はじめに
これからのクリスマス、年末年始、大切な人と過ごす時間。
そんな雰囲気を破壊するゲリラ的思考「あれ、この人の名前が出てこない...!」
この窮地を救うサービス(ではないかもですが)Amazon Rekognitionを勉強のために使ってみました。
また、最近触れる機会のあったCICDツールであるJenkinsも絡ませました。
Amazon Rekognitionでできること
初めに、Amazon Rekognitionとは何か、AWSのdocs(デベロッパーガイド)の内容をまとめます。
簡単に抜粋すると、Amazon Rekognitionでは以下のことができます。
・学習済みのAIを使って画像や動画を分析できます。
・物体を認識し、ラベル付けしてくれます。
・顔を検出して表情や他の顔との類似度がわかります。
・有名人の顔を検出できるように、事前にトレーニングされた方法があります。
・不適切なコンテンツを検出できます。
・テキストを検出できます。
※AWSコンソール上ではAmazon Rekognitionのデモが、サンプルデータ付きで用意されており、すぐに動かすことができるようになっています。
他にもいろいろ書かれていますが、今回は画像内の情報を読み取り、あれこれします。
Amazon Rekognitionで「名前を知る」方法を考える
さて、今回のやりたいことはAmazon Rekognitionで顔を検出し、その人の名前を出力することです。
まず、Amazon Rekognitionのdocsから参考になる記述をピックアップします。
・画像から知っている顔を検出するには...
Amazon Rekognitionでは顔の類似度を出してくれる方法が用意されています。
また、顔の情報はAWSのサーバーにコレクションとして保存でき、類似度を求めるときに利用できます。
・顔から名前を出すには...
顔の類似度を求めたら、顔の名前をどこかから持ってくる必要があります。
方法はいろいろと考えられると思いますが、今回はAmazon Rekognitionでクライアント側で指定できるIDであるExternalImageIdを使います。
このIDをAWS上のコレクションに保存する顔情報に紐づけます。
・Amazon RekognitionのAPIへ画像を入力するには...
Amazon Rekognitionを使うには、用意されているAPIを使うことになります。
APIへ画像を渡す方法ですが、S3に保存されているものを使う方法と、ローカルにある画像を送る方法があります。
docsにはS3の方法が載っていたのでこの記事ではローカルの方法でやります。
※Jenkinsについては、コードを実行するために使いますが、メインはAmazon Rekognitionのため、説明は省きます。
作業するための環境を構築する
実際の作業についてまとめていきます。
初めにAmazon RekognitionのAPIを使うための環境を作ります。
1.EC2の作成
CloudFormationでEC2を作って作業します。Jenkinsの要件からt2.microでもかろうじて動きます。
CloudFormationの書き方は過去の記事を参考にしました。
EC2のインスタンスタイプはJenkinsが動くt2.microを選択しました。
Jenkinsの要件は以下のページで確認できます。
2.Jenkinsの構築
次にEC2でJenkinsを使えるようにします。
まず、Jenkinsで必要なJavaをインストールします。
以下の記事を参考にしました。詳しい手順は書いてあるので、気を付けた点を書いていきます。
インストールの際は以下の点に注意しました。
・Jenkinsのデフォルトの設定ではJavaのパスが/usr/bin/javaであることが必要
・Jenkinsを実行するユーザーであるjenkinsがJavaを実行できることが必要
コマンドは以下の通りです。
mkdir -p $HOME/java-tmp/jdk
wget https://download.java.net/java/GA/jdk11/9/GPL/openjdk-11.0.2_linux-x64_bin.tar.gz -O $HOME/java-tmp/jdk-pkg
tar xzvf $HOME/java-tmp/jdk-pkg -C $HOME/java-tmp/jdk
sudo cp -r $HOME/java-tmp/jdk/`ls $HOME/java-tmp/jdk/` /usr/bin
sudo ln -s /usr/bin/`ls $HOME/java-tmp/jdk/`/bin/java /usr/bin/java
export JAVA_HOME=/usr/bin/java
export PATH=$PATH:$JAVA_HOME/bin
echo '
export JAVA_HOME=/usr/bin/java
export PATH=$PATH:$JAVA_HOME/bin
' >> $HOME/.bashrc
yes | rm -r $HOME/java-tmp
Javaがインストールできたら、他のパッケージとJenkinsをインストールして起動します。
Amazon Linuxのリポジトリの場合のインストールのコマンドを記載します。
sudo amazon-linux-extras install -y epel
sudo yum-config-manager --enable epel
sudo yum install -y fontconfig
sudo wget -O /etc/yum.repos.d/jenkins.repo https://pkg.jenkins.io/redhat-stable/jenkins.repo
sudo rpm --import https://pkg.jenkins.io/redhat-stable/jenkins.io.key
sudo yum install -y jenkins
sudo systemctl start jenkins
sudo systemctl enable jenkins
コマンド実行後は、ブラウザからアクセスできるようになるので、アクセスして初期設定を行います。
今回は初期設定で勧められるプラグインをインストールしています。
3.Amazon RekognitionのSDKのセットアップ
Amazon RekognitionのAPIが使えるようにします。この記事ではPythonを使います。
セットアップはコードを実行していくことになりますが、ユーザーのホームディレクトリを使うので、ユーザーjenkinsで作業します。
Jenkinsのブラウザからコードを実行すると、デフォルトではユーザーjenkinsが実行するので、ブラウザで作業します。
まず、Jenkinsでシェルを実行できるジョブを作成します。
ログイン後の画面の「新規ジョブ作成」からジョブ名を入力し、「フリースタイル・プロジェクトのビルド」を選択します。

作成後はジョブの設定画面に移動して、「ビルド手順の追加」から「シェルの実行」を追加します。
追加後に出る入力欄にshellを書いていきます。
shellの内容は以下の通りです。
まず、Jenkinsのデフォルトの設定になりますが、bashのオプションは以下のようになっています。
# !/bin/bash -xe
xeオプションで、実行するコマンドがログに出て、エラーで処理が中断するようになります。
入力欄の初めに上記のコードを書くことで、別のオプションを指定することが可能です。
AWSのconfigとcredentialの設定をします。
Jenkinsで実行すると、shell上でのユーザーの入力やttyを使った処理ができなくなるので注意します。
mkdir -p $HOME/.aws
echo "
[default]
output = アウトプット形式
region = リージョン
" > $HOME/.aws/config
echo "
[default]
aws_access_key_id = アクセスキーID
aws_secret_access_key = シークレットアクセスキー
" > $HOME/.aws/credentials
アクセスキーIDとシークレットアクセスキーの作成方法は以下のページで説明されています。
Amazon RekognitionのPython用のSDKをインストールします。
python3 -m pip install boto3
shellを書いたら、ジョブの設定画面から「ビルド実行」をクリックするとshellを実行できます。
※参考
顔から名前を出すコードを書く
処理のフローチャート
顔から名前を出すコードを書きます。
Jenkinsで色々な処理を一連の処理として実行するジョブを作成します。
今回の流れは以下のフローチャートのようにします。
画像内の顔を検出して、コレクション内を検索し、登録されていなければ登録するといった感じです。

1.画像内の顔をすべて検出するコード
Amazon RekognitionのAPIを使って画像内の顔を検出します。
docsでは以下のページにAPIのサンプルが載っています。
PythonのAPIについてより詳しい仕様は以下のページにあります。
また、Jenkinsのジョブに記載するのはshellなので、shellからPythonを呼び出すコードが別途必要です。
APIへの画像の入力について、今回はローカルの画像を使います。
以下にローカルの画像を入力として、顔を検出するAPIを呼び出すコードを示します。
import boto3
client=boto3.client("rekognition")
with open(画像ファイル, "rb") as image:
response = client.detect_faces(
Image={"Bytes": image.read()},
Attributes=["ALL"]
)
コード中のresponseには検出された複数の顔情報が入っています。
以下のように、本当に顔であるかの信頼度が低いものは、境界値を設けてresponseから省きました。
for label in response["FaceDetails"]:
if label["Confidence"] < 信頼度の境界値:
response["FaceDetails"].remove(label)
responseの値は他のジョブから使えるようにJSON形式でファイルに保存しておきます。
import json
with open(出力ファイル, "w") as f:
f.write(json.dumps(response))
2.画像内のすべての顔を切り取るコード
顔が検出出来たら、その顔がコレクションに登録されているのかを検索するのですが、その前にやることがあります。
コレクション内の顔と比較できる顔は1つまでです。検索にかける画像から複数の顔が検出されても、1度に比較できるのは1つまでとなります。
そのため、今回は画像内の顔を切り取り、1枚の画像につき顔が1つのみとなるようにします。切り取り後にできた画像それぞれについて、コレクション内の検索を行います。
まず、画像の切り取りはPythonパッケージであるPILを使うのでパッケージをインストールします。
python3 -m pip install pillow
切り取るためのコードは以下の通りです。
画像内の顔の場所は、顔の検出時にわかるBoundingBoxの値を使います。
BoundingBoxの説明は以下のページにあります。
以下に画像から顔の部分を切り取るコードを示します。
from PIL import Image
# 画像の読み込み
img = Image.open(画像ファイル)
# BoundingBoxから切り取る領域の算出
img_width,img_height=img.size
cut_area = (
int( BoundingBoxのLeft * img_width),
int( BoundingBoxのTop * img_height),
int(( BoundingBoxのLeft + BoundingBoxのWidth )*img_width),
int(( BoundingBoxのTop + BoundingBoxのHeight )*img_height)
)
# 画像の切り取り
out_img=img.crop(box=cut_area)
# 切り取った画像の保存
out_img.save(出力先の画像ファイル)
これを検出された顔の数だけ行います。
3.コレクションの画像から名前を出すコード
切り取った顔毎の画像を使ってコレクション内を検索します。
コレクション内を検索するには、コレクションIDが必要です。IDはコレクション作成時に指定できます。
以下、顔画像とコレクション内の顔情報を比較するを示します。
import boto3
client=boto3.client("rekognition")
with open(比較したい顔画像, "rb") as image:
response = client.search_faces_by_image(
CollectionId=コレクションID,
Image={"Bytes": image.read()},
FaceMatchThreshold=顔の類似度の境界値,
MaxFaces=1
)
返ってくる顔情報の数は最大MaxFacesの値となり、その類似度はFaceMatchThresholdを超えたものとなります。
今回はExternalImageIdを顔の名前とするので、これが欲しい情報になります。
face_name = response["FaceMatches"][0]["Face"]["ExternalImageId"]
4.AWSに顔を登録するコード
AWSに顔を登録するコードを書きます。
まずAWS上にコレクションを作ります。手順は以下のページにまとまっています。
コレクションに顔情報を追加するコードは以下の通りです。
import boto3
client=boto3.client("rekognition")
with open(登録したい顔の映った画像, "rb") as image:
response=client.index_faces(
CollectionId=コレクションを作成する際に使用したID,
Image={"Bytes": image.read()},
ExternalImageId=登録する顔の名前,
MaxFaces=1
)
5.一連のコードを一つのジョブとして実行するpipelineの作成
今回やりたいのは、顔の画像をJenkinsにアップロードして、コレクション内を検索して名前を出すことです。
また、名前がわからないときは顔と名前をコレクションに追加します。
これをJenkinsのpipelineで一連のジョブとして実現します。
pipelineを作るには、ジョブ作成時のジョブを入力する画面で、「パイプライン」を選択します。

pipelineのコードはジョブの設定画面のScriptの欄に記載します。

フローチャートを基にコードを書いていきます。
今まで書いたコードを、pipelineのstage単位にまとめます。stageの中でコードを書いたジョブを呼び出すようにします。
ここでは、stageの処理順を示します。以下のようになります。
言語はGroovyです。
pipeline{
agent any
stages{
stage('upload file') {
//Jenkinsへのファイルのアップロード
}
stage("detect faces"){
//画像内の顔の検出
}
stage("cut faces"){
//顔の切り取り
}
stage("faces loop"){
//複数の顔を処理するために繰り返します。
steps{
script{
for(int i=0; i< 検出された顔の数 ;i++){
//検出された顔の数だけ以降の処理を繰り返します。
stage("search faces by image"){
//コレクション内の顔の検索
//切り取った画像のパスと対応する名前の出力
}
if (顔の名前が登録されているか){
stage("index faces"){
//顔の名前の入力
//コレクションへ顔と名前の登録
}
}
}
}
}
}
}
}
Groovyの書き方は以下のページを参考にしました。
※顔が登録されているかの条件分岐にはifを使いました。pipelineにはwhenという機能がありますが、script内には書けないようです。
※Groovyを学び始めたばかりでかなり{}が多くなってしまいました。
stageでは「フリースタイル・プロジェクトのビルド」のジョブを呼び出すことができます。
以下、各stageの追加説明です。
Jenkinsへのファイルのアップロード
Jenkinsではジョブを実行する際に、ファイルをアップロードしてパラメータとして使うことができます。
コードを書く必要はありません。GUI上で「ビルドのパラメータ化」を使うことで実現できます。

ジョブを実行する際の見た目は以下の通りです。

しかし、pipelineを使う場合は、「ビルドのパラメータ化」だけではアップロードできません。
ジョブの実行はできるのですが、どこを探してもアップロードしたはずのファイルは見つかりません。
これを解決するためにはJenkinsのプラグイン「File Parameter」を使います。
プラグインの検索とインストールは、「Jenkinsの管理」の「プラグインの管理」から行えます。
インストールが終わったら、以下のプラグインの説明を参考にコードを書きます。
以下、上記で示したpipelineのstageに対応するコードを示します。
stage('upload file') {
steps {
unstash 「パラメータのビルド化」にて設定した名前
}
}
切り取った画像のパスと対応する名前の出力
コレクション内の検索後に、検索に使った画像と顔の名前を表示します。
今回は簡単にログとして表示します。
また、画像はJenkinsのuserContentフォルダーに置いておくとします。これにより、ブラウザから直接アクセスできるようになります。
以下のコードでログを出します。
顔の名前は、コレクションの画像から検索して求めた名前となります。
photo_url = sh( script: "echo http://`curl inet-ip.info`:8080/userContent/画像のパス", returnStdout: true)
println "url : ${photo_url}"
println "name : ${顔の名前}"
顔の名前の入力
顔情報の登録を行うために、顔の名前の入力を要求するコードを書きます。
コードは以下のようになります。
def inputFaceName = input(
id : "inputFaceName",
message : "${photo_url}\nこの人の名前は?",
parameters : [ string(name: 'faceName', defaultValue: 初期値) ],
ok : "です!"
)
println "name : ${inputFaceName}"
また、入力された名前を使って、顔と名前の登録をするジョブを呼び出すコードは以下のようになります。
build job : 顔の登録をするジョブの名前, parameters: [
[$class: "StringParameterValue", name: "PHOTO_FILE", value: 登録したい顔が映った画像],
[$class: "StringParameterValue", name: "FACE_NAME", value: inputFaceName]
]
※参考
顔認識のデモ
作ったジョブを動かしてみます。
ちゃんと登録した顔を認識してくれるかを確認します。
まず、コレクションに顔を登録していない状態でやってみます。
使う画像は以下の通りです。

実行すると、顔が検出され、以下の画像ができました。

また、コレクションに登録されていないので、名前の入力が求められます。

入力をしてジョブを再開させると無事ジョブが終了します。
次に以下の画像を使って、再度ジョブを実行しました。

ジョブを実行すると2つの顔が検出されました。
画像ファイル名(1枚目):0.JPEG

画像ファイル名(2枚目):1.JPEG

ジョブの経過を見てみると1枚目の画像の顔は認識して、2枚目の登録されていない顔に対しては名前の入力を要求してくれました。
・1枚目の顔検索結果
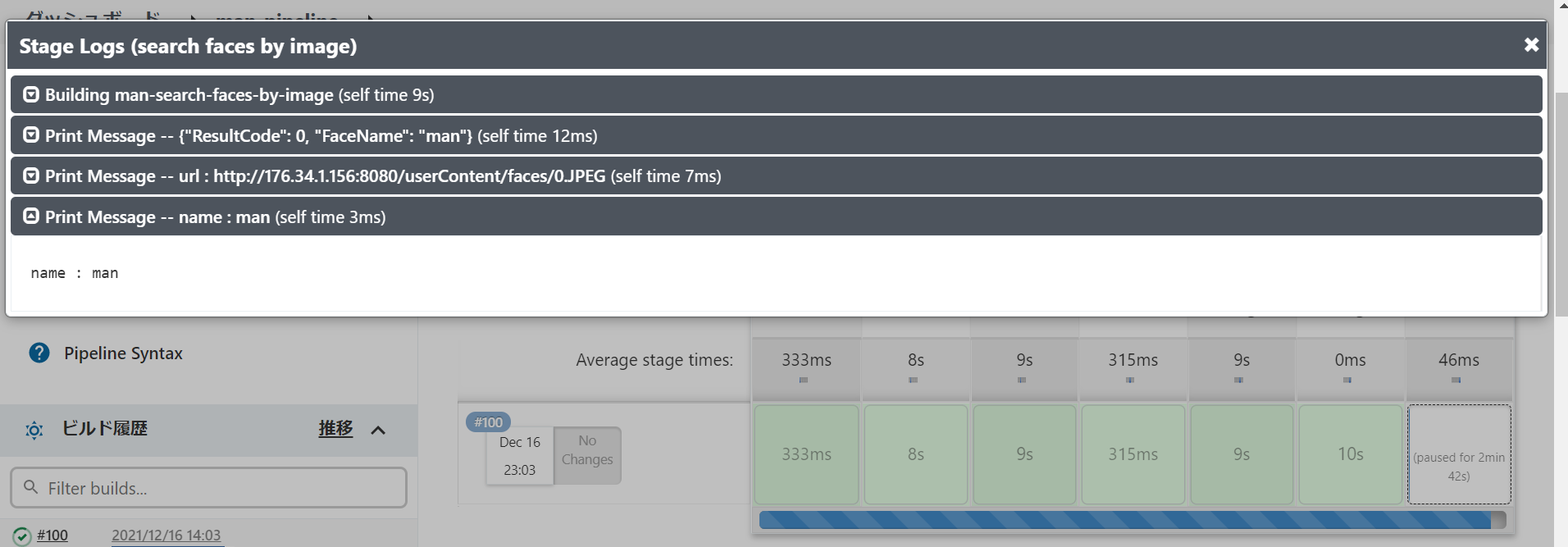
・2枚目の名前の入力

以上がデモになります。
終わりに
今回は機械学習の勉強のためにAmazon Rekognitionに触れました。
AWS SAA合格後の目標としてMLS合格を目指しています。
まだ機械学習の表面的な部分しか触れていないので、これからも勉強していきます。
ただ今回はAWSのdocsを理解することよりも、Groovyのコーディングすることの方が疲れました。。。
これで楽しい年末になることを願っています。