はじめに
AWS MLS資格取得を目指して学んだことをまとめます。
機械学習を行うための構築について実践を交えて記載します。
構築で作業時間を少なくできるよう、自動化を行うことを心がけました。
機械学習の流れ
まず、機械学習ではどんなことをするのかをまとめます。
この記事では特にインフラに関することに注目します。
・ラベリング
推論、学習などでデータを使いやすいように整形する。
分類モデルのためにデータにラベル付けをする。
大量のデータを保管、処理する。
・開発
モデルを考えて、コードを書く。
コードを書くためのツールを用意する。
ツールを実行するためのリソースを用意する。
・学習
大量のデータを用いて学習する。
学習を繰り返してよりよくする。
リソースのチューニング
・モデル変換
推論用に学習済みモデルを変換する。
・推論
学習済みモデルをデプロイして使う。
機械学習としてはデータを用意して、モデルを目標の精度まで学習させることが重要だと思っています。そのため、それ以外のことで頭を使いたくないのではないかと思います。そこで、インフラ面で自動化や時短できないかを考えます。
※参考
インフラでできることを考える。
構築について実践します。
IaCで一度やったことを自動化する。
サーバーを構築する方法を考えます。ここでは時間を使いたくないですが、既存の環境に合わせてやる必要があるので大変だと思います。そのため、知見を借りたり一度やったことは自動化したりして、楽にやりたいです。
今回は、以下のことをします。
・CloudFormationでサーバーを作る。
・shellファイルからk8sを構築する。
・k8sのマニフェストファイルからコンテナレジストリを作る。
CloudFormationでサーバーを作る。
以下、実践していきます。
CloudFormationは基本は過去ののものと同じですが、EC2のボリュームを大きくしました。これから使うコンテナイメージのために大きさが必要になるためです。
Resources:
ec2:
Type: 'AWS::EC2::Instance'
Properties:
InstanceType: t2.medium
KeyName: <key-name>
ImageId: ami-02892a4ea9bfa2192
NetworkInterfaces:
- AssociatePublicIpAddress: 'true'
DeviceIndex: '0'
SubnetId: !Ref <public-subnet>
GroupSet:
- !Ref <security-group>
BlockDeviceMappings:
- DeviceName: "/dev/xvda"
Ebs:
VolumeSize: 20
VolumeType: "gp2"
Tags:
- Key: Name
Value: !Sub '${AWS::StackName}-ec2'
shellファイルからk8sを構築する。
EC2にk8s環境を作ります。過去記事でやっているので、同じ方法で行います。初めてk8s環境を作る場合には、公式ページなどを探してエラー対応しながら行う必要があります。この記事では過去記事のものをshellファイルの形で再利用します。
k8sのマニフェストファイルからコンテナレジストリを作る。
後述でイメージをpushしてPODを作ります。そのため、コンテナレジストリを作成します。いろいろな方法があると思いますが、今回はローカルに作成します。ローカルにk8s環境がある場合、コンテナで用意する方法があります。そのためのコンテナイメージは公開されているものがあり、それを使うだけでよさそうです。今回はPODとして作ります。
先にPOD用のnamespaceを作成します。
kind: Namespace
apiVersion: v1
metadata:
name: myns
kubectl apply -f namespace.yaml
PODのyamlは以下の通りです。
apiVersion: apps/v1
kind: Deployment
metadata:
name: registry
namespace: myns
spec:
replicas: 1
selector:
matchLabels:
app: registry
template:
metadata:
labels:
app: registry
spec:
containers:
- name: registry
image: docker.io/registry:2.8.1
volumeMounts:
- name: registry-config
mountPath: /etc/docker/registry
- name: registry-storage
mountPath: /var/lib/registry
- name: registry-ui
image: docker.io/joxit/docker-registry-ui:2.2.1
envFrom:
- configMapRef:
name: registry-ui-config
volumes:
- name: registry-config
configMap:
name: registry-config
- name: registry-storage
hostPath:
path: /home/ec2-user/registry
type: DirectoryOrCreate
以下、yamlの設定について記載します。
・コンテナ
| コンテナ名 | メモ |
|---|---|
| registry | コンテナレジストリ |
| registry-ui | ブラウザからコンテナイメージを確認できるようにする |
・ボリューム
| ボリューム名 | マウントするコンテナ | メモ |
|---|---|---|
| registry-config | registry | コンテナレジストリの設定ファイルを格納する |
| registry-storage | registry | コンテナイメージのローカルの保存先 |
コンテナレジストリの設定にはConfigMapを使っています。以下、ConfigMapのyamlです。
apiVersion: v1
kind: ConfigMap
metadata:
name: registry-config
namespace: myns
data:
config.yml: |
version: 0.1
log:
fields:
service: registry
storage:
cache:
blobdescriptor: inmemory
filesystem:
rootdirectory: /var/lib/registry
http:
addr: :5000
headers:
X-Content-Type-Options: [nosniff]
Access-Control-Allow-Origin: ['*']
Access-Control-Allow-Headers: ['*']
health:
storagedriver:
enabled: true
interval: 10s
threshold: 3
---
apiVersion: v1
kind: ConfigMap
metadata:
name: registry-ui-config
namespace: myns
data:
REGISTRY_URL: http://localhost:30500
REGISTRY_TITLE: "local registry"
URLとポートは後述でまとめます。
作成したyamlファイルを使って、PODを作成します。
作成後、ブラウザからコンテナレジストリにアクセスしてみます。
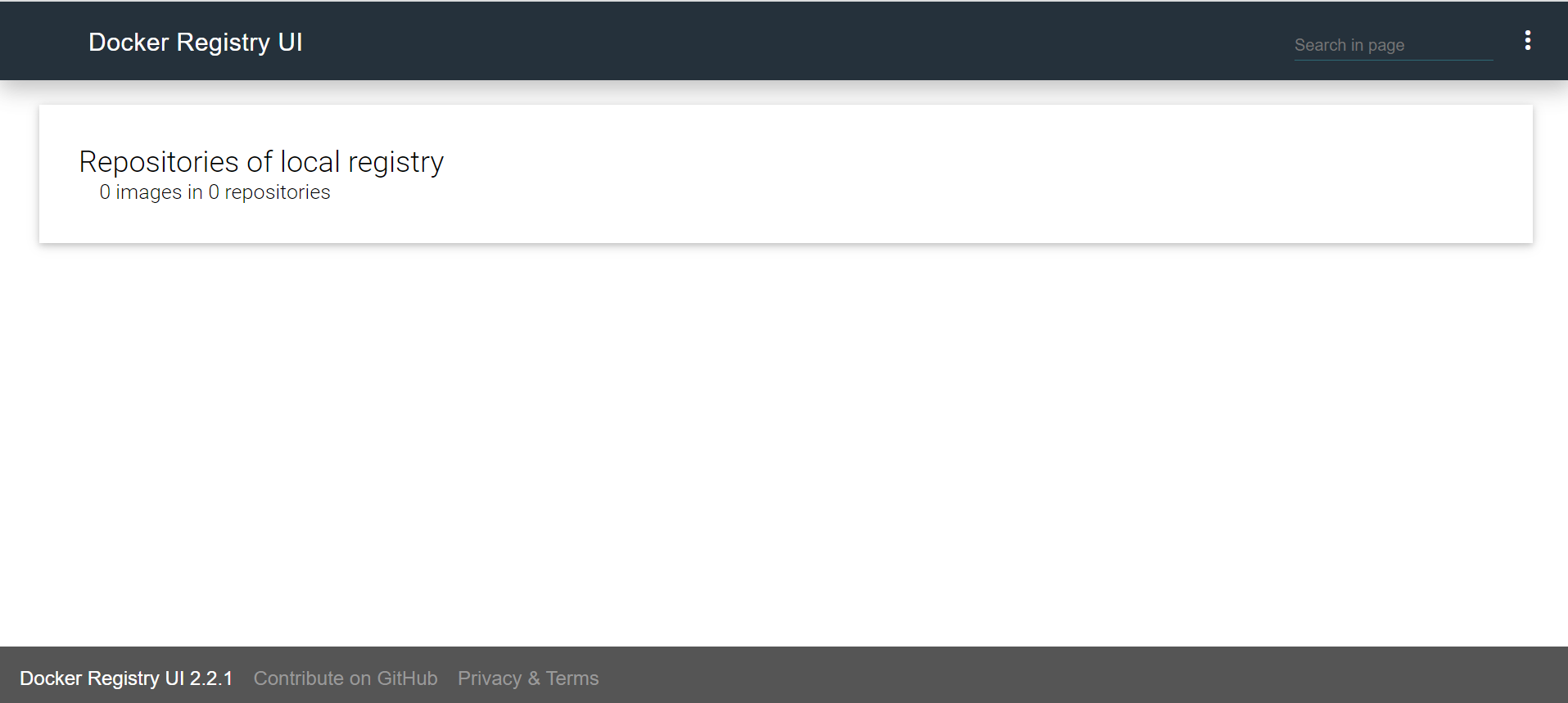
まだ、コンテナイメージをpushしていないので、何も表示されません。もし、pushされていてレジストリのPODがダウンしたとしても、DeploymentによるPODの再起動と、ローカルに保存したイメージの読み込みが行われます。
Jupyterコンテナイメージを使ってインストールの手間を省く。
次にコードを書くための方法として、Jupyterを用意します。コンテナレジストリと同様にコンテナイメージが公開されているため、利用します。
Jupyterを動かすPODのyamlファイルを作成します。DeploymentにJupyterイメージを指定するだけで完了です。
apiVersion: apps/v1
kind: Deployment
metadata:
name: jupyter
namespace: myns
spec:
replicas: 1
selector:
matchLabels:
app: jupyter
template:
metadata:
labels:
app: jupyter
spec:
containers:
- name: jupyter
image: docker.io/jupyter/base-notebook:python-3.10.4
PODを作成し、ブラウザからアクセスしてみます。
Jupyterに初めてアクセスするにはトークンが必要であるため、起動ログから確認します。
$ JUPYTER_POD=`kubectl get pod -n myns | grep jupyter | awk '{print $1}'`
$ kubectl logs -n myns $JUPYTER_POD
・・・
To access the server, open this file in a browser:
file:///home/jovyan/.local/share/jupyter/runtime/jpserver-7-open.html
Or copy and paste one of these URLs:
http://jupyter-7f5b78d4cf-qjbhb:8888/lab?token=<token>
or http://127.0.0.1:8888/lab?token=<token>
・・・
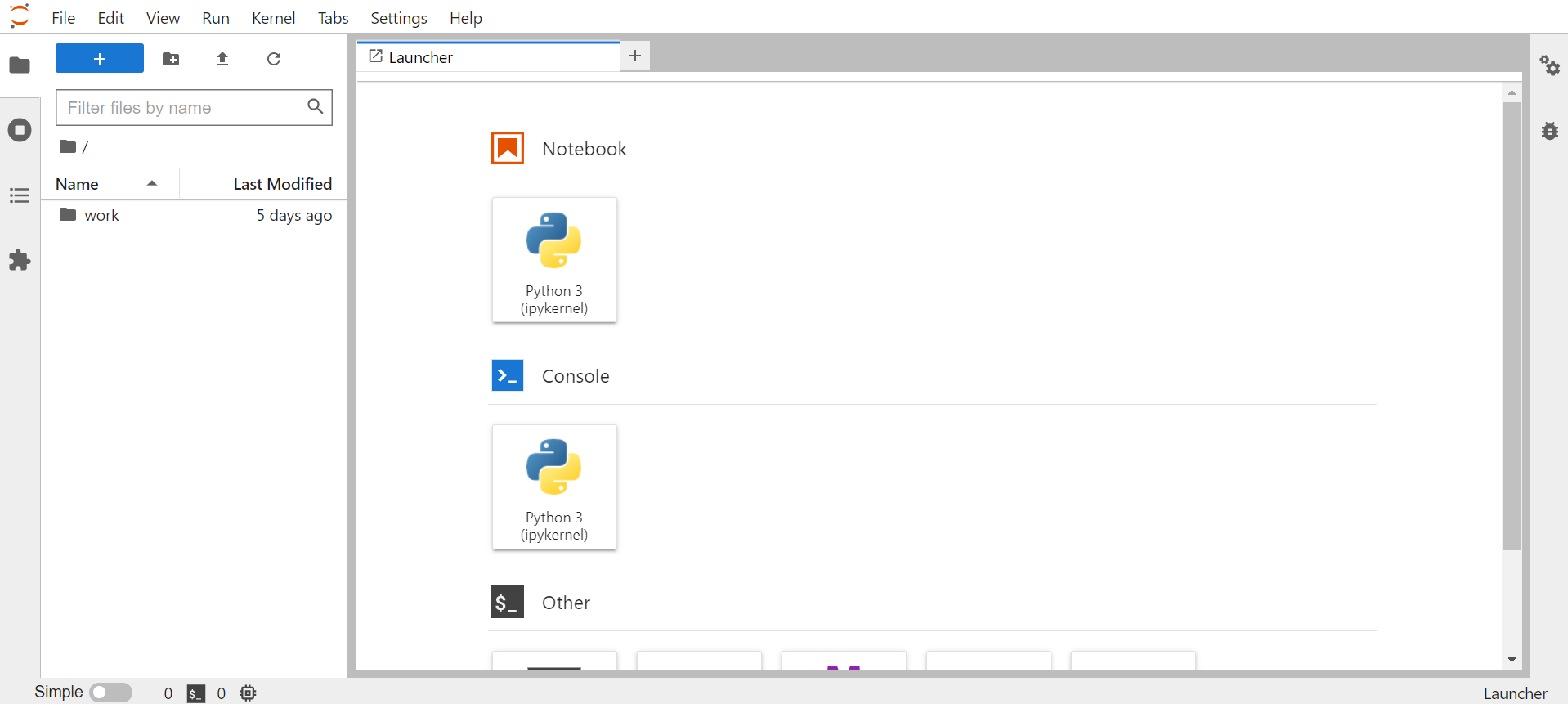
アクセスできました。
初めて使いました。スクリプトの実行とマークダウンが使えるんですね。
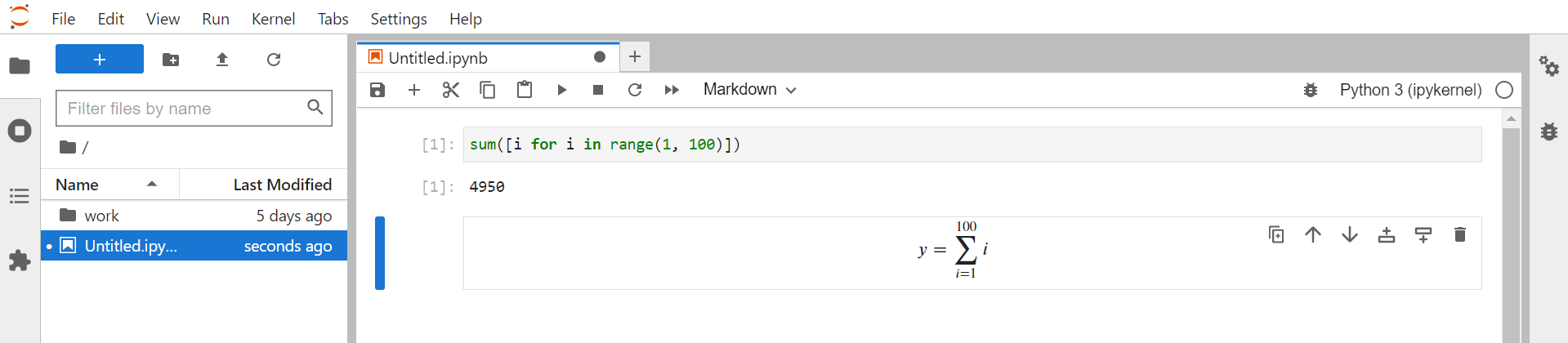
※参考
データの整形を行うためFluentdを用意する。
学習、推論用のデータを用意する方法を考えます。データに対して以下の処理を行うことを考えます。
・整形:モデルを扱える形にする。
・分類:データを加工してラベル付けする。
・フィルタリング:意図しないデータを省く。
これらを行うための方法にFluentdがあるので、作ってみます。また、Fluentdの設定ファイルを作るのは大変なので、負担を減らすためFluentdのGUI機能も使ってみます。
まず、コンテナイメージを作成します。
以下のコマンドを実行します。
#!/bin/bash -ex
REGISTRY_HOST='localhost:30500'
echo 'install git'
sudo yum install git -y
echo 'build fluentd-ui'
COMMIT_ID='d48d672ebc505b7a2ac4ff35afdbb8f843a62ef3'
FLUENTD_UI_VERSION='v1.2.2'
LOCAL_REPO_DIR="$HOME/fluentd-ui"
git clone https://github.com/fluent/fluentd-ui.git $LOCAL_REPO_DIR
cd $LOCAL_REPO_DIR
git checkout $COMMIT_ID
IMAGE=$REGISTRY_HOST/fluent/fluentd-ui:$FLUENTD_UI_VERSION
sudo docker build -t $IMAGE $LOCAL_REPO_DIR
sudo docker push $IMAGE
やっていることは以下の通りです。
・gitのインストール
・ビルドするためのソースファイルのあるgitリポジトリのclone
・fluentd-uiのbuild、push
コンテナレジストリはServiceを使いポート30500を使っているため、build,push時に指定するようにします。詳細は後述します。
pushしたイメージを使ってFluentdのPODを作成するyamlファイルを作成します。
apiVersion: apps/v1
kind: Deployment
metadata:
name: fluentd
namespace: myns
spec:
replicas: 1
selector:
matchLabels:
app: fluentd
template:
metadata:
labels:
app: fluentd
spec:
containers:
- name: fluentd
image: localhost:30500/fluent/fluentd-ui:v1.2.2
PODの作成後、ブラウザからアクセスしてみます。
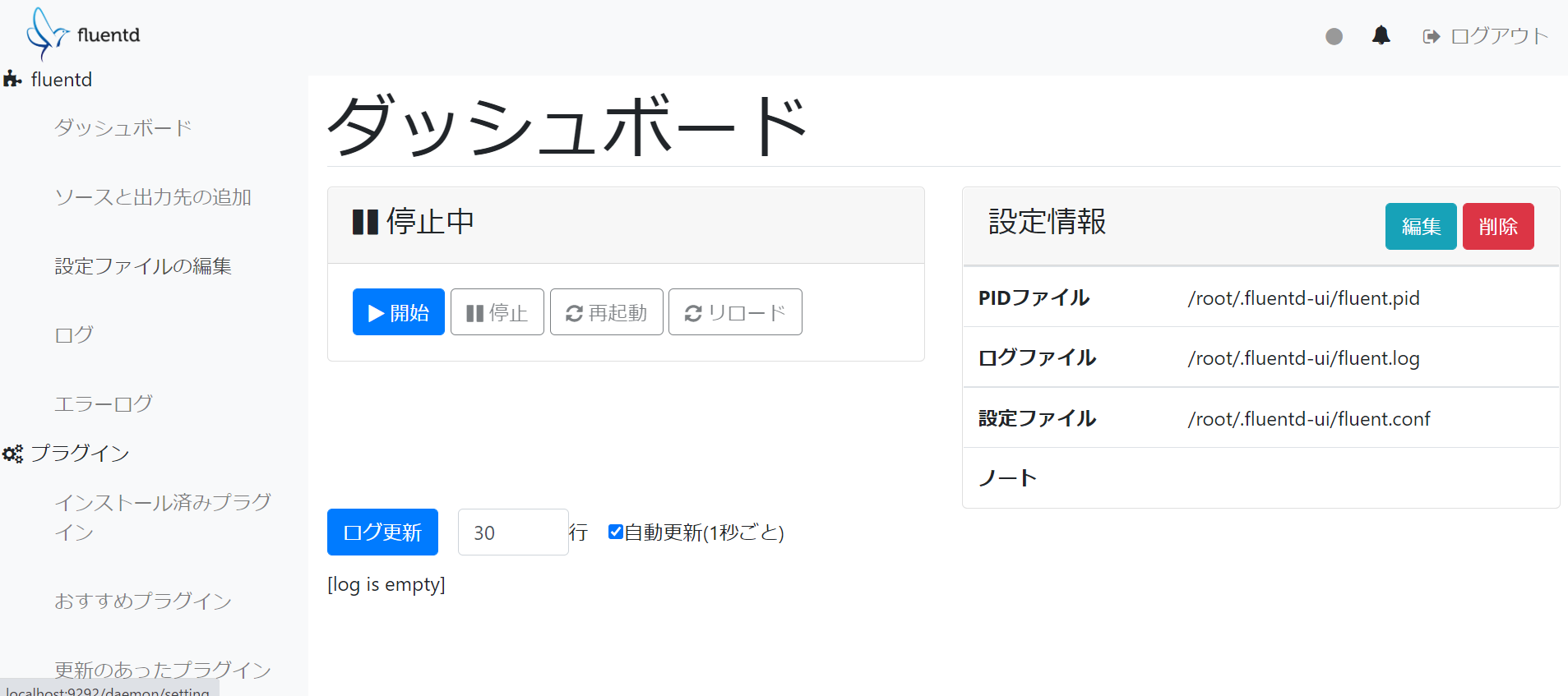
初期ログイン情報は以下の通りです。
・アカウント名:admin
・パスワード:changeme
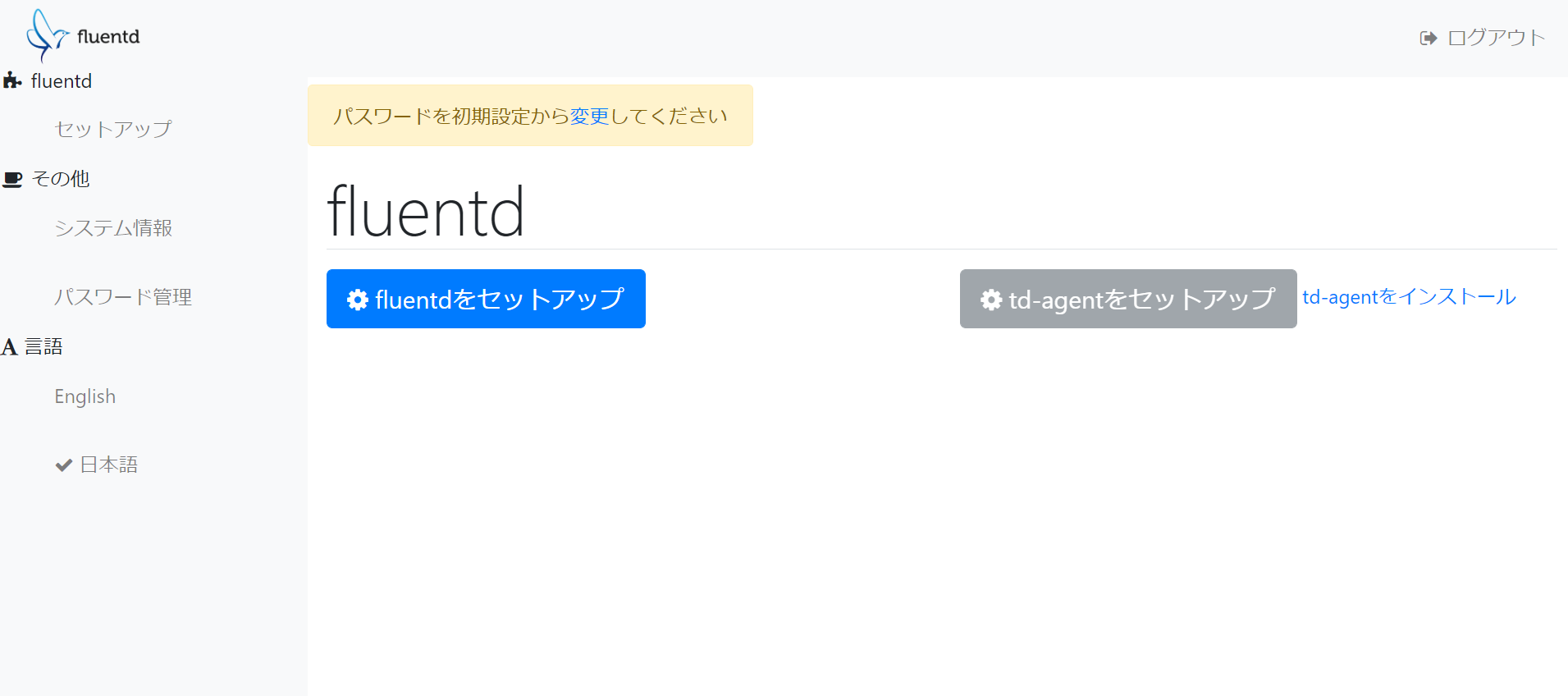
アクセスできました。
ブラウザから、設定ファイルの編集やログの閲覧ができるようです。
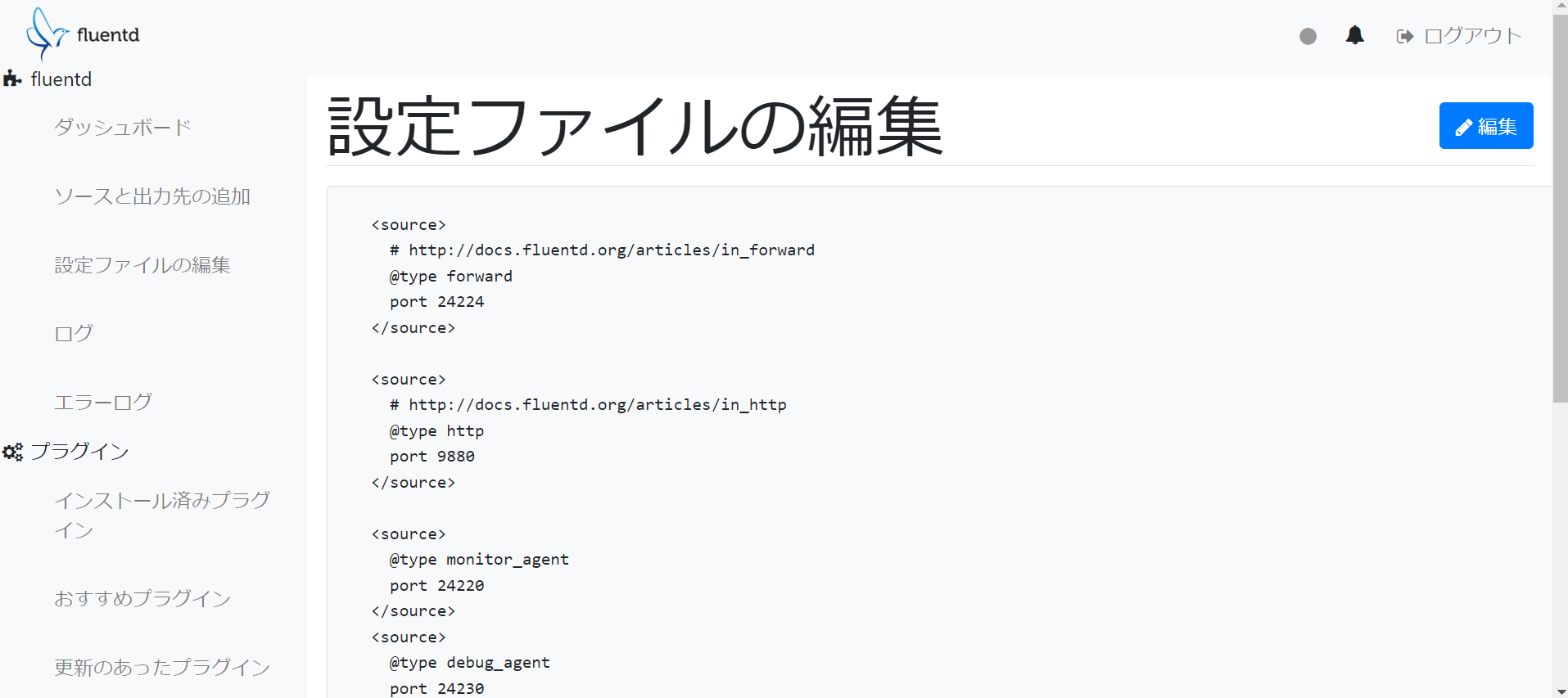
さらにデータの図や検索など行うために、Fluentd+Elasticsearch+Kibanaを組み合わせることができます。
処理の進捗を管理するJenkinsを用意する。
学習するときのことを想像します。大量のデータを使って長時間処理することになるのではないでしょうか。これを自動化できれば開発者の負担が減ると思います。
Jenkinsでは以下のことができるようになります。
・コードのまとまりをジョブとして、繰り返し定期的に実行できる。
・GitHubのプラグインがあり、ソースを管理しやすくなる。
・通知機能があり、問題があったときに気づきやすい。
Jenkinsもコンテナイメージが公開されているので、やってみます。
JenkinsのPODを作成するyamlファイルを作成します。
apiVersion: apps/v1
kind: Deployment
metadata:
name: jenkins
namespace: myns
spec:
replicas: 1
selector:
matchLabels:
app: jenkins
template:
metadata:
labels:
app: jenkins
spec:
containers:
- name: jenkins
image: docker.io/jenkins/jenkins:jdk11
次にPODを作成し、ブラウザからアクセスします。
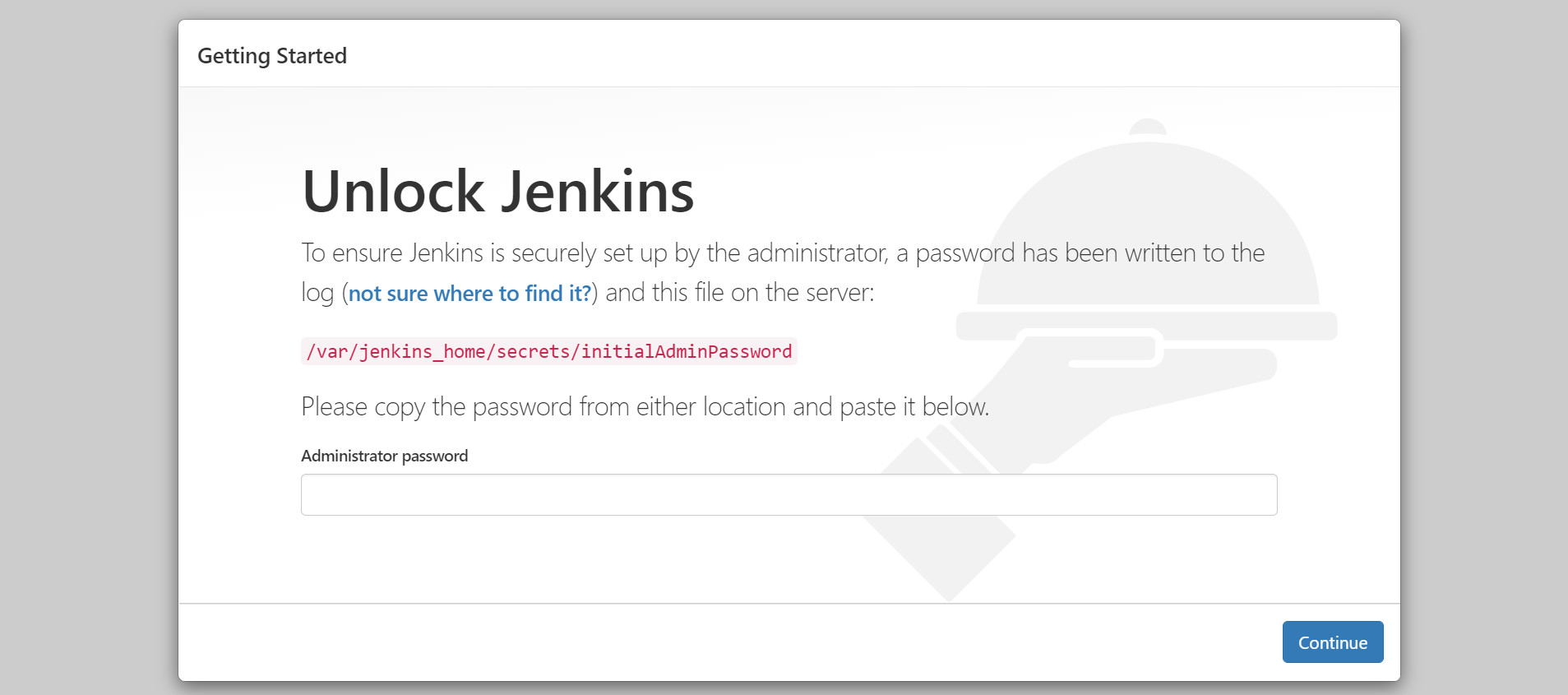
初期ログインパスワードは/var/jenkins_home/secrets/initialAdminPasswordに記載があるようです。
$ JENKINS_POD=`kubectl get pod -n myns | grep jenkins | awk '{print $1}'`
$ kubectl exec -n myns $JENKINS_POD -- cat /var/jenkins_home/secrets/initialAdminPassword
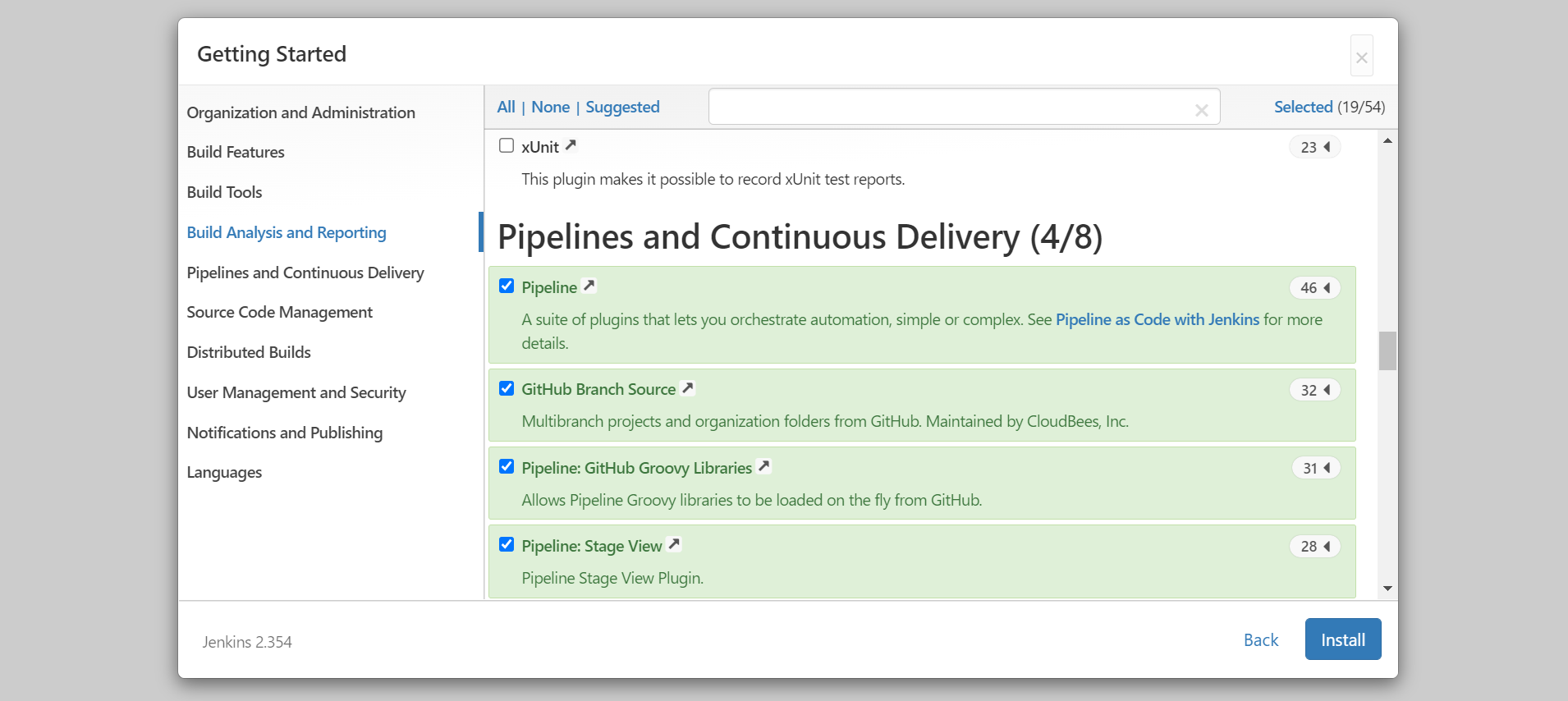
ログイン後、GitHubを含めて色々なプラグインがインストールできます。
通知機能として、メールがあり、「Jenkinsの管理」->「システムの設定」から設定できます。
試しにメールを送信してみると、以下のようなメールが届きました。

リソースを視覚的に確認するためにGrafanaを用意する。
学習を進めていくうちに、扱うデータ量が増え、処理が多くなった状況を想像します。
そうなるとサーバーのCPUやメモリが足りなくなるかもしれません。処理が中断される前に、リソースを増やしたり処理を少なくしたりなど対策したいと思います。
そこで、リソースを監視する方法としてGrafanaを用意します。
Grafanaでは以下のことができます。
・メトリクスを視覚的に表示する。
・メトリクスに対するアラートを出す。
GrafanaはOperatorを使うとインストールが楽なのでやってみます。
以下のコマンドを実行します。
#!/bin/bash -ex
SCRIPT_DIR=$(cd $(dirname $0); pwd)
echo 'install helm'
HELM_VERSION='v3.8.1'
cd $HOME
curl "https://get.helm.sh/helm-${HELM_VERSION}-linux-amd64.tar.gz" -o helm.tar.gz
tar -zxvf helm.tar.gz
mv linux-amd64 helm
echo 'export PATH=$PATH:$HOME/helm' >> $HOME/.bashrc
source .bashrc
helm version
echo 'install prometheus operator'
cd $SCRIPT_DIR
PROMETHEUS_OPERATOR_VERSION='36.0.0'
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack \
--version $PROMETHEUS_OPERATOR_VERSION \
--create-namespace \
-n monitoring \
-f prometheus/prometheus-operator-values.yaml
grafana:
service:
type: NodePort
port: 3000
targetPort: 3000
nodePort: 30300
prometheus:
service:
type: NodePort
port: 9090
targetPort: 9090
nodePort: 30090
やっていることは以下の通りです。
・Helmのインストール
・Prometheus Operatorのインストール
また、helm install時にyamlファイルをしていますが、これはGrafanaを公開するServiceのタイプをNodePortにするためです。詳細は後述します。
それでは、実際にアクセスしてみます。
初期ユーザー名とパスワードですが、k8s環境のSecretに記載してあります。
$ kubectl describe secret -n monitoring kube-prometheus-stack-grafana
Name: kube-prometheus-stack-grafana
Namespace: monitoring
Labels: app.kubernetes.io/instance=kube-prometheus-stack
app.kubernetes.io/managed-by=Helm
app.kubernetes.io/name=grafana
app.kubernetes.io/version=8.5.3
helm.sh/chart=grafana-6.29.6
Annotations: meta.helm.sh/release-name: kube-prometheus-stack
meta.helm.sh/release-namespace: monitoring
Type: Opaque
Data
====
admin-password: 13 bytes
admin-user: 5 bytes
ldap-toml: 0 bytes
$ kubectl -n monitoring get secret kube-prometheus-stack-grafana -o jsonpath="{.data.admin-user}" | base64 --decode
*** #username
$ kubectl -n monitoring get secret kube-prometheus-stack-grafana -o jsonpath="{.data.admin-password}" | base64 --decode
*** #Password
デフォルトですでにダッシュボードが作成されており、今まで作成したPODでどれくらいメモリー、CPUが使われているかがわかります。
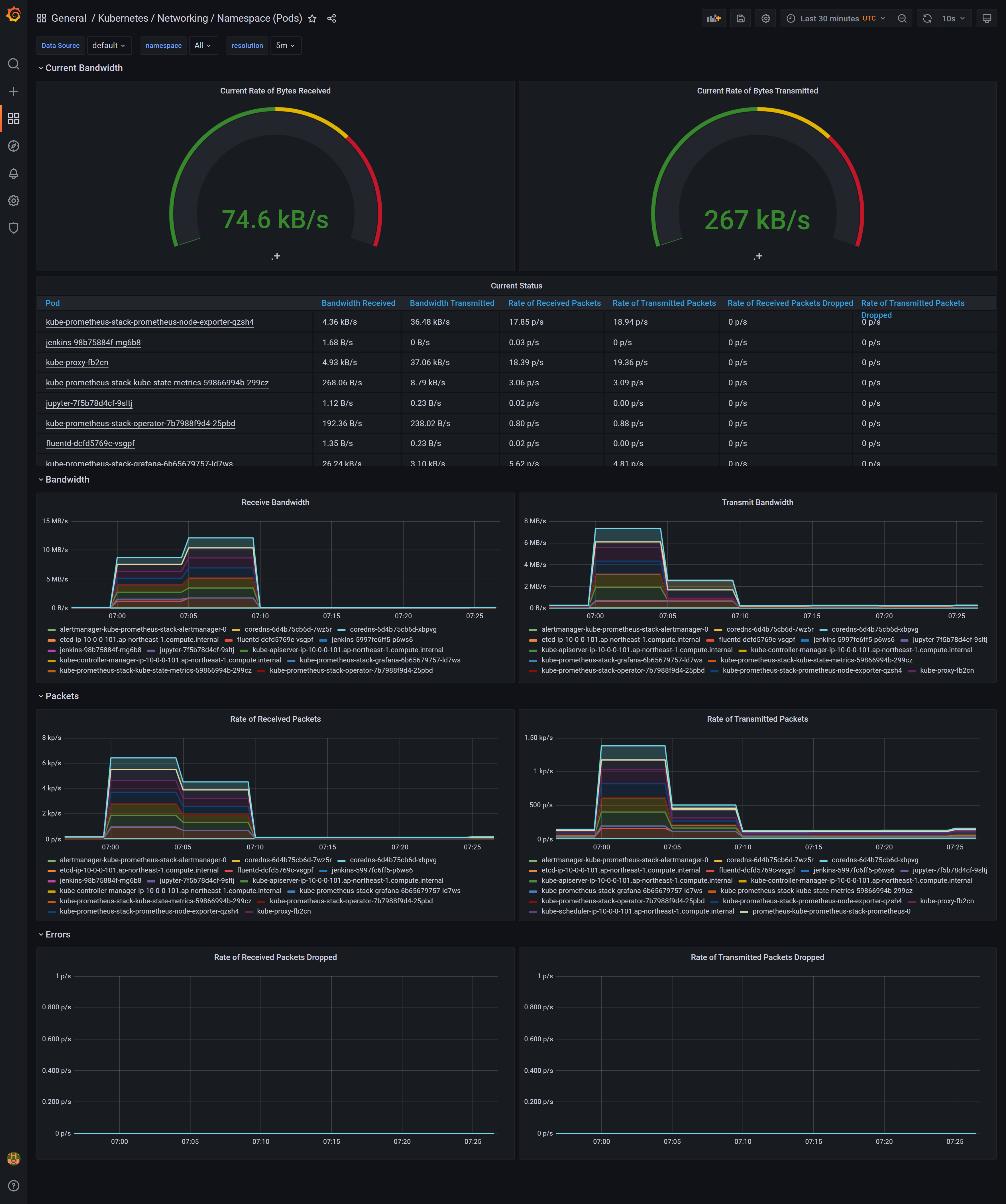
また、contact pointとアラートルールを作成することで、アラート機能を利用できます。アラート先にはEmail,Microsoft Teamsなどが指定できます。
そのほかにPrometheusも使えます。
(参考)ローカルPCのブラウザからPODにアクセスする方法
概要
今回、作成したPODにはローカルPCのブラウザからアクセスしました。方法としてはSSHポートフォワーディングとServiceのNodePortを組み合わせています。
まず、ServiceのNodePortでPOD内のコンテナでアクセス待ちしているポートをノードのポートに割り当てています。ノードにはローカルPCでSSH接続できるものとし、それ以外のポートは空いていない状況です。そのため、SSHポートフォワーディングで、コンテナの割り当てたポートにアクセスできるようにしています。
ブラウザからコンテナイメージへアクセスする経路イメージは以下の通りです。
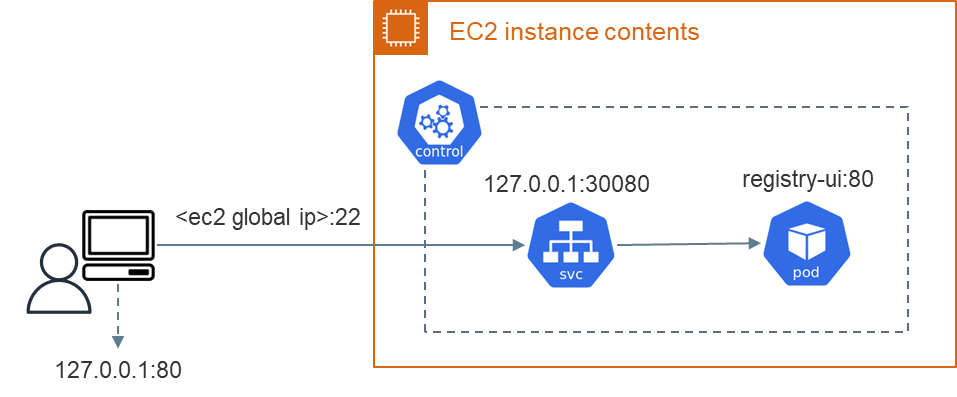
ローカルPCではSSHでEC2に接続していますが、Serviceによりregistry-uiコンテナにポート80でアクセスされます。
レスポンスはローカルPCのポート80で待ち受けされます。ブラウザのURLをhttp://localhost:80とすることでアクセスできます。
NodePortで割り当てるポート
コンテナで使用するポートに合わせ、ServiceにてNodePortを設定する必要があります。以下、ノードと割り当てるコンテナのポートをまとめます。
| ノードのポート番号例 | 割り当てるポート番号 | メモ |
|---|---|---|
| 30500 | registryコンテナ5000ポート | コンテナイメージのpushのため |
| 30080 | registryコンテナ80ポート | ブラウザからアクセス |
| 30001 | jupyterコンテナ8888ポート | ブラウザからアクセス |
| 30002 | jenkinsコンテナ8080ポート | ブラウザからアクセス |
| 30003 | fluentdコンテナ9292ポート | ブラウザからアクセス |
| 30300 | grafanaコンテナ3000ポート | ブラウザからアクセス |
| 30090 | prometheusコンテナ9090ポート | ブラウザからアクセス |
また、コンテナレジストリのServiceのyaml例を示します。
apiVersion: v1
kind: Service
metadata:
name: registry-service
namespace: myns
spec:
type: NodePort
ports:
- name: "registry"
protocol: "TCP"
port: 25000
targetPort: 5000
nodePort: 30500
- name: "registry-ui"
protocol: "TCP"
port: 20080
targetPort: 80
nodePort: 30080
selector:
app: registry
SSHポートフォワーディングの方法
割り当てられたノードのポート番号を使って、SSHポートフォワーディングをします。
Teratermの機能を使うとSSH接続の設定を省略でき、少し楽です。
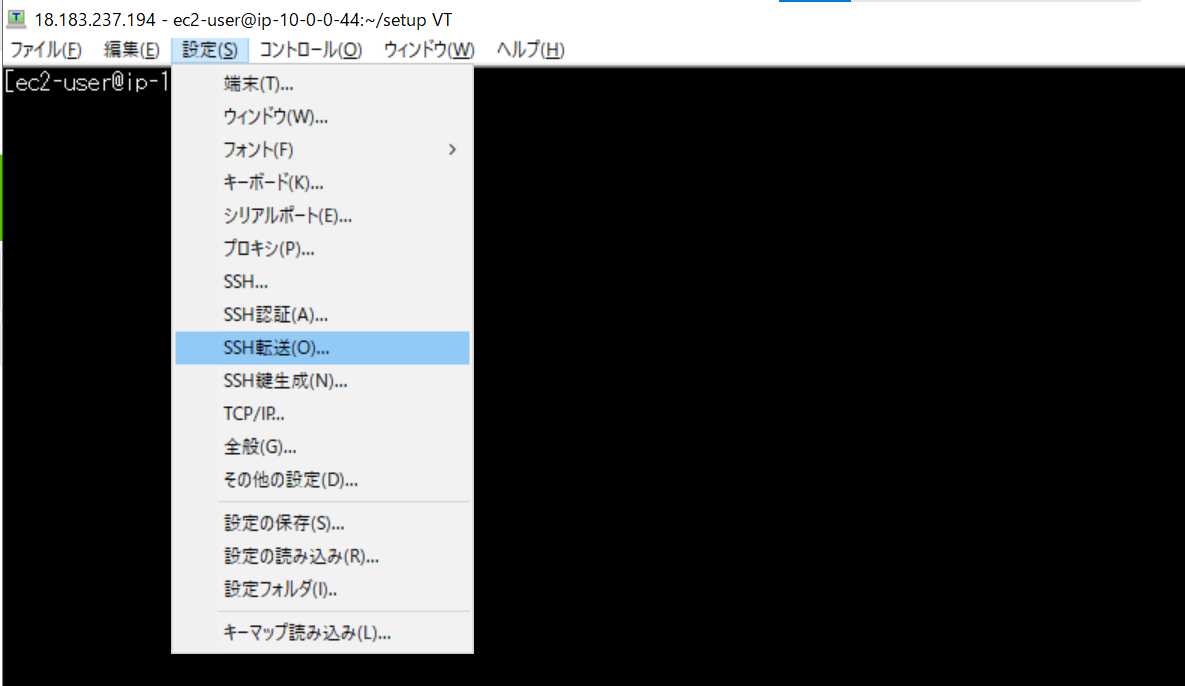
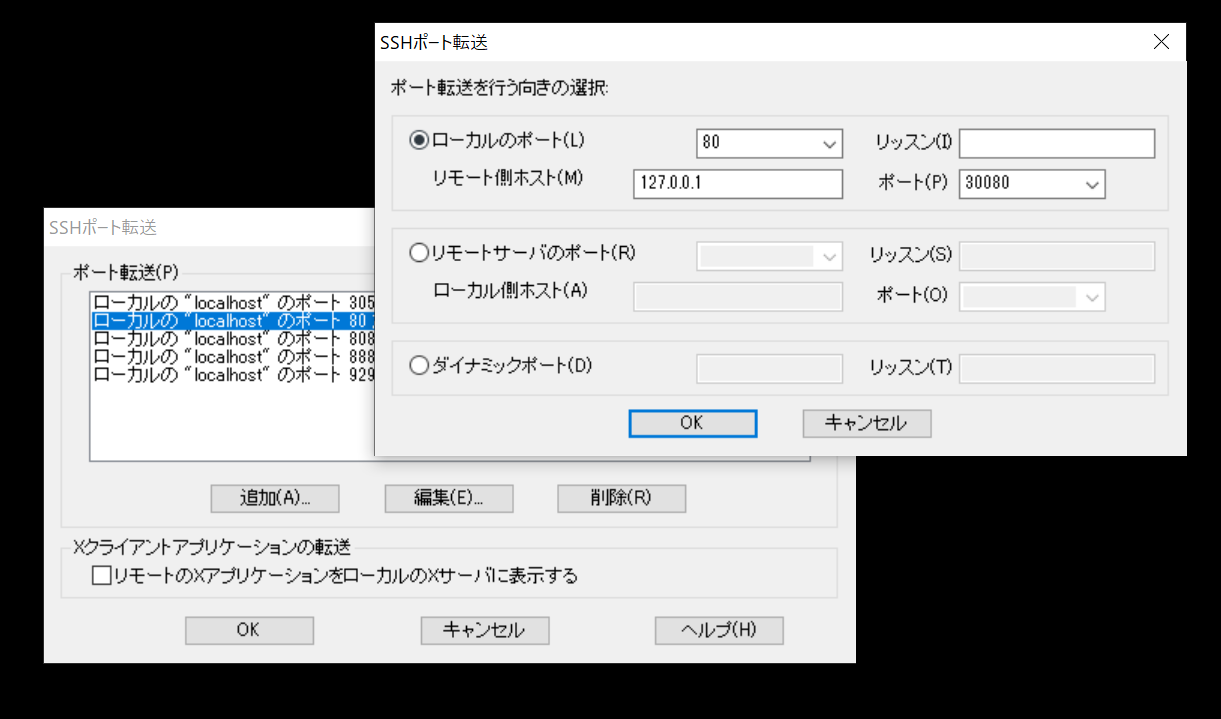
Teratermが接続された状態で必要な情報を入力します。
1個のTeratermで複数のポートフォワーディングの設定を行うことができます。ローカルのポートはブラウザにて入力するポートに相当します。
毎回設定するのは面倒な時は、Teratermの現在の設定をINIファイルに保存し、起動時に読み込むようにすることもできます。
これから勉強すること
まだ機械学習で学べていないことは多いです。以下、今後勉強していきたいと思います。
・分散処理構成について(Spark)
・AWS SageMaker
・学習の性能評価
・モデルパラメータチューニング
おわりに
今回触れた機能ですが、AWSでも実現できると思います。AWSではミドルウェアを独自に作っていたりマネージドサービスとして提供されたりしています。
AWSは強いなと感じる今日この頃です。使いこなせるように勉強していきたいです。