この記事は一休.com Advent Calenrad 2017の11日目です。
データサイエンス部小島です。
現在はレコメンドまわりを担当しています。
試験的に導入予定のETLツールAirflowについて書こうと思います。
Airflowについて
一言でいうと、高機能なcronです。
Pythonでかけて、タスクごとの依存関係を定義できます。
元々はAirbnbが独自で開発し、今はApacheのIncubetorのプロジェクトになっています。
一休のデータフローを考えてみる
一休ではセッションごとの情報を集約してまとめています。
そのデータをDWHに加工するまでの流れをまとめると以下のようになります。

上記のデータ処理を日次で行うようなものをAirflowで実装していきたいと思います。
環境の構築
今回は簡単にgithubに環境を公開してくれている方のをおかりしてセットアップしていきます。
https://github.com/puckel/docker-airflow
$ git clone git@github.com:puckel/docker-airflow.git
$ cd docker-airflow/
$ docker-compose -f docker-compose-CeleryExecutor.yml up -d
AirflowにはExecutorというものがあって、
使用するExecutorによって処理の方法が並列になるのか直列にするかを選ぶことができます。
今回はCeleryを使用したExecutorを選択しています。
上記のコマンドだけで以下にアクセスすることができます。
Airflow管理画面: localhost:8080
Flower: localhost:5555

実装
まずは個別の処理を書きます。
例として1日分のホテル情報をDBから取得してきてCSVに保存する処理を書いています。
import pandas
import datetime
from jinja2 import Template
def make_hotel_table(**kwargs):
# データ取得するsqlの実行
#実行日時の取得
execution_date = kwargs.get('execution_date').date()
prev_execution_date = execution_date - datetime.timedelta(days=1)
with open("make_hotel_table.sql", 'r') as f:
sql = " ".join(f.readlines())
sql = Template(sql).render(date_from=prev_execution_date, date_to=execution_date)
conn = pymssql.connect(server='test', port='test', user='test', password='test')
data = pd.read_sql_query(sql, conn)
data.to_csv('hotel_table.csv')
return True
こんな感じで個別の処理を全て記述できたら
あとは全体のスケジュール設定とタスクの定義、依存関係を記述するだけでOKです。
from airflow import DAG
from airflow.operators import PythonOperator
from datetime import datetime, timedelta
from func import *
default_args = {
'owner': 'ikyu',
# いつからデータをためるかを定義
'start_date': datetime(2017, 10, 1),
}
dag = DAG(
'ikyu_etl', default_args=default_args, schedule_interval='@daily') # いつ実行するかを定義
make_hotel_table = PythonOperator(
task_id='make_hotel_table',
provide_context=True,
python_callable=make_hotel_table,
dag=dag
)
make_booking_table = PythonOperator(
task_id='make_booking_table',
provide_context=True,
python_callable=make_booking_table,
dag=dag
)
make_user_table = PythonOperator(
task_id='make_user_table',
provide_context=True,
python_callable=make_user_table,
dag=dag
)
make_access_log = PythonOperator(
task_id='make_access_log',
provide_context=True,
python_callable=make_access_log,
dag=dag
)
combine_hotel_booking = PythonOperator(
task_id='combine_hotel_booking',
provide_context=True,
python_callable=combine_hotel_booking,
dag=dag
)
masking = PythonOperator(
task_id='masking',
provide_context=True,
python_callable=masking,
dag=dag
)
put_to_bigquery = PythonOperator(
task_id='put_to_bigquery',
provide_context=True,
python_callable=put_to_bigquery,
dag=dag
)
make_session_data = PythonOperator(
task_id='make_session_data',
provide_context=True,
python_callable=make_session_data,
dag=dag
)
combine_session_user = PythonOperator(
task_id='combine_session_user',
provide_context=True,
python_callable=combine_session_user,
dag=dag
)
combine_all_data = PythonOperator(
task_id='combine_all_data',
provide_context=True,
python_callable=combine_all_data,
dag=dag
)
append_to_dwh = PythonOperator(
task_id='append_to_dwh',
provide_context=True,
python_callable=append_to_dwh,
dag=dag
)
# 異存関係の定義
make_hotel_table.set_downstream(combine_hotel_booking)
make_booking_table.set_downstream(combine_hotel_booking)
make_user_table.set_downstream(masking)
make_access_log.set_downstream(put_to_bigquery)
put_to_bigquery.set_downstream(make_session_data)
masking.set_downstream(combine_session_user)
make_session_data.set_downstream(combine_session_user)
combine_hotel_booking.set_downstream(combine_all_data)
combine_session_user.set_downstream(combine_all_data)
combine_all_data.set_downstream(append_to_dwh)
結果Airflowの管理画面では以下のようになります。
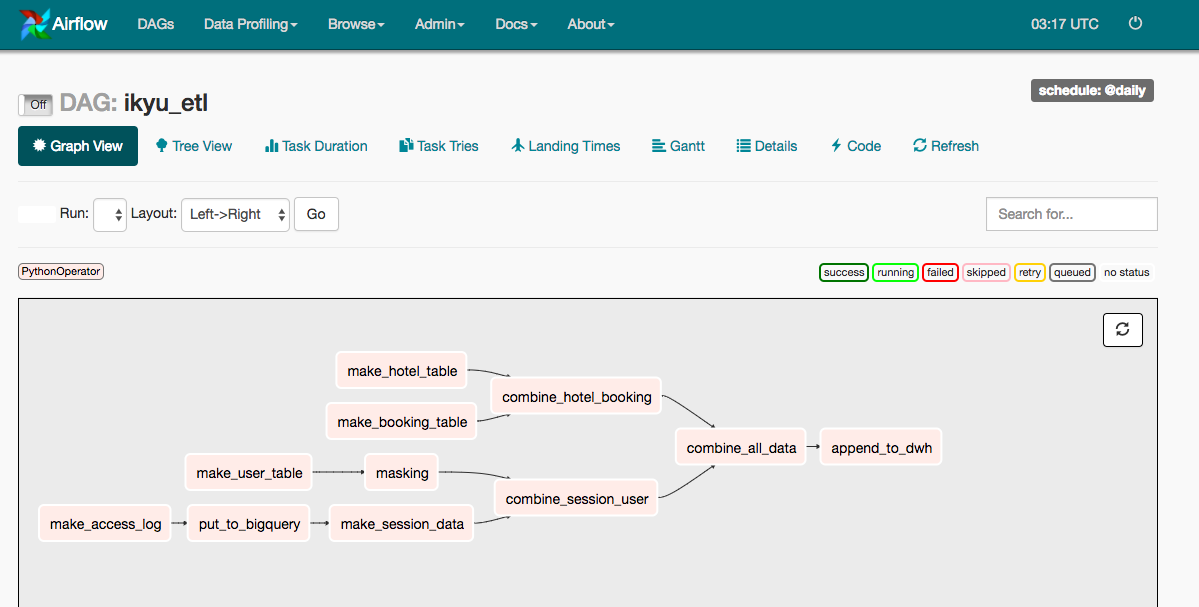
うまく依存関係者が定義できたかと思います。
実際に実行してみる
スケジュール実行はすごく簡単でDAGの横のOn Offスイッチをクリックすればいけます。
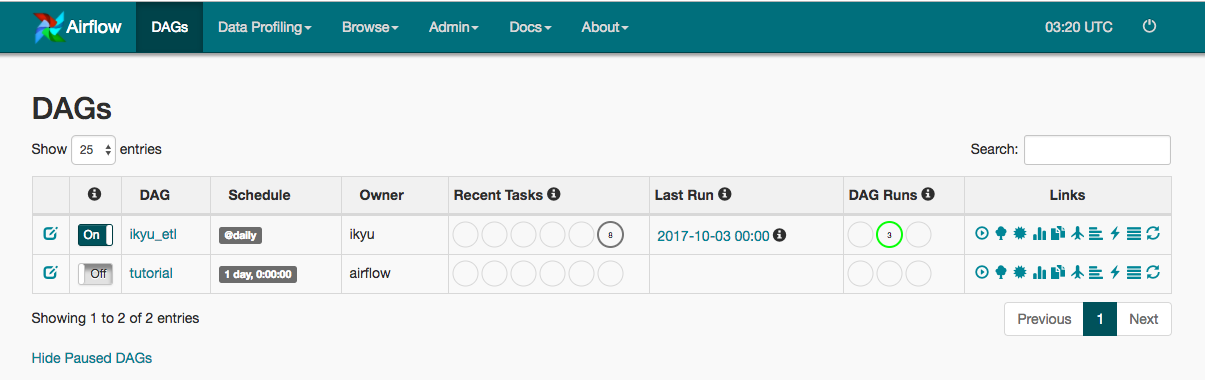
今回はDAG自体のスタート日時を2017/10/01に設定しました。
データフローの考え方として、
- いつからデータをためるか => データ挿入が始まる日
- いつ実行するか => スケジュールインターバル(1日一回, 1時間に一階など)
の2点は別々で考える必要があります。
Airflowはデータ挿入が始まる日から今日(12/11)までの間に
スケジュールインターバルで設定された実行可能なタスクを全て処理していきます。
なのでスケジュールをOnにすると、
2017/10/1から今日までdailyで実行可能なタスクを処理してくれます。
Tree Viewを観ると実際にそのようになっていることが確認できます。

こんな感じでAirflowを実行してみました!
おわりに
なんか書いてるとAirflowのツールの紹介みたいになってしまいましたが、
今後はこれを使ってETL周りとかレコメンドの処理フローとかを実装していけたらと考えています。
明日は @japboyさんによる「Web Components FTW」です。