Azure ML の Machine Learning Studio を使って、Kaggleの課題に挑戦してみた。
とりあえずSubmitするまで。
※Kaggleはデータ分析のコンペサイトで、与えられた課題(多くは所定のデータを使って何かを予測するもの)を各自任意の手法で解いて、精度を競う。
取り組む課題
今回選んだ課題はこちら。
データサイズが大きすぎず、カラム数も少ないので前処理が楽そうという理由で選んだ。
Restaurant Revenue Prediction
https://www.kaggle.com/c/restaurant-revenue-prediction
※上記のコンペはすでに終了済み。開催中のコンペについて情報を公開すると、Kaggleの利用規約に抵触するおそれがあるので、敢えて終了済みを選んでいる。
レストランの収益を予測する回帰モデルを作る。
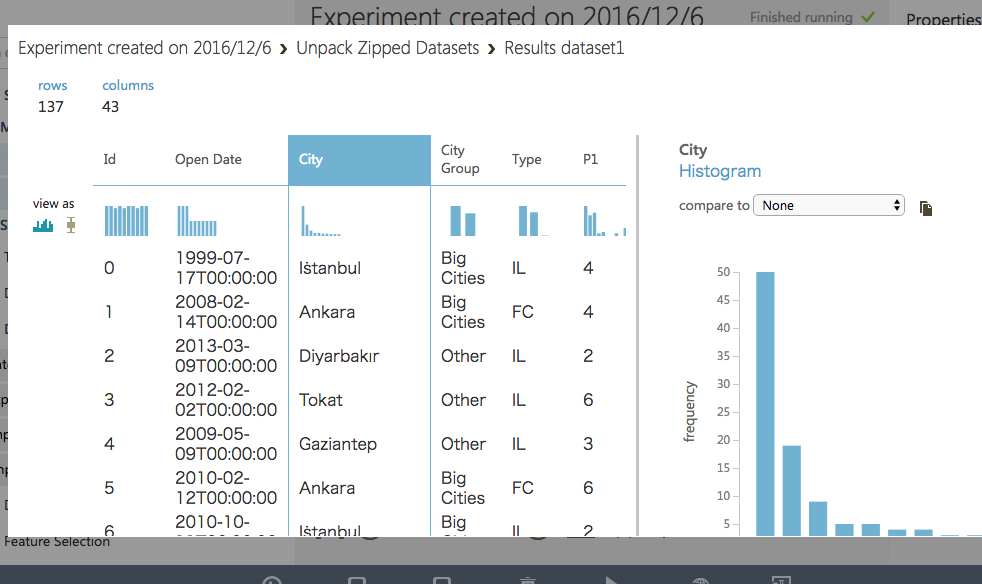
提供されているデータは、店ID、開店日、都市名、都市の区分、店の種類、の5項目に無名の37項目のデモグラフィック情報を加えた全42カラムのデータで、開店日(日付型)を除いてすべてカテゴリカル。
Id,Open Date,City,City Group,Type,P1,P2,P3,P4,P5,P6,P7,P8,P9,P10,P11,P12,P13,P14,P15,P16,P17,P18,P19,P20,P21,P22,P23,P24,P25,P26,P27,P28,P29,P30,P31,P32,P33,P34,P35,P36,P37,revenue
0,07/17/1999,İstanbul,Big Cities,IL,4,5.0,4.0,4.0,2,2,5,4,5,5,3,5,5.0,1,2,2,2,4,5,4,1,3,3,1,1,1.0,4.0,2.0,3.0,5,3,4,5,5,4,3,4,5653753.0
1,02/14/2008,Ankara,Big Cities,FC,4,5.0,4.0,4.0,1,2,5,5,5,5,1,5,5.0,0,0,0,0,0,3,2,1,3,2,0,0,0.0,0.0,3.0,3.0,0,0,0,0,0,0,0,0,6923131.0
2,03/09/2013,Diyarbakır,Other,IL,2,4.0,2.0,5.0,2,3,5,5,5,5,2,5,5.0,0,0,0,0,0,1,1,1,1,1,0,0,0.0,0.0,1.0,3.0,0,0,0,0,0,0,0,0,2055379.0
revenue列が目的変数で、店の収益を示している。
予測しなければならないテストデータが100000行あるのに対して、
学習データがわずか137行しかないので、過学習しにくいようなモデルにする必要がある。
準備
データセットのアップロード
Azure Machine Learning Studioの画面を開いたら、まず "DATASETS"を開く。
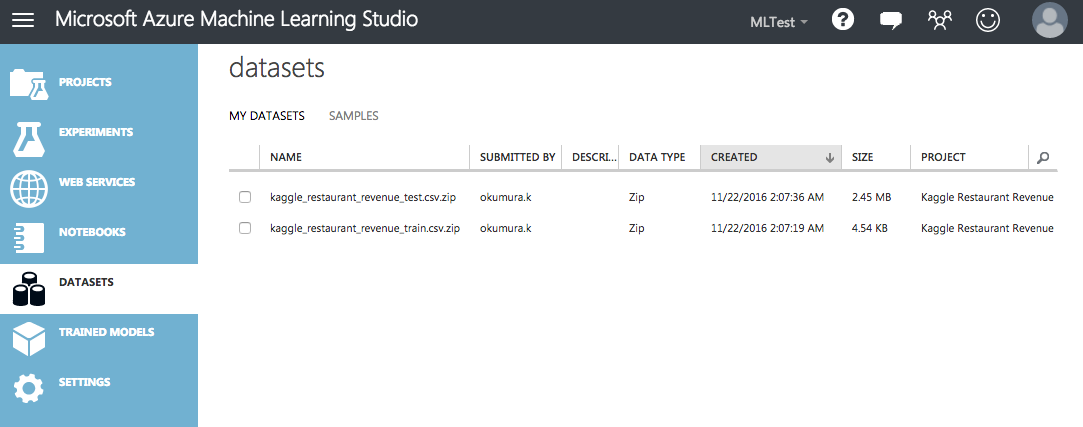
Kaggleのdataページからtrain.zipとtest.zipをダウンロードしたら、[ADD]->[FROM LOCAL FILE] を選択し、そのままアップロードする。(解凍する必要は無い。)
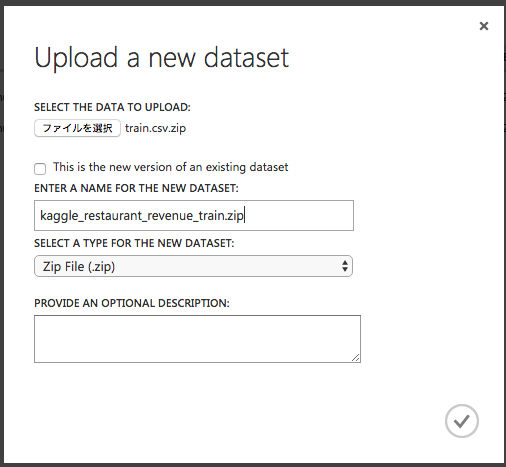
このとき、名前が"train.csv.zip"とかだと何のデータか分からなくなるので、適当に名前やDESCRIPTIONを入力しておくとよい。
Experimentの作成
"EXPERIMENTS" の "New"ボタンから空のExperimentを作成する。
"Saved Datasets" -> "My Datasets" に、先ほどアップロードしたデータセットが表示されるので、これを右のワークスペースにドラッグドロップする。
(My Datasetsに表示されない場合、プロジェクトに追加などの操作をする必要があるかも。)
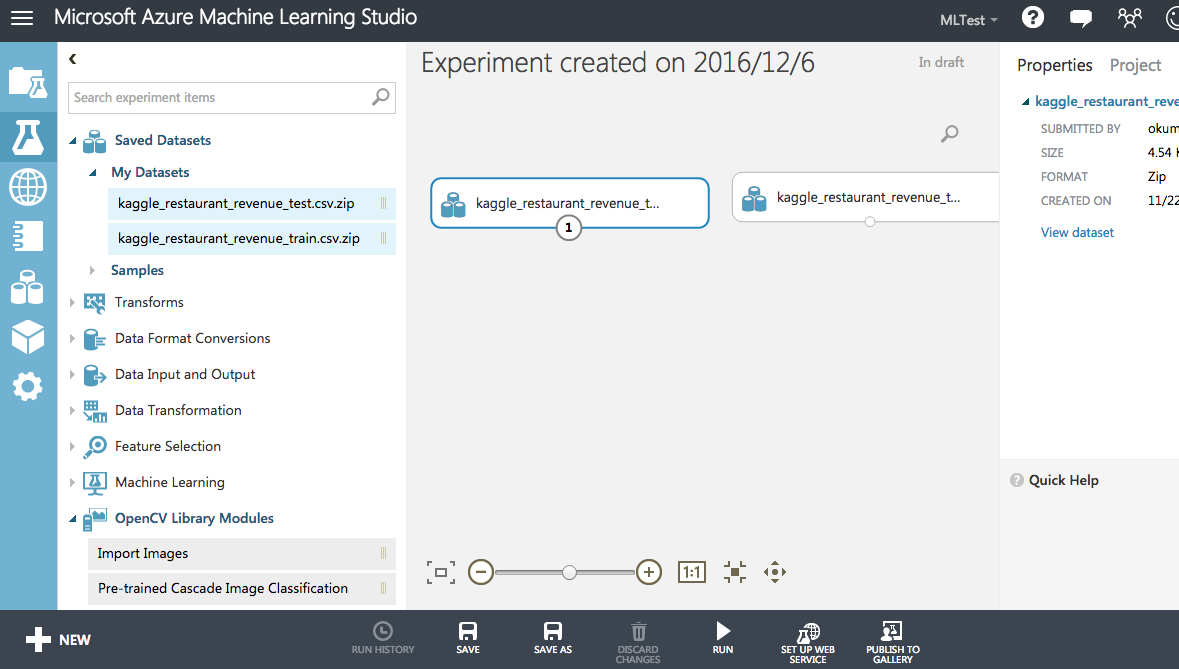
データの読み込み
ZIPファイルの読み込み
まずはファイルを読み込む仕組みを作る。
ZIPファイルを読むには"Unpack Zipped Datasets"を使う。
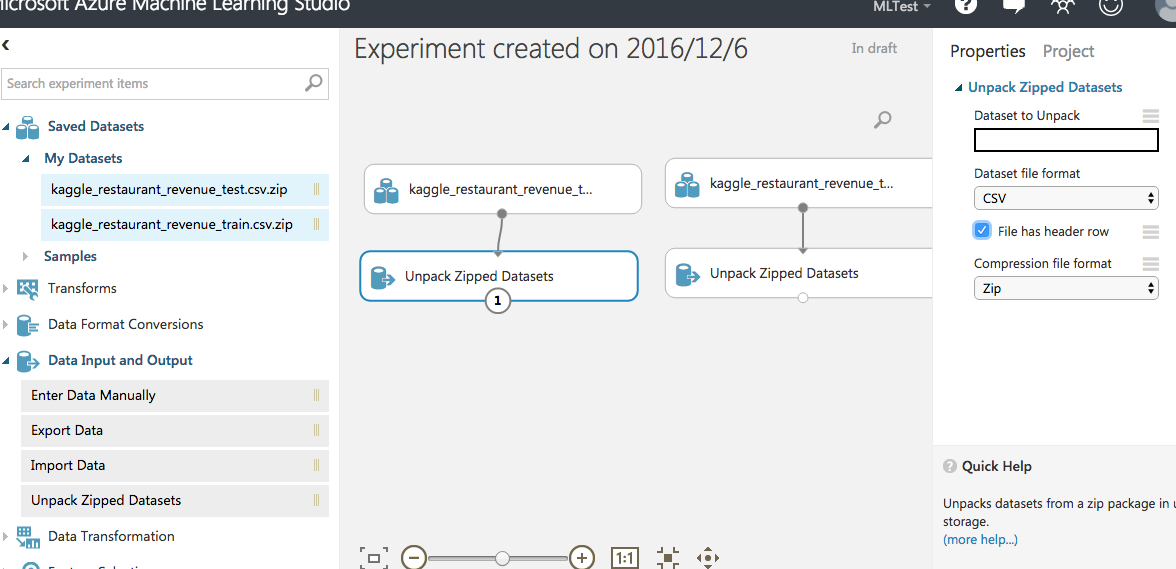
"Dataset to Unpack" オプションは、zipファイルの中身が単一ファイルの場合は空にしておけばよい。"File has header row"にチェック。
RUNしてから"Unpack Zipped Datasets"の出力をVisualizeしてみて、データを読めていることを確認。
train, testデータの連結
データの前処理の実装方法は人によって何通りかあると思うが、ここでは一旦trainデータとtestデータを縦に連結(SQLでいうUNION ALL)してまとめて前処理を適用したのちに、再度分割するという方針でやってみる。(こうすることで、確実に同じ前処理をtrain/testの両方に実施することができる。)
同じ列を持つふたつの表を連結するには、"ADD ROWS"を使う。
ただし、testデータには目的変数であるrevenue列が無くそのままでは連結できないので、Python Scriptを使ってtestデータにrevenue列を追加する。(値は固定で-1とする。)
※dataset名が見切れていて分かりづらいが、左側がtrain, 右側がtestデータ。
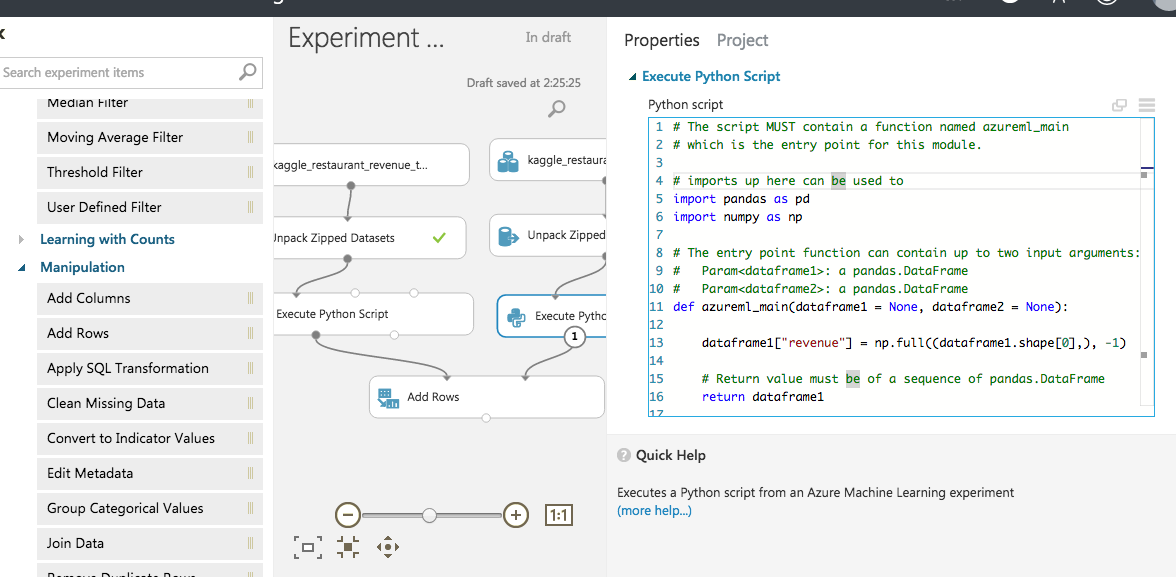
本来はtestデータ(右側)にだけPythonスクリプトを適用すればよいが、なぜかPythonスクリプトを通すとタイムスタンプ型の変数が整数型に変換されてしまって連結するときに不都合が発生したので、trainデータもPythonスクリプトを素通しして同じ条件にしている。
前処理
Idカラムを削除
Select Columns in Datasetを使う。
日付をyear, monthに分解
Pythonスクリプトを使う。
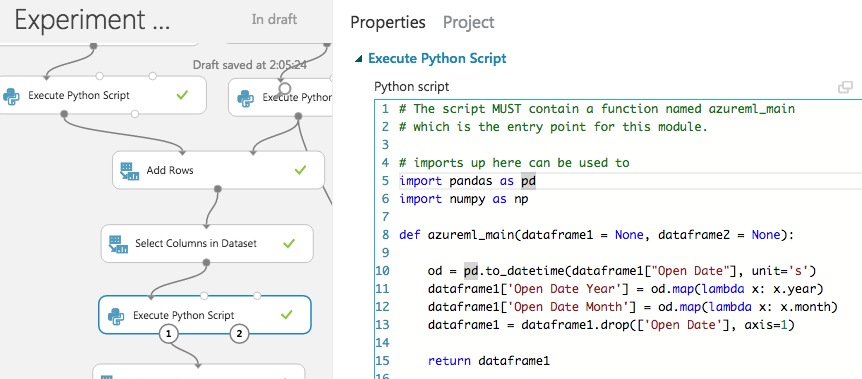
カラム型の設定
Azure MLには「Field」という概念があり、各カラムごとに、データ型、カテゴリカルかどうか、特徴量か正解ラベルか、といったメタデータを保持しており、適切に設定する必要がある。
これらのメタデータを設定するには、Edit Metadata を使用する。
※Pythonスクリプトを通すと前後でカラム型が変わってしまうことがあるので、必要な場合は通した後で再設定する。
revenue列を正解ラベルとしてマーク
まずはrevenueが正解ラベル(Label)であることを明示する。
こうすることで、学習アルゴリズムに入力したときに自動的に教師信号として使われる。
("Make Non-categorical"を選択しないと、数値型でもカテゴリカル扱いになってしまうことがあるので注意。)
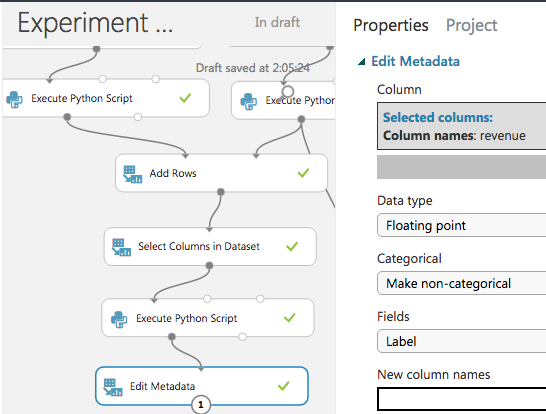
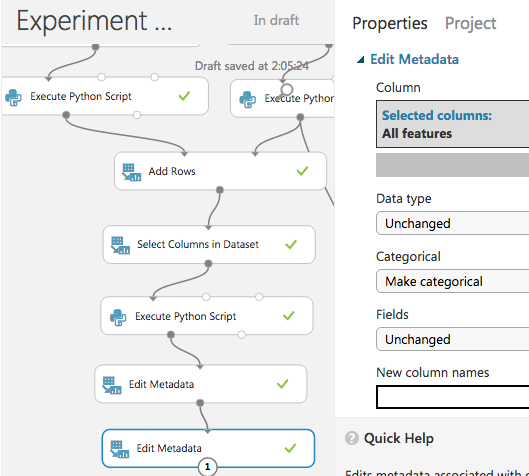
特徴量をカテゴリカル変数としてマーク
再びEdit Metadataで、特徴量のタイプをカテゴリカルに設定しておく。
今回はすべてカテゴリカル変数として扱い、連続値は存在しない。
(上で追加したyear,monthについてもカテゴリカルとなる。)
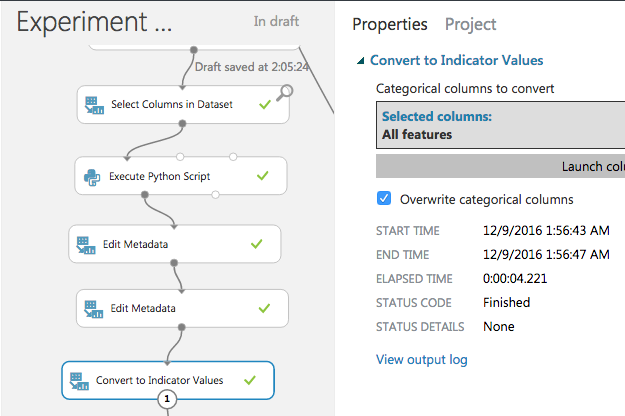
カテゴリカルな特徴量をダミー変数化する
カテゴリカルな変数を、0,1からなるスパースなベクトルに変換する。
ダミー変数とかOne-hot Encodingとか呼ばれるあれ。
Convert to Indicator Values を使う。
"Overwrite categorical columns"にチェックを入れると、変換元のカラムを上書き(削除)してくれる。
データをtrain/testに再分割する
前処理が完了したので、データをtrainとtestに分ける。
データを行単位で分割するには、Split Data を使う。
testデータセットには、さきほどrevenue=-1を代入したので、revenue>=0でフィルタすれば分割できる。
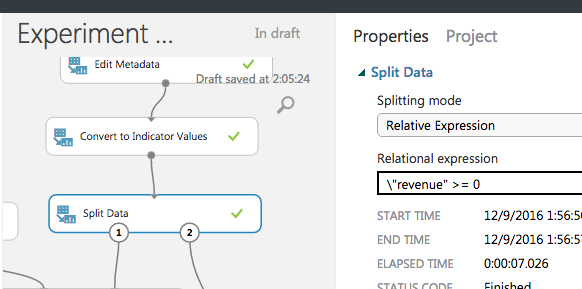
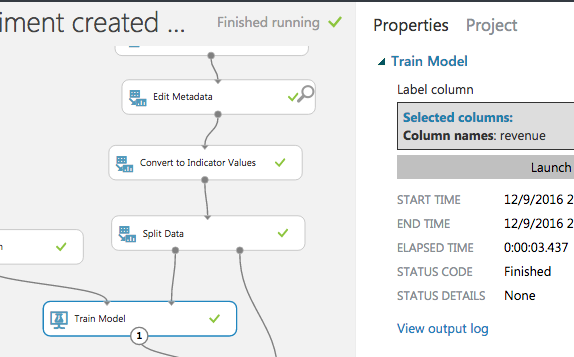
モデルを設定
学習データをTrain Modelに入力し、Label columnとして"revenue"を指定。
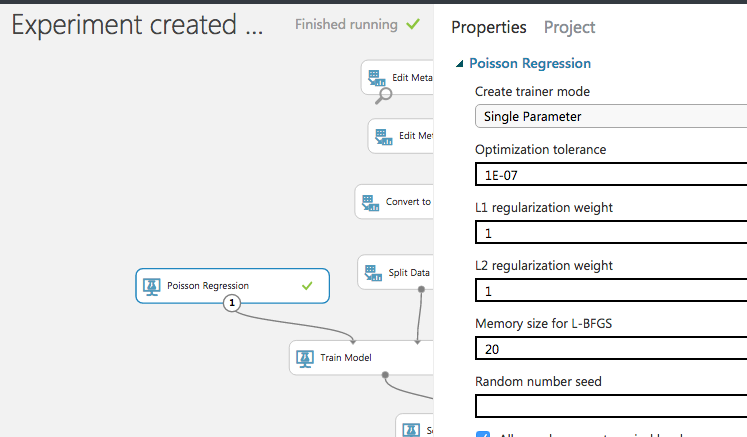
モデルは、とりあえずPoisson Regression(ポワソン回帰)を使ってみる。(目的変数が非負なので。)
パラメータはデフォルト。
L1,L2正則化が均等にかかる設定になっている。
Submitデータを作る設定
学習したモデルを使ってテストデータに対して予測を行い、submit用のデータを作る。
所定のsubmitデータ形式は
id,Prediction
1,9999
2,8888
のようにIDと予測収益が並んだCSVファイルである。(ヘッダ行も必要)
まずScore Modelを使ってテストデータに対する予測値を求める。
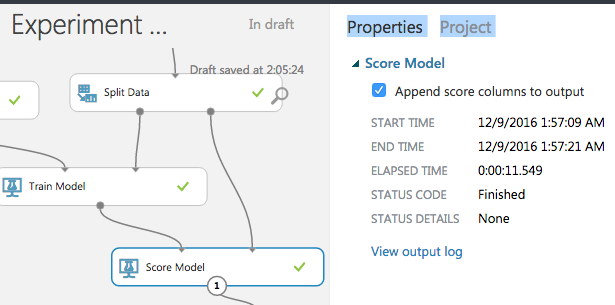
こうすることで、テストデータの右端に予測値の列"Scored Labels"が追加されるので、これを取り出せばよい。
さて、submitデータに必要なIdの列だが、学習の邪魔なので先ほど削除してしまった。
ので、削除前のデータセットから分岐して持ってきて、Select Columns in Dataset でId列だけを取り出す。
これらを Add Rows で横に結合すれば、出力したい形式の表ができる。
※IDが左、予測値が右に来てくるように左右を入れ替えて接続している。
最後に、カラム名 "Scored Labels" を "Prediction" に変えてから、CSV形式で出力。
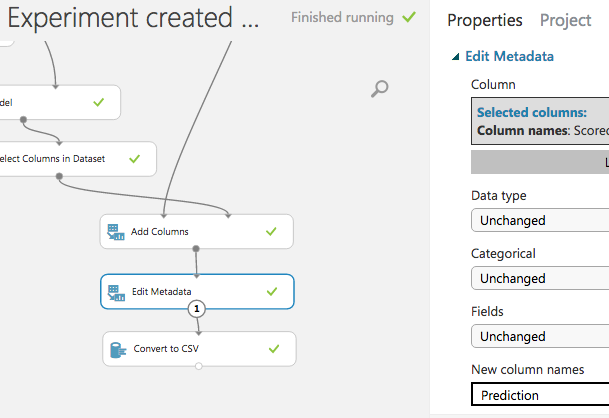
完成図
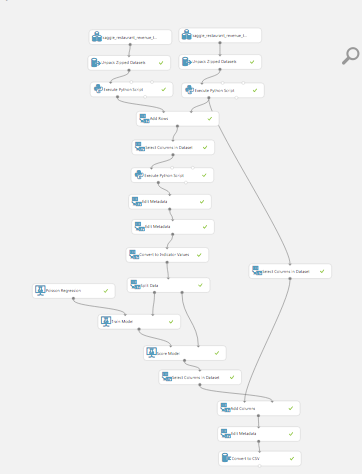
最終的にできたフローはこのようになった。
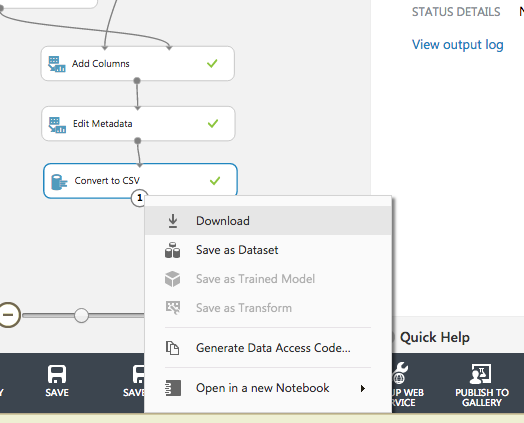
実行、結果のダウンロード
"RUN"をクリックして実行する。
うまくいけば、最後の "Convert to CSV" に緑色のチェックマークが付くので、右クリックからCSVファイルをダウンロードする。
$ head "Experiment created on 2016_12_6 - 506153734175476c4f62416c57734963.faa6ba63383c4086ba587abf26b85814.v1-default-1643 - Results dataset.csv"
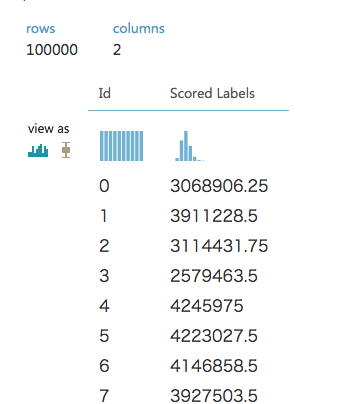
Id,Prediction
0,3068906.25
1,3911228.5
2,3114431.75
ファイル名が長ったらしいが、一応所定の形式で出力できているのが分かる。
Submit
submitしてみる。
(Kaggleでは、終了したコンペでも、submitすれば評価はしてくれて、順位の目安を教えてくれる)
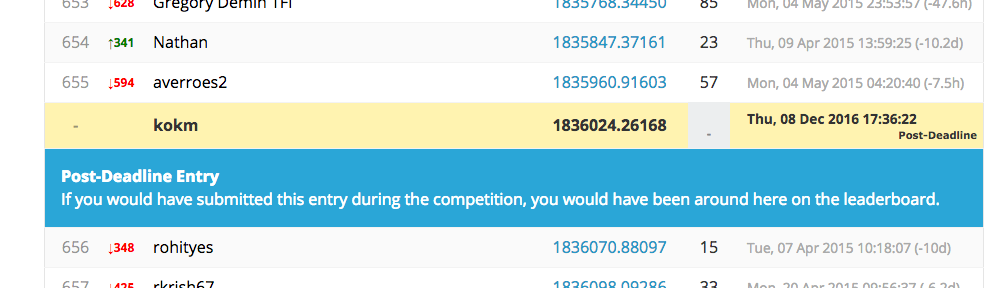
RMSEスコア1836024.26168
2257人中の650位くらいなのでまずまず?
重みの表示
Train Model の出力をVisualizeすれば、モデルの情報(推定されたパラメータの重みなど)を見ることができる。
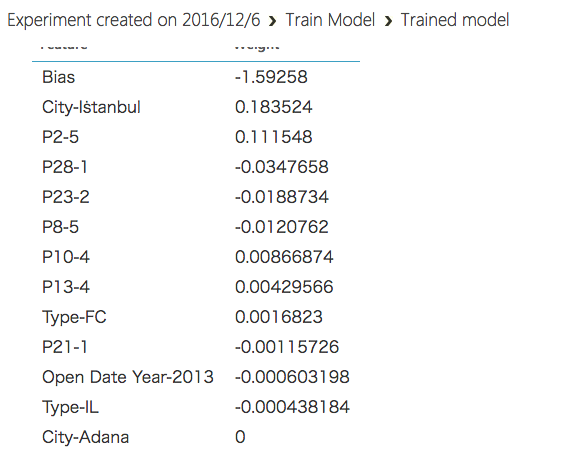
イスタンブールの店は儲かることなどが分かる。
今回の設定ではL1正則化が強く効いたためか、11個の特徴量だけに重みが振られ、残りは0となった。
このあたりのパラメータを調整すれば、同じ特徴量でももう少し上位を狙えるかもしれない。
おわり。