概要
- GCEインスタンス立ち上げ
- 各種パッケージインストール
- jupyter notebook導入
- GCEとGCSを接続
- Kaggle API導入
- Kaggle データセットダウンロード
1 GCEインスタンス立ち上げ
そもそもGCEって? https://qiita.com/oosha/items/746dc4a9ad16f5a6beac
左のサイドバーのComputed Engineから、インスタンスを作成する


インスタンスの名前は任意の名前
リージョンはサーバーの場所,今回はeastUS1にする。(場所によっては無料枠でなくなる、アメリカの方が何かとアクセスが早い)
マシンのメモリは、30GB(120GBとかは大学の研究などのレベル)
料金に関しては
https://cloud.google.com/compute/pricing?hl=ja
メモリの若干の目安

ブートディスクはubuntsu16,サイズは50GBくらいあればいい

アクセス権は全て許可
ファイアウォールも全てチェック

作成ボタンを押して、少し待つとインスタンスが立ち上がる

ローカルのターミナルからssh通信でGCSに接続する方法
https://qiita.com/matken11235/items/e4e7de36ef5f01f1d1d7
出来るだけ安くGCEを使う方法
https://qiita.com/Brutus/items/22dfd31a681b67837a74
2 各種パッケージインストール
SSH通信でインスタンスのシェルに入る
必要になりそうなパッケージを入れていく
gitやら何やら
sudo apt install git tmux build-essential
特にtmuxはかなり使えます。
- 1つの画面の中でウインドウを追加・分割して複数の端末を開く
- ssh切断後も端末丸ごと継続され、後でまた繋ぎ直せる
等の利点があります。
3 jupyter notebookの導入
jupyter notebookのインストールと設定
- Anacondaを入れる
- Anacondaの中にjupyter notebookも入っている
wget https://repo.anaconda.com/archive/Anaconda3-2018.12-Linux-x86_64.sh
sh Anaconda3-2018.12-Linux-x86_64.sh
これらを実行するとLicenseの確認画面が出るので、ひたすらEnterを押します。
Do you approve the license terms? [yes|no] と出てきたらyesと打ち込んでEnterです。
Anaconda3 will now be installed into this location:
/home/sonics_jr/anaconda3
- Press ENTER to confirm the location
- Press CTRL-C to abort the installation
- Or specify a different location below
と表示されたら、特に変更の必要がなければEnterです。
Do you wish the installer to prepend the Anaconda3 install location
to PATH in your /home/sonics_jr/.bashrc ? [yes|no]
これも問題なければyesと打ち込みます。
最後にsource ~/.bashrcでbashを読み込み直して終了です。
jupyter notebookを使えるようにする
# 設定ファイルの作成
jupyter notebook --generate-config
# SSL用の鍵を作成
cd .jupyter
openssl req -x509 -nodes -days 365 -newkey rsa:1024 -keyout mykey.key -out mycert.pem
次にpythonを起動して、python上でパスワードのハッシュを作ります。
以下コマンドを実行し、利用したいパスワードを二回入力し、結果をコピーして控えておきます。
>>> from notebook.auth import passwd; passwd()
Enter password:
Verify password:
vim等で設定ファイルを開き編集する(コメントアウトされている余分な設定は消しても良い)
vim ~/.jupyter/jupyter_notebook_config.py
以下の設定を書き込む
# ------------------------------------------------------------------------------
# Configurable configuration
# ------------------------------------------------------------------------------
c = get_config()
c.NotebookApp.certfile = u'/home/<username>/.jupyter/mycert.pem'
c.NotebookApp.keyfile = u'/home/<username>/.jupyter/mykey.key'
c.NotebookApp.ip = '0.0.0.0'
c.NotebookApp.open_browser = False
c.NotebookApp.port = 8888
c.NotebookApp.password = u'作成したハッシュ'
usernameはご自身のアカウント名を記入してください
pwdコマンドで確認できます
以上でjupyterの設定は完了です。
ファイアーウォールの設定
次にファイヤーウォールの設定を行います。
VPCネットワーク>ファイヤーウォールルールを選択します。

そしてファイヤーウォールルールを作成をクリック。
以下のように入力します。
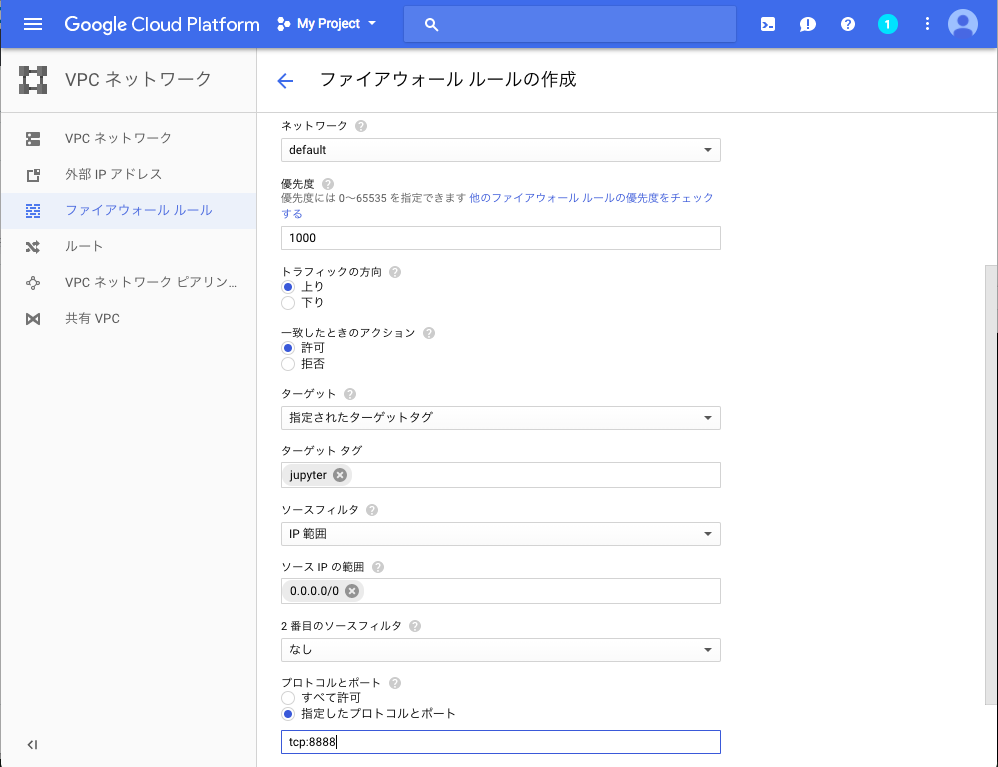
名前は任意で構いません。
ターゲットタグで指定したタグがついているネットワーク設定に適用されるので、この後でネットワークタグの設定を行います。
ソースIPの範囲は「0.0.0.0/0」を設定すると全てのIPを許可します。
ポートは、jupyterの設定ファイルに書き込んだものと同じものを設定します。
以上でファイヤーウォールルールの設定は終わりです。
インスタンス側のネットワークタグの設定
Compute>VMインスタンスをクリックし、ファイヤーウォールの設定を適用したいインスタンスをクリックし編集ボタンを押します
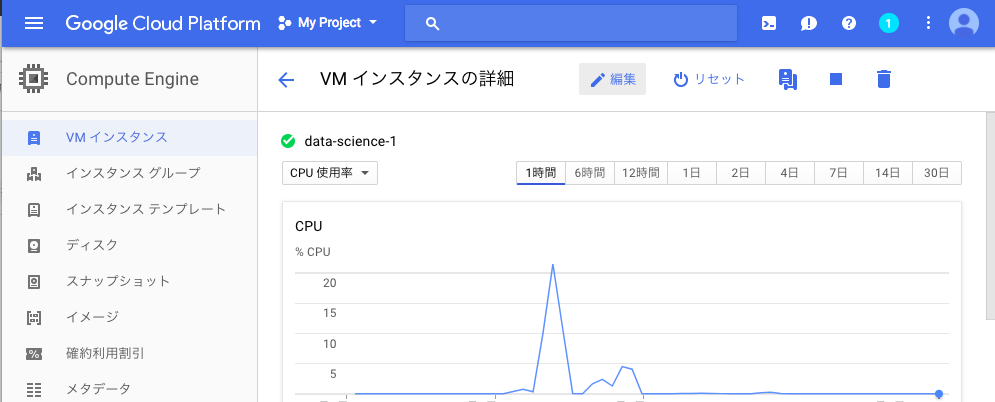
ページ中部の「ネットワークタグ」の欄に「jupyter」と入力して完了です。
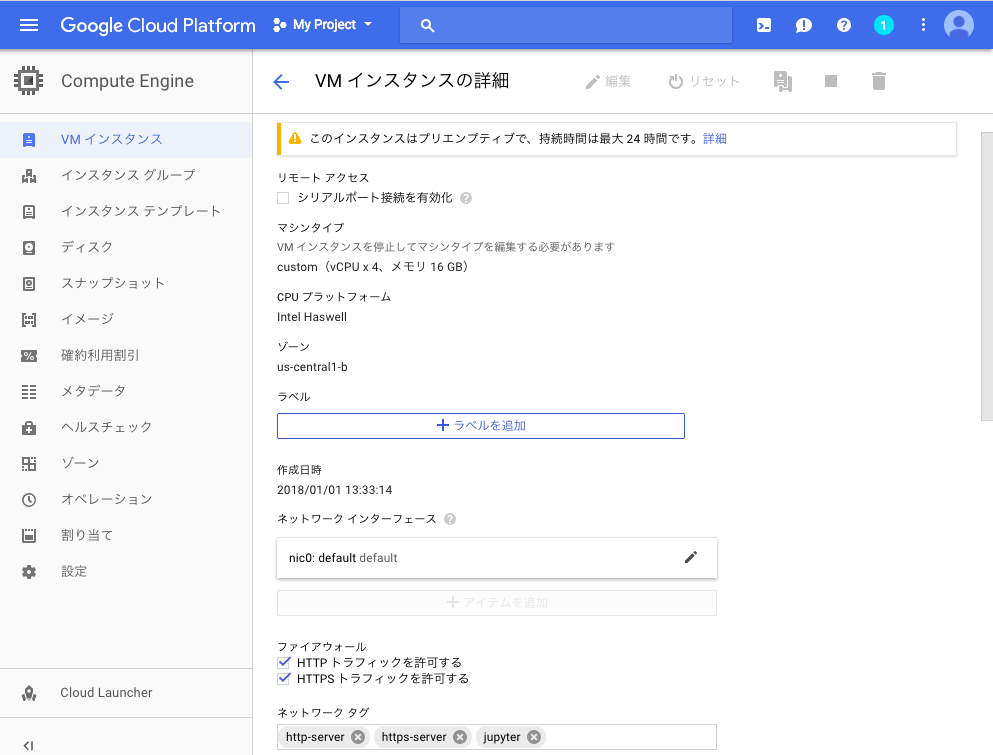
jupyterを起動してアクセス
jutyer notebookを起動させるコマンドを入力
jupyter notebook

外部IPをクリックする
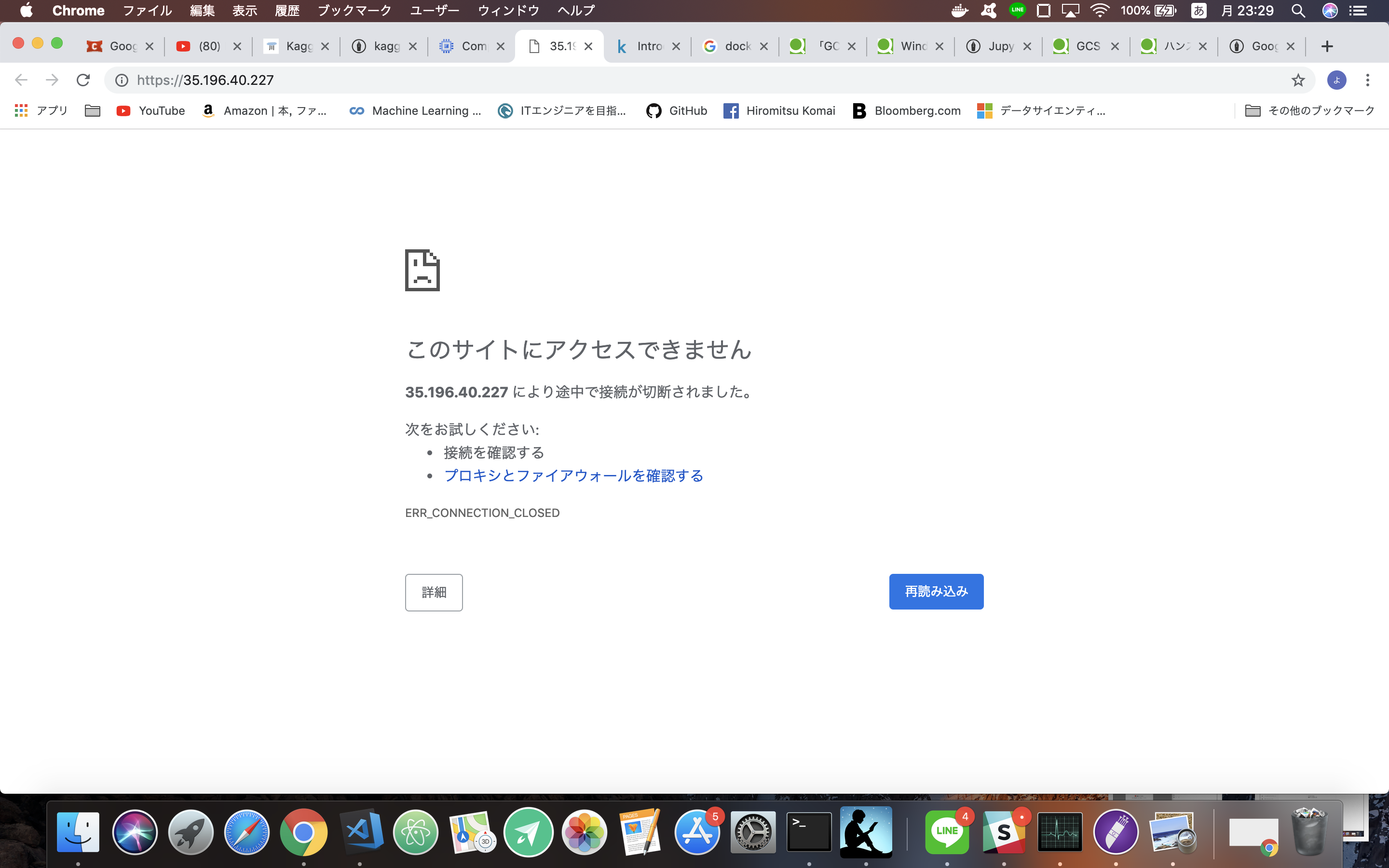
するとこのようにアクセスできないが、先ほど設定したポート、:8888をURLにつけると
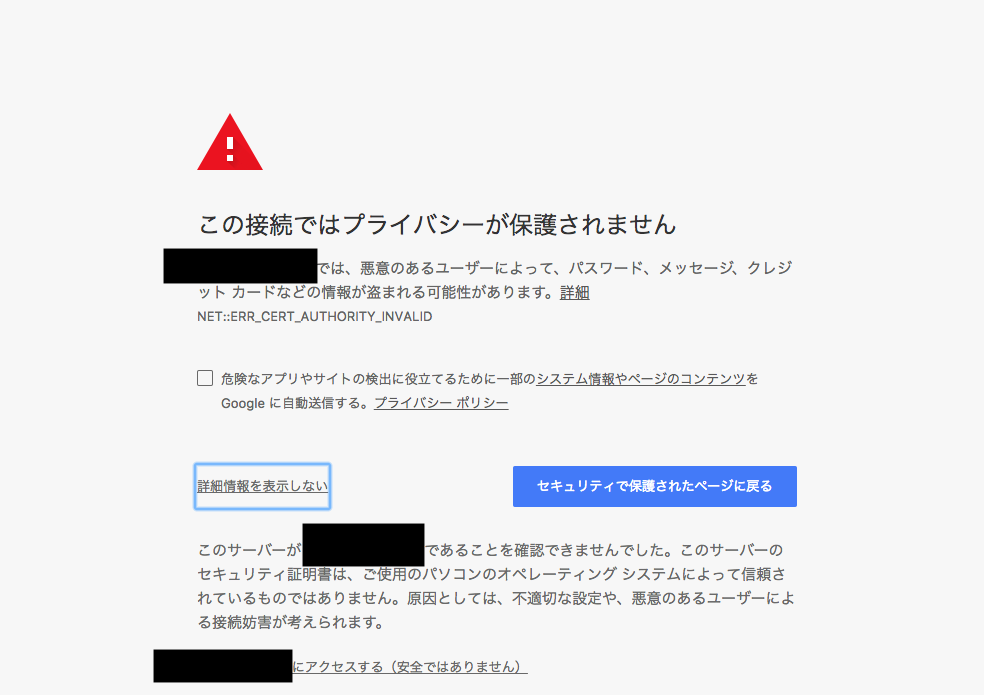
このように警告画面が出ますが、 個人利用のため無視してアクセスします。
以下の画面が出たら、先ほどハッシュ化したパスワードを入力してアクセスします。
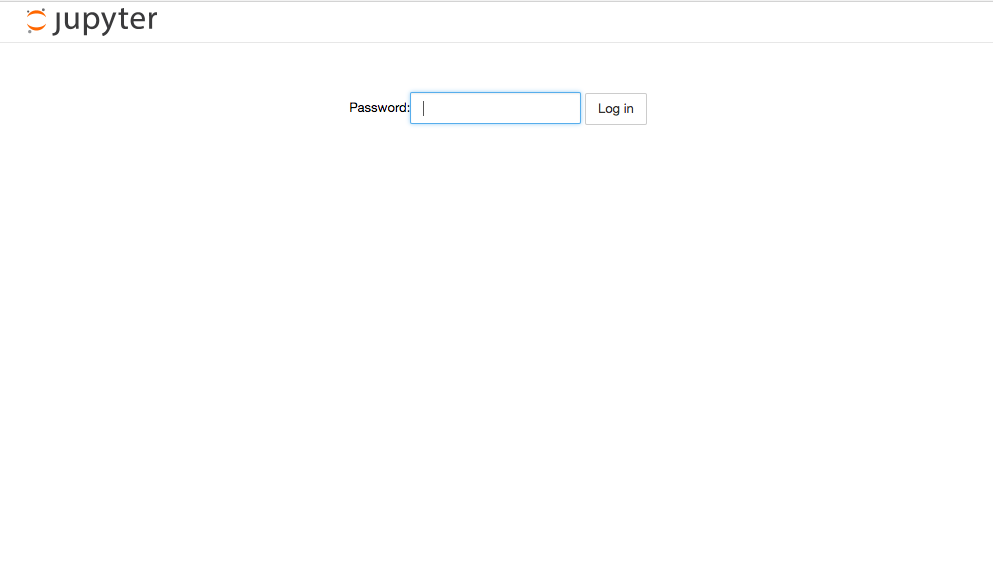
4 GCEとGCSを接続
GCS Fuseを使ってGCSバケットをファイルシステムとしてマウントする
インストール
$ export GCSFUSE_REPO=gcsfuse-`lsb_release -c -s`
$ echo "deb http://packages.cloud.google.com/apt $GCSFUSE_REPO main" | sudo tee /etc/apt/sources.list.d/gcsfuse.list
$ curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
$ sudo apt-get update
$ sudo apt-get install gcsfuse
アカウント認証をする
$ gcloud auth login

出てきたURLをクリックする
するとログイン画面が出てくるので、ログインする

すると認証コードが出てくるのでメモする。
そのコードをshellに入力すると認証が完了する
Google Cloud Storageでマウントするバケットを作る
左のサイドバーのStorageをクリック

バケットを作成

バケット名は任意の名前、クラスはRegionalで場所はGCSと同じ場所にする

他の設定はそのままで作成
マウント用のディレクトリを作成しマウントする
mkdir sample
gcsfuse バケット名 sample
5 Kaggle APIの導入
pip install kaggle でインストール
Kaggleにログインし、アカウントページからcreate API Tokenを作る

kaggle.jsonファイルがダウンロードされる
そのファイルを先ほどマウントしたGCRのバケットにアップロードする
取得したjsonファイルを~/.kaggle/kaggle.jsonに移動させる
# ファイルがあるディレクトリ
mv kaggle.json ~/.kaggle/kaggle.json
kaggle.jsonのパーミッションを600にする。以上で、kaggleコマンドが使えるようになります。
chmod 600 ~/.kaggle/kaggle.json
6 Kaggle データセットダウンロード
kaggle コマンド
kaggle -hと後ろに-hをつけてやると、次のようにhelpが表示されるので、helpを見ながら使えばそんなに困らない感じです。
| コマンド例 | 結果 |
|---|---|
| kaggle competitions list | コンペの一覧を取得 |
| kaggle competitions files -c titanic | タイタニックコンペのデータサイズ等を表示 |
| kaggle competitions download -c titanic | タイタニックコンペのデータをダウンロード |
| kaggle competitions submit -c titanic -f pred.csv -m test |
タイタニックコンペにpred.csvをサブミット。 メッセージはtest |
| kaggle competitions submissions -c titanic | タイタニックコンペの自分のサブミット一覧を表示 |
実際に kaggleのデータセットをダウンロードする(早い)
kaggle competitions download -c titanic
jupyter notebookなどで分析開始!
インスタンスを作るたびに環境を作るのが面倒になってくるので、Dockerで環境を構築する方法を取ると良い。