はじめに
盛大にハマって、4, 5時間+α(やる気がなくなって進まなかった時間)を溶かしたので、自戒の念も込めて書きます。
ほとんどkaggleは関係なく、pythonのリストのidに関する記事かと思います。
見事なハマりポイントのあったチュートリアルは、下のリンクから飛べます。
[Titanic Data Science Solutions | Kaggle](https://www.kaggle.com/startupsci/titanic-data-science-solutions
本題
データ前処理のコード
このチュートリアルの中では、trainデータとtestデータをリストにまとめることで、データの前処理を楽に行えるようにしています。
import pandas as pd
train_df = pd.read_csv('../input/train.csv')
test_df = pd.read_csv('../input/test.csv')
combine = [train_df, test_df]
combineという名前のリストにまとめて処理を行います。
例えば、train_dfとtest_dfのそれぞれのNameカラムから、敬称(Mr, Ms, Mrs, Dr)などを抽出し、Titleという新しいカラムを作るのは、下のコードで実現できます。
(わかりやすいように、元のコードを書き直してあります)
for dataset in combine:
dataset['Title'] = dataset["Name"].str.extract(' ([A-Za-z]+)\.', expand=False)
train_dfとtest_dfは書き換わり、Titleカラムが作られます。
謎の再代入
こんなコードがありました。
train_df = train_df.drop(['Ticket', 'Cabin'], axis=1)
test_df = test_df.drop(['Ticket', 'Cabin'], axis=1)
combine = [train_df, test_df]
train_dfとtest_dfのTicket及びCabinカラムを削除するコードです。
しかし、3行目のcombine = [train_df, test_df]をまたやってる意味がわかりませんでした。
「さっきcombineに代入してたやないか!」と。
そして、データフレームをまとめて処理するならこのほうがいいだろうと、下のコードを書いたわけです。
for dataset in combine:
dataset = dataset.drop(['Ticket', 'Cabin'], axis=1)
削除されないカラム、合わない列数
コードを実行してtrain_dfとtest_dfの中身を確認しても、TicketとCabinカラムが消えてないんですよ。
だから、学習に進もうにも挙動が少し違っていました。
でも原因は特定できず。
原因
このkaggleのチュートリアルはjupyter notebookで提供されていました。
なので、元のコードを動かして原因を特定しようと思い実行。
大幅に違うコードはやっぱり、dropする部分でした。
dropは、特定の行または列を落としたデータフレームを返すメソッドです。
dropメソッドを実行しただけでは消えないので、代入することで、元のデータフレームを置き換えます。
train_df = train_df.drop( 条件など )
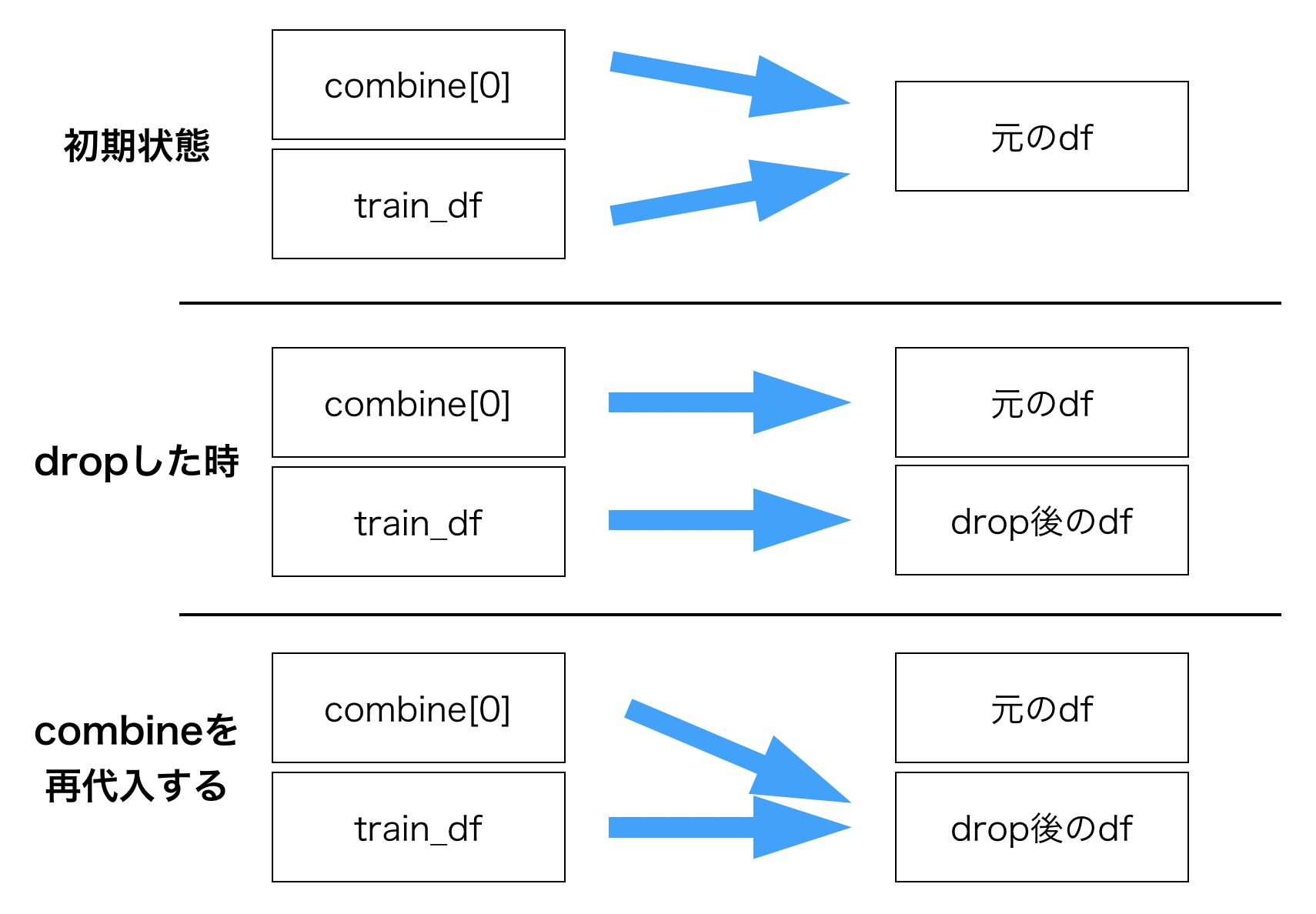
ここで、再代入が発生することになるわけです。再代入するということは、つまりオブジェクトが変わるということ。
dropする前とした後のtrain_dfでは、idが変わっているわけです。
print(id(train_df)) # 4705601968
train_df = train_df.drop("Age", axis=1)
print(id(train_df)) # 4706557120
なので、dropメソッドを使って代入した後では、それを指すcombine変数もcombine = [train_df, test_df]で再代入する必要があるわけです。
「正しいdrop」
train_df = train_df.drop(['Ticket', 'Cabin'], axis=1)
test_df = test_df.drop(['Ticket', 'Cabin'], axis=1)
combine = [train_df, test_df]
for文を使ったdropがいけないわけ
for dataset in combine:
dataset = dataset.drop(['Ticket', 'Cabin'], axis=1)
このコードがうまく動作しなかった理由は単純でした。
datasetという変数には、combineの中身(train_df, test_df)が順番に渡されます。
そのdatasetという変数にdropしたデータフレームを渡しても、元のtrain_dfにはなんの影響も与えません。
C++の範囲for文の動作とpythonのfor文の動作がごちゃごちゃになっていました。
まとめ
pythonのリスト関係で動作がおかしくなったとき、オブジェクトのidが関係することが多くあります。
今回、pandasのデータフレームがリストの要素に入っていたこともあり、原因がわかりにくくなっておりました。
今後も精進したいと思います。