Node-RED上でWatson Discoveryを試す
IBM Cloud ライト・アカウントなどから、Watson Discovery ライトプランを用いてデータコレクションを作成(※)し、Node-REDから作成したデータコレクションに対して検索をかけるNode-REDフローのサンプルです。
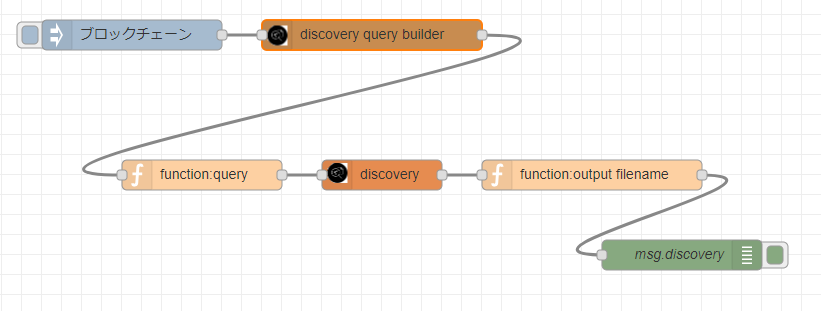
IBM Cloud上のNode-REDに付属するWatsonノードを用いて作成しています。入力のInjectノードで指定したキーワードを用いて、検索をかけ、最終的にファイル名を取得します。ローカルやIBM Cloud以外で稼働中のNode-REDの場合は、別途Watsonノードを追加する必要があります。
サンプル
下記コードをコピー&ペーストし、Node-REDの読み込みからクリップボード経由でインポートします。上図のようにフローが表示されます。各ノードにWatson Discoveryの「サービス資格情報」や作成したデータコレクションの「Environment_id」、「Collection id」やWatson Discoveryのサービス資格情報、データコレクション名などについて入力することで動きます。
[{"id":"576efd61.86f304","type":"tab","label":"Watson Discovery 検証","disabled":false,"info":""},{"id":"61db55a4.bff2ec","type":"inject","z":"576efd61.86f304","name":"","topic":"","payload":"ブロックチェーン","payloadType":"str","repeat":"","crontab":"","once":false,"x":150,"y":40,"wires":[["84aaa0ad.52b8d"]]},{"id":"319a2da9.e7a8d2","type":"watson-discovery-v1","z":"576efd61.86f304","name":"","environmentname":"","environment_id":"","collection_id":"","configurationname":"","configuration_id":"","collection_name":"","count":"10","passages":true,"nlp_query":true,"query":"","filter":"","aggregation":"","return":"","description":"","size":0,"discovery-method":"query","default-endpoint":true,"service-endpoint":"","x":400,"y":180,"wires":[["bac4ce26.097e1"]]},{"id":"febb5e69.336c4","type":"debug","z":"576efd61.86f304","name":"msg.discovery","active":true,"console":"false","complete":"payload","x":700,"y":260,"wires":[]},{"id":"84aaa0ad.52b8d","type":"watson-discovery-v1-query-builder","z":"576efd61.86f304","name":"","password":"gyclXRLCy4Cr","environment":"4d107fa6-ce06-44ca-8d87-6bf0689acdc2","environmenthidden":"4d107fa6-ce06-44ca-8d87-6bf0689acdc2","collection":"c57d3994-63c7-4e84-976b-5fe7c480cc16","collectionhidden":"c57d3994-63c7-4e84-976b-5fe7c480cc16","nlp_query":true,"nlp_queryhidden":"true","querynlp":"","querynlphidden":"","query1":"text","query1hidden":"text","queryvalue1":"","queryvalue1hidden":"","query2":"text","query2hidden":"text","queryvalue2":"","queryvalue2hidden":"","query3":"text","query3hidden":"text","queryvalue3":"","queryvalue3hidden":"","passages":false,"passageshidden":"false","default-endpoint":true,"service-endpoint":"https://gateway.watsonplatform.net/discovery/api","x":390,"y":40,"wires":[["3482f0a3.c03f9"]]},{"id":"3482f0a3.c03f9","type":"function","z":"576efd61.86f304","name":"function:query","func":"msg.discoveryparams = {};\nmsg.discoveryparams.environment_id = 'xxxxxxxx';\nmsg.discoveryparams.collection_id = 'xxxxxxxxx';\nmsg.discoveryparams.nlp_query = true;\nmsg.discoveryparams.query = msg.payload;\nreturn msg;","outputs":1,"noerr":0,"x":220,"y":180,"wires":[["319a2da9.e7a8d2"]]},{"id":"bac4ce26.097e1","type":"function","z":"576efd61.86f304","name":"function:output filename","func":"msg.payload = msg.search_results.results[0].extracted_metadata.filename;\nreturn msg;","outputs":1,"noerr":0,"x":610,"y":180,"wires":[["febb5e69.336c4"]]}]
各ノードの注意点
サンプルインポート後、各ノードの設定について、いくつか注意点があります。
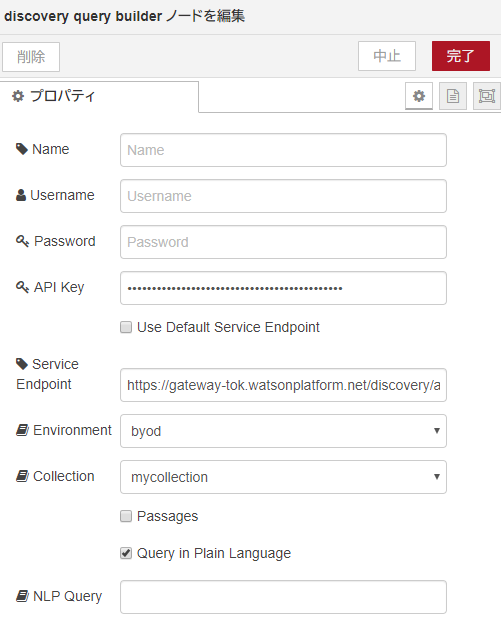
「discovery query builder」ノード
UsernameとPasswordは、Watson Discoveryのサービス資格情報で確認し、記述します。Environmentは、byod を選択し、Collectionは、作成したデータコレクションを指定します。
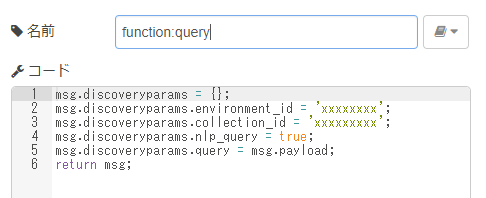
「function:query」ノード
作成したデータコレクションにて、「Use this collection in API」で確認した「Environment_id」、「Collection id」を記載します。入力のInjectノードで指定したキーワードを、クエリとして格納します。
「discovery」ノード
ノードの編集画面では、UsernameとPasswordは、Watson Discoveryのサービス資格情報で確認し、記述します。またMethod項目に「Search in collection」を指定しています。
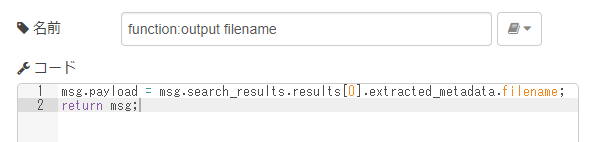
「function:output filename」ノード
「discovery」ノードから来たデータから、ファイル名だけを抽出する処理を行っています。
「msg.discovery」ノード
debugです。「function:output filename」ノードで抽出したファイル名をデバッグ結果としてNode-RED画面内で表示します。
出力結果をファイル名以外にしたい場合
取得したい値をファイル名ではなく、他の値にしたい場合は、「discovery」ノードに追加でdebugノードを追加し表示されたデバッグ結果をもとに、functionノードで抽出してください。
PostgreSQLをWatson Discoveryに接続する手順
既存のWatson Discoveryユーザーで、Watson Discovery Data Crawlerを使っていた方向けです。
基幹系システムやグループウェアなどでPostgreSQLを使用することが多いです。ビジネス向けのチャットボットやAIスピーカー、AI関係のアプリケーションで、利用者との対話の際に、洞察するための源泉としてWatson Discoveryを使用する場合、既存のデータベースとの連携は不可欠でしょう。
そこで、こちらにてPostgreSQLをWatson Discoveryに接続する手順についてまとめました。
SlideShare
https://www.slideshare.net/kolinz/postgresqlwatson-discovery
2019年8月現在、Watson Discovery Data Crawlerを新規に取得し、利用することはできませんのでご注意ください。
外部システム接続
データベース接続を行うWatson Discovery Data Crawlerを新規に取得し利用することができなくなったため、外部システム連携は、「Manage Data」画面で表示される「Connect a data source」で選択できる外部システムに接続してください。