概要
dynamodbにデータを入稿する際に、以下の問題が発生した。
- AWS ManagementConsole上からまとめてデータをインポートすることができない(1行ずつなら可能)
- 1行ずつやるとしても、jsonでの入稿になるので面倒くさい
- まとめてインポートする場合、S3との連携などが必要で面倒くさい
よって、ローカルのpythonを実行し、dynamodbテーブルの自動生成&データ入稿を出来るようにした。
前提条件
実行の際の条件として、以下が実行可能となっている必要がある。
- python3.xが実行可能なこと
- pipコマンドが実行可能なこと(pip3でも良い)
- aws cliが実行可能なこと
- aws credentialが設定されていること
実装
以下のコードは実装後、chatGPT4にコメントを追加&リファクタしてもらったものです。
partition keyはid(string)です。
変更したい場合は、KeySchemaを修正すると良いかと思います。
csvファイルの準備
インポートしたいcsvファイルを準備します。
以下はcharacters.csvとして、blue lockのキャラクターを一部抜き出したものです。
| id | last_name | first_name | sex | height | blood_type |
|---|---|---|---|---|---|
| 1 | 潔 | 世一 | 男 | 175 | B |
| 2 | 蜂楽 | 廻 | 男 | 176 | AB |
| 4 | 千切 | 豹馬 | 男 | 177 | A |
| 5 | 吉良 | 涼介 | 女 | 181 | O |
| 6 | 糸師 | 凛 | 男 | 186 | A |
ライブラリの追加
boto3及びpandasを使用するので、pip installで以下をインストールしてください。
通常python3をインストールすると、pip3 installなどを推奨されるかもしれませんが、このあたりは各々の環境によって置き換えてください。
pip install boto3
pip install pandas
コードの追加
以下を.pyファイルにコピペします。
実行結果上でのファイル名は、dynamo_data_importer.pyとしています。
import json
import boto3
import decimal
import pandas as pd
import sys
# DynamoDB のリソースを取得します
dynamodb = boto3.resource('dynamodb')
def ensure_table_exists(table_name):
"""指定されたテーブル名でDynamoDBテーブルを確認し、存在しなければ作成します。"""
try:
# テーブルがすでに存在するかを確認
table = dynamodb.Table(table_name)
table.load()
except dynamodb.meta.client.exceptions.ResourceNotFoundException:
# テーブルが存在しない場合、新たに作成
table = dynamodb.create_table(
TableName=table_name,
KeySchema=[{'AttributeName': 'id', 'KeyType': 'HASH'}],
AttributeDefinitions=[{'AttributeName': 'id', 'AttributeType': 'S'}],
ProvisionedThroughput={'ReadCapacityUnits': 1, 'WriteCapacityUnits': 1}
)
# テーブルの作成が完了するまで待機
table.wait_until_exists()
return table
def put_items_dynamodb(table_name, csv_path, json_path):
"""CSVファイルからデータを読み込み、それをJSON形式に変換した後、DynamoDBに挿入します。"""
csv_to_json(csv_path, json_path) # CSVをJSONに変換
put_items = convert_json_to_dict(json_path) # JSONを辞書に変換
table = ensure_table_exists(table_name) # テーブルの確認、必要に応じて作成
try:
with table.batch_writer() as batch:
for item in put_items:
print(item) # 挿入するアイテムを表示
batch.put_item(Item=item)
except Exception as e:
print(e)
def convert_json_to_dict(json_file_name):
"""JSONファイルを読み込み、DynamoDB用にデータを辞書形式で整形します。"""
with open(json_file_name) as json_file:
data = json.load(json_file, parse_float=decimal.Decimal)
for item in data:
item['id'] = str(item['id']) # idを文字列型に変換
return data
def csv_to_json(csv_path, json_path):
"""CSVファイルを読み込み、指定されたJSONファイルパスにJSON形式で保存します。"""
df = pd.read_csv(csv_path) # CSVファイルを読み込み
df['id'] = df['id'].astype(str) # id列を文字列に変換
df.to_json(json_path, orient='records', force_ascii=False, indent=4) # JSONとして保存
if __name__ == '__main__':
# コマンドライン引数の処理
if len(sys.argv) != 2:
print("Usage: python script.py <filename.csv>")
sys.exit(1)
csv_file_path = sys.argv[1] # CSVファイルのパス
table_name = csv_file_path.replace('.csv', '').replace('./', '') # ファイル名からテーブル名を生成
json_file_path = csv_file_path.replace('.csv', '.json') # JSONファイルのパスを生成
put_items_dynamodb(table_name, csv_file_path, json_file_path) # DynamoDBにデータを挿入
実行方法
上記のdynamo_data_importer.pyが保存されているディレクトリに移動し、以下のコマンドを実行します。
python dynamo_data_importer.py characters.csv
実行結果
-
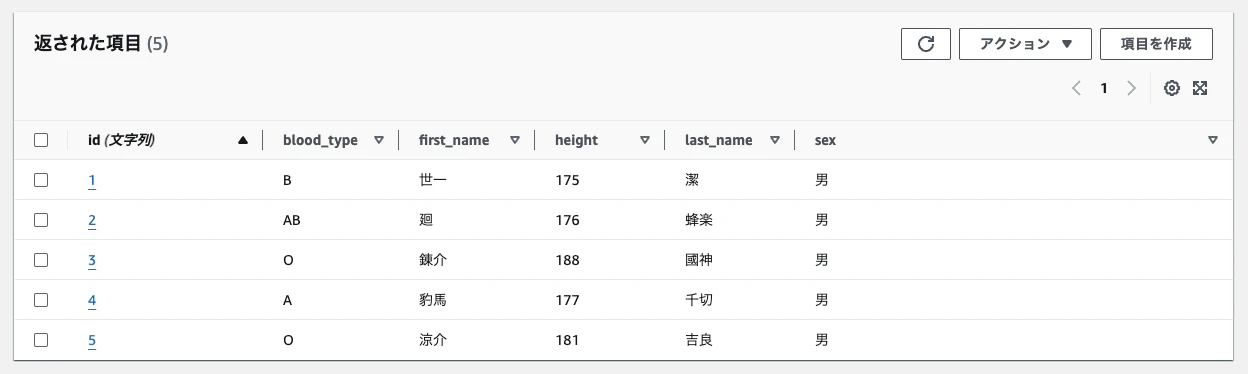
スクリプトの実行

-
確認結果
-
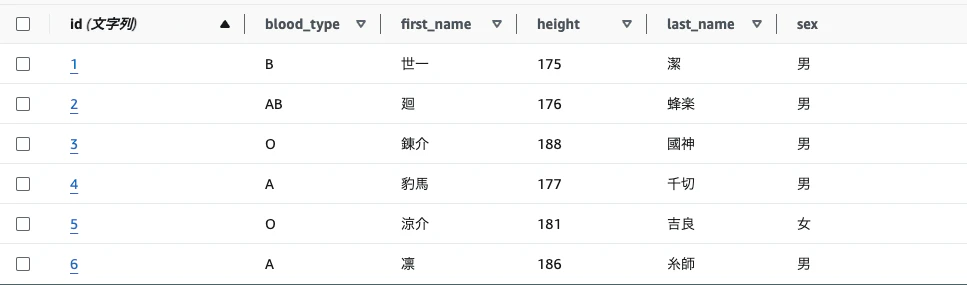
スクリプトの追加実行
データの変更&追加挿入の確認

-
確認結果
その他
csv上のデータ削除については対応していませんが、実行ごとにdynamodbのテーブル自体の削除&再作成を行うことで、簡単に対応可能です。
実装イメージ
import boto3
def delete_and_recreate_table(dynamodb, table_name):
table = dynamodb.Table(table_name)
table.delete() # テーブルを削除
table.wait_until_not_exists() # テーブルの削除が完了するまで待機
# テーブルを再作成(キー構成やその他の設定を指定)
new_table = dynamodb.create_table(
TableName=table_name,
KeySchema=[
{'AttributeName': 'id', 'KeyType': 'HASH'}
],
AttributeDefinitions=[
{'AttributeName': 'id', 'AttributeType': 'S'}
],
ProvisionedThroughput={'ReadCapacityUnits': 1, 'WriteCapacityUnits': 1}
)
new_table.wait_until_exists() # 新しいテーブルの作成が完了するまで待機
return new_table
一部データの削除は結構面倒くさい(前のデータと今回アップロードするデータ比較する必要がある)ので、上記の方法のほうが楽です。
ただし、テーブルの再作成は本番環境等では使えないので、あくまで開発のみの機能として使用する必要があります。
アプローチ方法は色々あるので、chatGPTにでも聞くと良いと思います。