔全部にモザイクをかけるfacesの順に説明していきます。
参考にした記事
・PythonでOpenCVを使って顔を検出している記事
顔検出の基本的な部分を参考にしました。
https://note.nkmk.me/python-opencv-face-detection-haar-cascade/
https://qiita.com/FukuharaYohei/items/ec6dce7cc5ea21a51a82
・TouchDesignerでOpenCVを使って特徴点抽出している記事
抽出した点にジオメトリを当てていること、レンダリング結果を元の画像とうまく合わせている部分を参考にしました。
http://satoruhiga.com/post/extending-touchdesigner/
・TouchDesignerでOpenCVを使って動体追跡している記事
顔認識で使えるように、配列の変換を参考にしました。
https://www.velvet-number.com/atsushi/2019/06/21/150-touchdesigner%e3%81%aepython%e3%81%a7opencv%e3%82%92%e5%ae%9f%e8%a3%85%e3%81%97%e3%81%a6%e3%81%bf%e3%82%8b01/
配列の上下反転
https://www.velvet-number.com/atsushi/2019/06/28/152-touchdesigner%e3%81%aepython%e3%81%a7opencv%e3%82%92%e5%ae%9f%e8%a3%85%e3%81%97%e3%81%a6%e3%81%bf%e3%82%8b02/
用意するもの
・TouchDesigner
・顔認識したい画像、webカメラなど
・顔認識の検出器↓
https://github.com/opencv/opencv/tree/master/data/haarcascades
正面を向いた顔を検出したいのでhaarcascade_frontalface_~を使います。自分はdefaultを使っています。altなどとは精度や顔認識の基準(判定の厳しさ?)の違いがあるみたいです。
それぞれがしてること
TouchDesigner
・画像の読み込み
・解像度やアスペクト比の調整
・マスクの生成
Python
・顔の検出
・検出した場所を四角形で囲み、TouchDesignerにその四角形の座標と大きさを渡す
説明
baseとfacesの内容を、順に説明していきます。
① base
検出器の準備
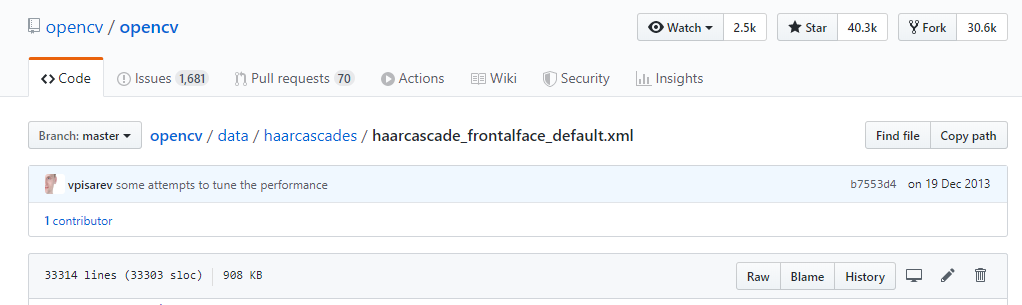
顔認識するには、顔を検出できる検出器が必要です。自分が使っているhaarcascade_frontalface_default.xmlは、以下のリンク先のRawを押し、出てきた画面をCtrl+S、もしくは右クリック → 名前を付けて保存でゲットできます。
https://github.com/opencv/opencv/blob/master/data/haarcascades/haarcascade_frontalface_default.xml
ノードを組む
ポイントは、Pythonに渡す前に画像の解像度を1/4にしていることと、モノクロにしていることです。リアルタイムに動かすため、処理の高速化を図っています。
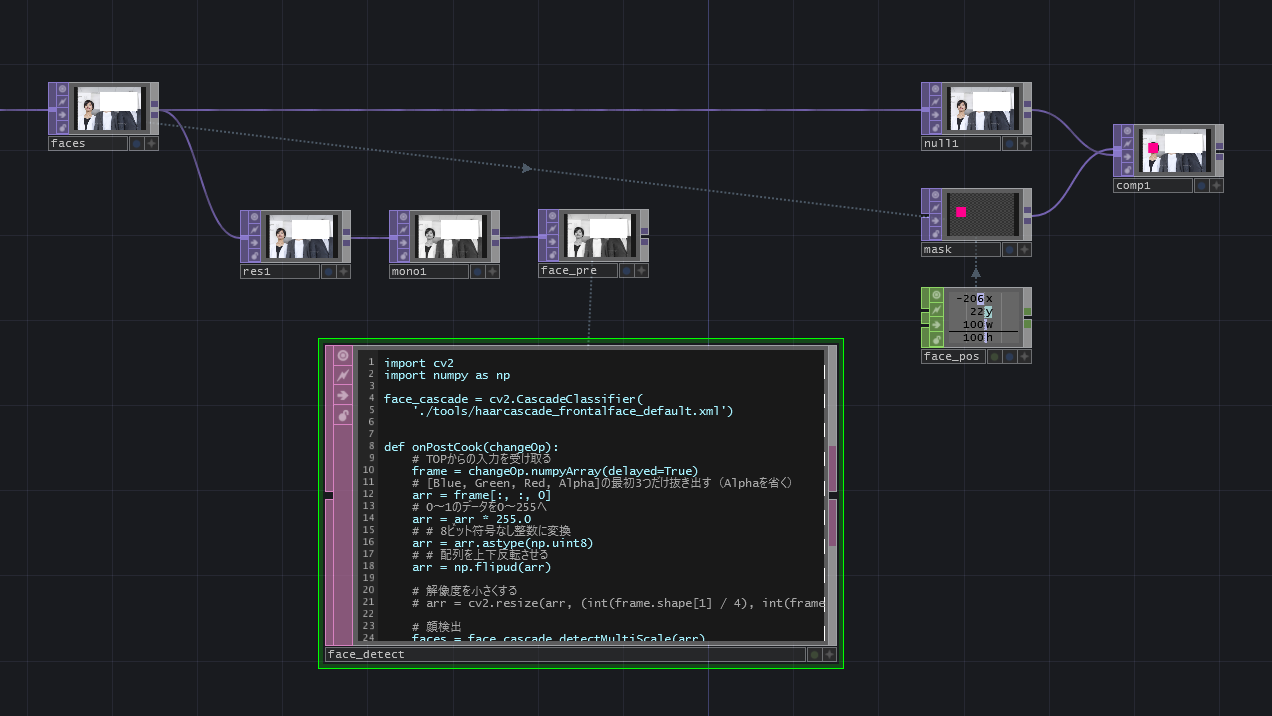
・face_input:顔認識したい画像や映像を受け取ります。
・res1:解像度を元画像の1/4にして、処理の負荷を軽くしています。
・face_detect:face_preにCookが走った後にここに書いたPythonが動くようになっています。顔を検出する処理が書かれています。
・face_pos:検出された顔の位置と幅の情報をface_detectから受け取っています。maskのsizexやcenterxに直接値を入れてもいいです。見やすいようにface_posで受けています。
・mask:顔の部分を覆う用の四角形を生成しています。
・comp1:元画像にマスクを被せています。
face_detect内
import cv2
import numpy as np
face_cascade = cv2.CascadeClassifier('./tools/haarcascade_frontalface_default.xml')
def onPostCook(changeOp):
arr = changeOp.numpyArray(delayed=True)
gray = arr[:, :, 0]
gray = gray * 255.0
gray = gray.astype(np.uint8)
gray_invert = np.flipud(gray)
faces = face_cascade.detectMultiScale(gray_invert)
if len(faces) > 0:
resX = op('face_pre').width
resY = op('face_pre').height
for (x, y, w, h) in faces:
centerX = ((x + w/2) - resX/2) * 4
centerY = (-(y + h/2) + resY/2) * 4
op('face_pos').par.value0 = centerX
op('face_pos').par.value1 = centerY
op('face_pos').par.value2 = w * 4
op('face_pos').par.value3 = h * 4
pass
return
準備
import cv2
import numpy as np
face_cascade = cv2.CascadeClassifier('./tools/haarcascade_frontalface_default.xml')
def onPostCook(changeOp):
return
まずOpenCVと、配列を扱うライブラリNumpyをインポートします。
次にcv2.CascadeClassifierで検出器を生成します。サンプルファイルでは、face_detect.toeと同階層のフォルダtools内にhaarcascade_frontalface_default.xmlが置いてあるのでファイルの指定が'./tools/haarcascade_frontalface_default.xml'という書き方になっています。.xmlファイルを置いた場所によって適宜書き換えてください。
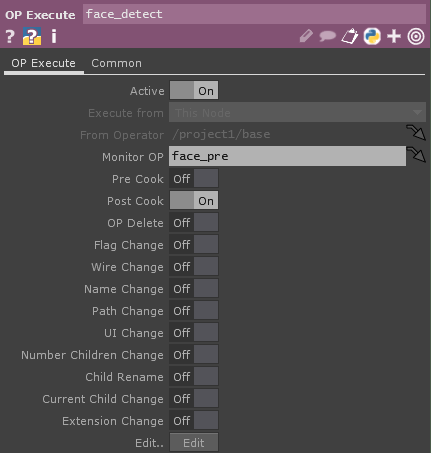
onPostCookの中にCookが走った後に起こってほしい処理を書きます。
また、face_detectのPost CookをONにするのを忘れないようにしてください。
onPostCook内
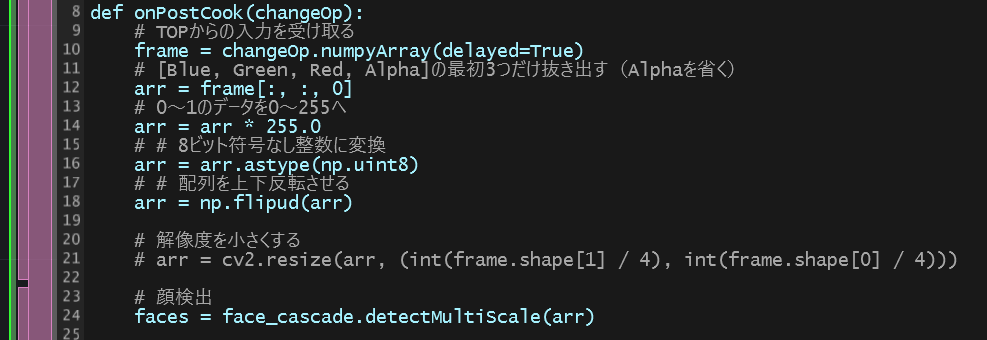
arr = changeOp.numpyArray(delayed=True)
gray = arr[:, :, 0]
参考にした記事によると
TOPのクラスの
.numpyArray(delayed=True)のメソッドを呼び出すとnumpy.ndarrayの画像データが取得できます。
gray = arr[:,:,0]の部分で赤チャンネルだけ抜きだして、グレースケールにしています。delayed引数は、フレーム遅延を許容するかわりに処理を高速化するオプションです。
ということで、ここでは、入力した画像を配列として取得し、グレースケールにしています。
gray = gray* 255.0
gray = gray.astype(np.uint8)
gray_invert = np.flipud(gray)
先程の処理で取得した配列をOpenCVに渡すため、Python単体のデータ形式に変換する必要があります。参考にした記事(こちらとこちら)によると
ピクセル色情報の部分の内容が違っていて、
Python単体の場合
[Blue, Green, Red] (値の範囲は0〜255)
Touchdesigner + Pythonの場合
[Blue, Green, Red, Alpha] (値の範囲は0〜1)
ということでした。
f_arr = np.flipud (f_arr)
で配列の上下反転も必要でした。
ということで、ここでは、取得した画像の配列を、OpenCVに入るように値の範囲を0〜1から0〜255へ引き伸ばし、8ビット符号なし整数に変換し、配列を上下反転させています。
faces = face_cascade.detectMultiScale(gray_invert)
if len(faces) > 0:
画像の配列を検出器に渡し、顔が1つでも検出されると以下の処理が走るようにします。
for (x, y, w, h) in faces:
centerX = ((x + w/2) - resX/2) * 4
centerY = (-(y + h/2) + resY/2) * 4
op('face_pos').par.value0 = centerX
op('face_pos').par.value1 = centerY
op('face_pos').par.value2 = w * 4
op('face_pos').par.value3 = h * 4
pass
顔は四角形として検出されます。facesは四角形の左上のxy座標と四角形の幅と高さを情報として持っているので、それらをx y w h に代入します。
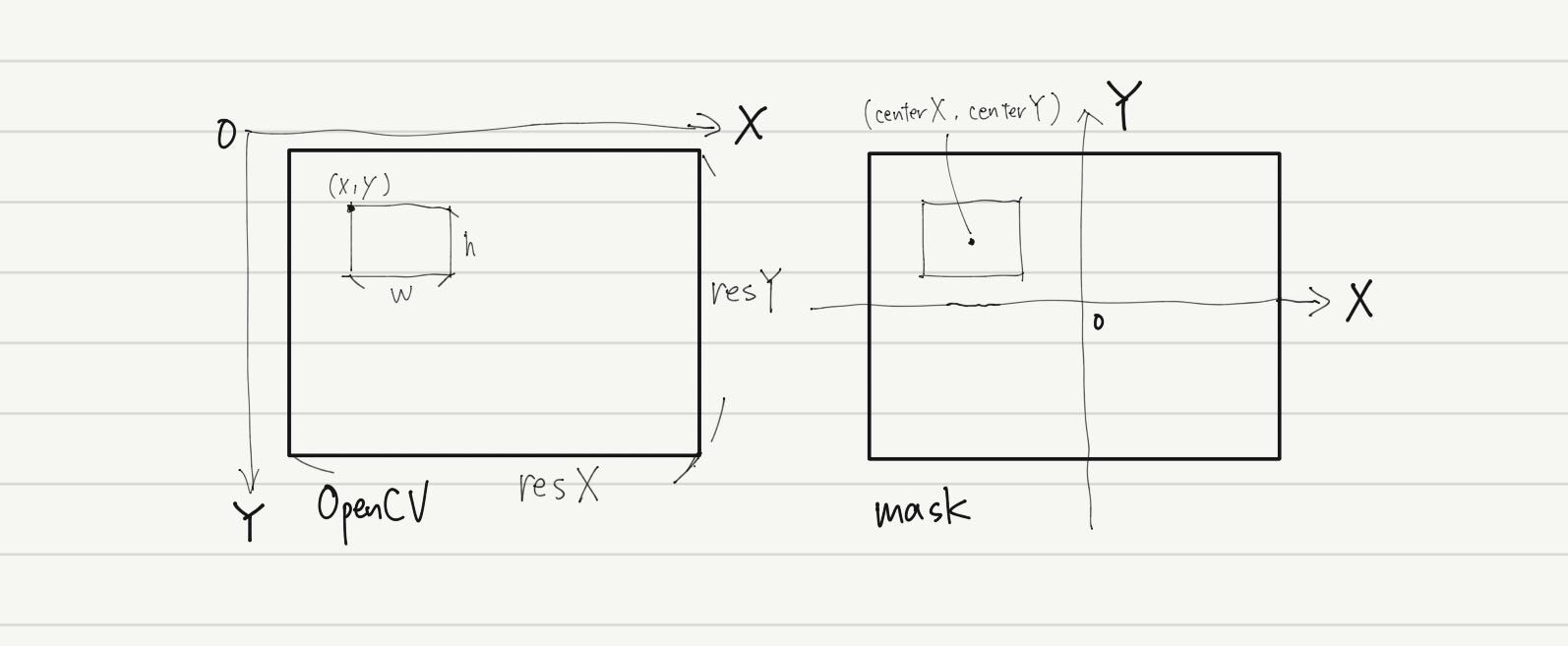
OpenCVとTouchDesignerのmaskとでは座標系がこのように異なります。
また、元画像の解像度に合わせるため最後に4倍します。
以上がbaseの説明です。
② faces
基本的な流れはbaseと同じです。baseと異なる点を説明していきます。
顔の検出
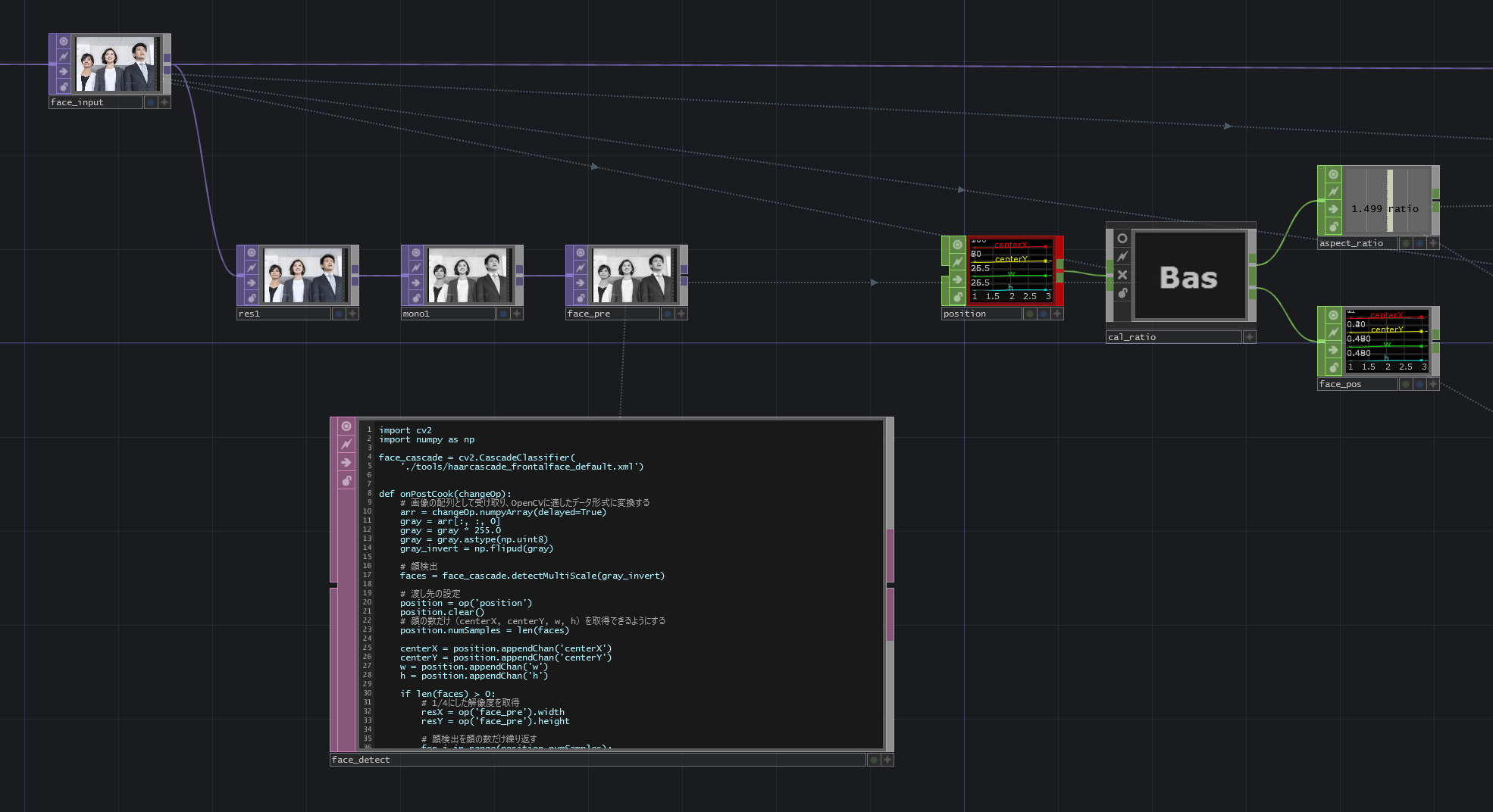
・position:検出された顔の数、位置、四角形の幅の情報をface_detectから受け取っています。
・cal_ratio:Pythonから受け取った情報を、マスクするために必要な値に計算しています。
・aspect_ratio:入力した画像の幅と高さの比です。
・face_pos:マスクするために適切に計算された顔の位置です。
cal_ratio内
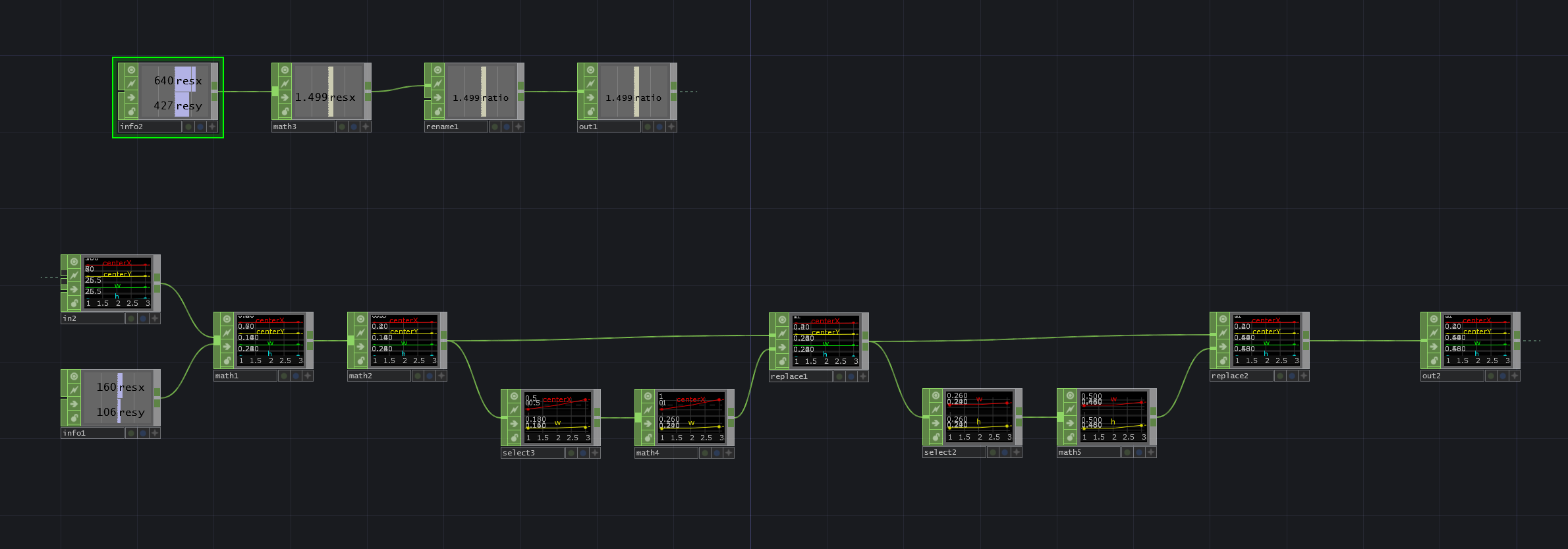
・info2:元画像の解像度です。
・math3:元画像の比を算出しています。
・info1:faec_preの解像度です。
・math1:face_detectから受け取った数値を正規化しています。
・math2:座標を0~1から-1~1に引き伸ばしています。
・math4:横方向の数値にrename1の数値をかけて、元画像と同じ比にしています。
face_detect内
import cv2
import numpy as np
face_cascade = cv2.CascadeClassifier('./tools/haarcascade_frontalface_default.xml')
def onPostCook(changeOp):
arr = changeOp.numpyArray(delayed=True)
gray = arr[:, :, 0]
gray = gray * 255.0
gray = gray.astype(np.uint8)
gray_invert = np.flipud(gray)
faces = face_cascade.detectMultiScale(gray_invert)
position = op('position')
position.clear()
position.numSamples = len(faces)
centerX = position.appendChan('centerX')
centerY = position.appendChan('centerY')
w = position.appendChan('w')
h = position.appendChan('h')
if len(faces) > 0:
resX = op('face_pre').width
resY = op('face_pre').height
for i in range(position.numSamples):
face = faces[i]
w[i] = face[2]
h[i] = face[3]
centerX[i] = face[0] + face[2]/2
centerY[i] = -(face[1] + face[3]/2) + resY
pass
return
baseと異なる点を説明していきます。
position = op('position')
position.clear()
position.numSamples = len(faces)
centerX = position.appendChan('centerX')
centerY = position.appendChan('centerY')
w = position.appendChan('w')
h = position.appendChan('h')
ここでは数値を渡す先のpositionの設定をしています。len(faces)をサンプル数にすることで、検出した顔の数だけ情報を持てるようになります。
for i in range(position.numSamples):
face = faces[i]
w[i] = face[2]
h[i] = face[3]
centerX[i] = face[0] + face[2]/2
centerY[i] = -(face[1] + face[3]/2) + resY
pass
faceには四角形の左上のx座標, y座標, 幅, 高さの4つ数字が入っています。それらをface[0]やface[1]というように取り出し、座標や幅に代入します。
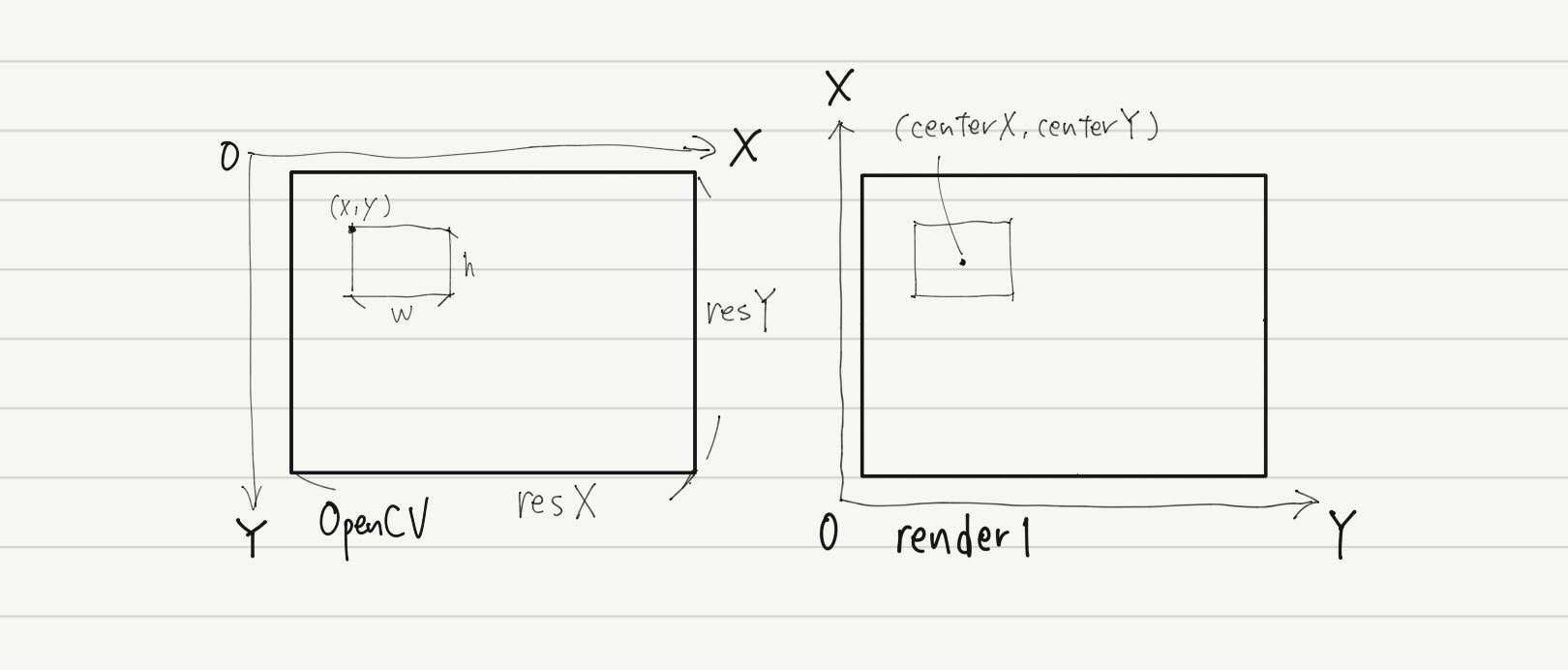
今度はこのような座標系なので、これに合うように計算します。
座標と四角形の大きさを、position.numSamples、つまり検出された顔の数だけ繰り返し取得します。
マスクの合成
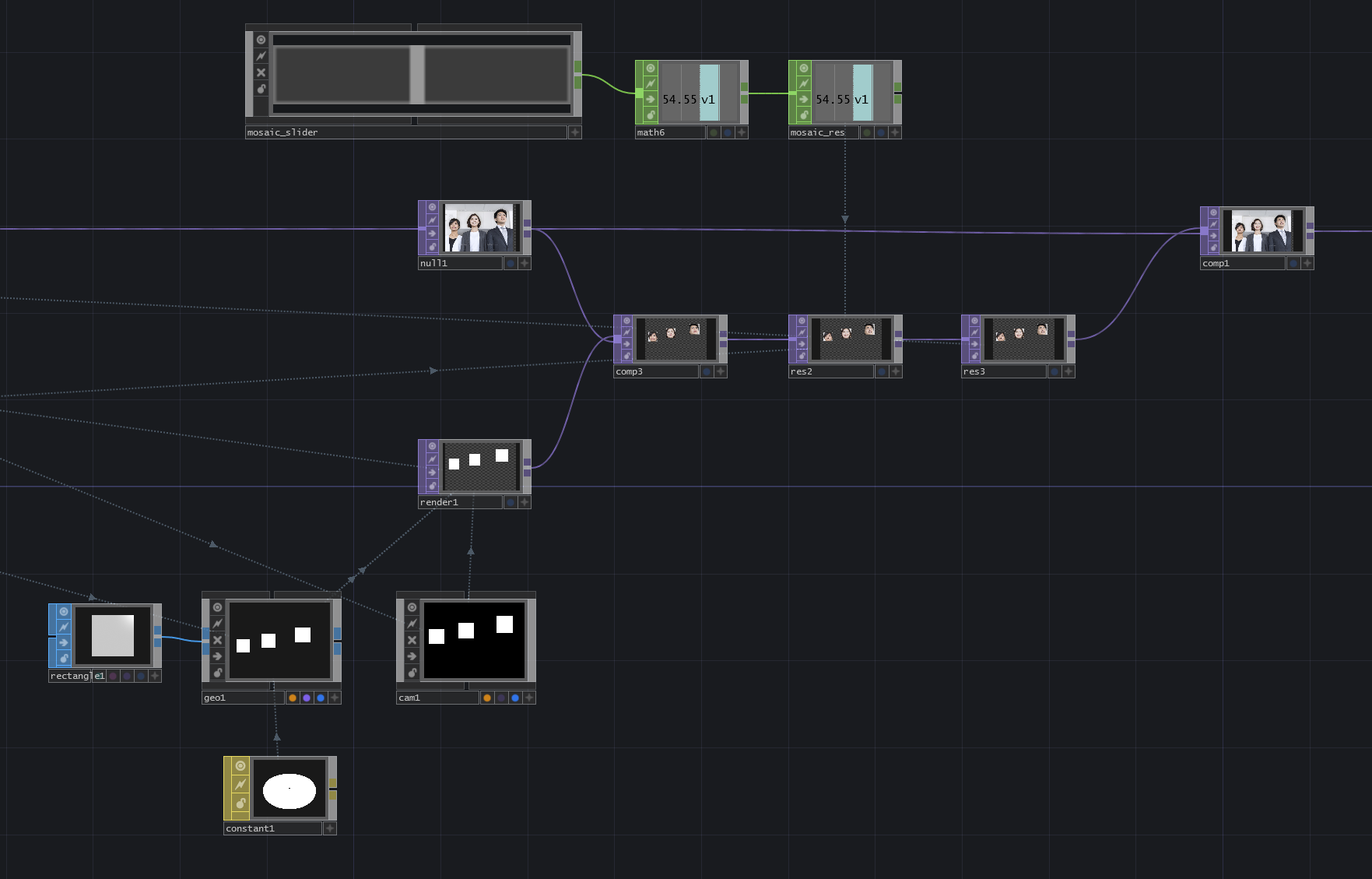
・geo1:face_posの情報から、マスクの元となる四角形をインスタンシングしています。
・cam1:投影方法をOrthographicにして、物体の距離によって大きさが変わらないようにしています。(投影について詳しくはこの記事が参考になりました。)
・render1:インスタンシングした四角形を、元画像と同じ解像度でレンダリングしています。
・res2:モザイクがかかったように見せるため、マスクされた部分(検出された顔)の解像度を下げています。mosaic_slinderによって手軽にモザイクの目の粗さを変えられるようにしています。
・res3:マスク部分の解像度を元画像に合わせています。
以上がfacesの説明です。
注意点
・face_preのViewerをオフにするとPythonが止まって顔認識できなくなります。(Cookが走らなくなるから?ぽいです)
・解像度を小さくする処理をPythonの中でするとfpsがけっこう落ちます。Pythonに渡す前にTOPで処理したほうが良いです。
(arr = cv2.resize(arr, (int(frame.shape[1] / 4), int(frame.shape[0] / 4)))の部分)
最後に
検出した座標を受け取るだけなので、TouchDesignerのノードを繋ぐ部分は簡潔な仕組みになっています。Python内で画像を配列に変換したり、元の画像と合成するための計算がややこしいので、そのあたりをできるだけ丁寧に書きました。わからないところ、間違っているところがあれば連絡してください。
告知です!12/11にたき工房でTouchDesignerのもくもく会を開催します。今後も月1で行う予定です。次回はもっと多くの人に参加してもらえるように人数の枠を増やすつもりです。
また、今後はTouchDesignerで縛らず色々なツールでもくもくする会にしていきたいなと思っています。自分のTwitterアカウントからアナウンスするので、チェックしてみてください!
Peatixをフォローしてもらえると、チケットがオープンした時通知が行きます。
→https://techlab-tdmokumoku.peatix.com/
おまけ
まったく関係ないですが、めちゃおもろかった動画を貼っておきます。
Aマッソのコント
https://youtu.be/ZxF3pdLJhiQ
藤井健太郎が千原ジュニアの過去の映像と声で、舞台にいる千原ジュニアと会話する企画です。これはその紹介動画です。
https://youtu.be/WQdy70xoGMk
ラランドの漫才
https://youtu.be/YBBjU1TtN-8
ぜひ見てみてください!