欠損値処理に特化したnaniarパッケージの紹介(すでにかなり有名っぽい)も兼ねていますが、どちらかというと自分のため備忘録的な記事になります。
The best thing to do with missing data is to not have any.
by Gertrude Mary Cox
こんな言葉を残した統計学者もいるくらい欠損値の処理はめんどくさい...けれども、実世界のデータを扱う際にはほとんど避けては通れないステップ。
"naniar" Package
naniarパッケージは欠損値の処理に特化したパッケージで、欠損値の要約や可視化を通して欠損値を含むデータの解釈をサポートしてくれるパッケージ。
その中でも当記事では「欠損値の確認」の部分にのみ焦点をあてている。
関数の使用例はパッケージに含まれているアメリカの生活習慣病のリスク行動調査を記録したriskfactorsデータを用いて行う。
# install.packages("naniar")
library(naniar)
data(riskfactors) #2009年のデータ
BRFSS 2009 Survey Data and Documentation
欠損値の確認
n_miss() と n_complete()
n_miss(data)はsum(is.na(data))の代替となる関数。n_complete()は逆に欠損値ではない値の数を返してくれる。
> n_miss(riskfactors$health_poor) #特定のカラムの欠損値の数を知りたいときは$を使えばよい
[1] 113
> apply(riskfactors, 2, n_miss) #全体を俯瞰したければapplyでMARGIN=2に設定すれば便利
state sex age weight_lbs height_inch bmi marital pregnant children education
0 0 0 10 2 11 1 215 0 1
employment income veteran hispanic health_general health_physical health_mental health_poor health_cover provide_care
0 0 3 2 0 0 0 113 0 3
activity_limited drink_any drink_days drink_average smoke_100 smoke_days smoke_stop smoke_last diet_fruit diet_salad
3 2 134 135 2 128 212 161 8 8
diet_potato diet_carrot diet_vegetable diet_juice
8 8 8 8
> n_complete(riskfactors$health_poor)
[1] 132
> sort(apply(riskfactors, 2, n_complete), decreasing = T)
state sex age children employment income health_general health_physical health_mental health_cover
245 245 245 245 245 245 245 245 245 245
marital education height_inch hispanic drink_any smoke_100 veteran provide_care activity_limited diet_fruit
244 244 243 243 243 243 242 242 242 237
diet_salad diet_potato diet_carrot diet_vegetable diet_juice weight_lbs bmi health_poor smoke_days drink_days
237 237 237 237 237 235 234 132 117 111
drink_average smoke_last smoke_stop pregnant
110 84 33 30
prop_miss()
上の二つの関数は実数で帰ってくるのに対してprop_miss()は欠損値の割合を教えてくれる。(結構便利。むしろ上よりもこっちのほうが使いやすそう。)
> prop_miss(riskfactors)
[1] 0.142377
> apply(riskfactors, 2, prop_miss)
state sex age weight_lbs height_inch bmi marital pregnant children education
0.000000000 0.000000000 0.000000000 0.040816327 0.008163265 0.044897959 0.004081633 0.877551020 0.000000000 0.004081633
employment income veteran hispanic health_general health_physical health_mental health_poor health_cover provide_care
0.000000000 0.000000000 0.012244898 0.008163265 0.000000000 0.000000000 0.000000000 0.461224490 0.000000000 0.012244898
activity_limited drink_any drink_days drink_average smoke_100 smoke_days smoke_stop smoke_last diet_fruit diet_salad
0.012244898 0.008163265 0.546938776 0.551020408 0.008163265 0.522448980 0.865306122 0.657142857 0.032653061 0.032653061
diet_potato diet_carrot diet_vegetable diet_juice
0.032653061 0.032653061 0.032653061 0.032653061
miss_var_summary()
今まで紹介した三つの関数を合わせたようなものがこのmiss_var_summary()。出力は変数名と欠損値の実数、さらには欠損割合。これが今の所一番使いやすそう。
> miss_var_summary(riskfactors)
# A tibble: 34 x 3
variable n_miss pct_miss
<chr> <int> <dbl>
1 pregnant 215 87.8
2 smoke_stop 212 86.5
3 smoke_last 161 65.7
4 drink_average 135 55.1
5 drink_days 134 54.7
6 smoke_days 128 52.2
7 health_poor 113 46.1
8 bmi 11 4.49
9 weight_lbs 10 4.08
10 diet_fruit 8 3.27
# … with 24 more rows
一目瞭然で俯瞰できるし、出力がtibble型なので、filter(n_miss >= x)とかで下限を指定して表示することもできるので使い勝手が良さそう。
可視化編
vis_miss()
欠損値の状況を可視化してくれるもっともシンプルでわかりやすい関数。指定したデータセットの全ての変数を俯瞰できるのがとても便利。含みたくない変数などがあればselect(data, -var)とかで除けば簡単に対応できます。
vis_miss(riskfactors)

含みたくない変数などがあればselect(data, -var)とかで除けば簡単に対応できます。
同様の機能を有した関数にはvisdat::vis_dat()が挙げられますが、グラフのx軸に欠損値の割合が表示される機能はそちらには見た感じなかったです。そのためvisdat::vis_dat()の上位互換として機能しそうです。
gg_miss_var()
変数の欠損値割合を比較するもう一つの手段が当関数。これは欠損値の割合が確認でき、デフォルトで順序がついてるところ特徴。vis_miss()で全体をざっとみて、gg_miss_var()を使って実際にどこから処理していくのか決めて行くのが良さそうです。
gg_miss_var(riskfactors)
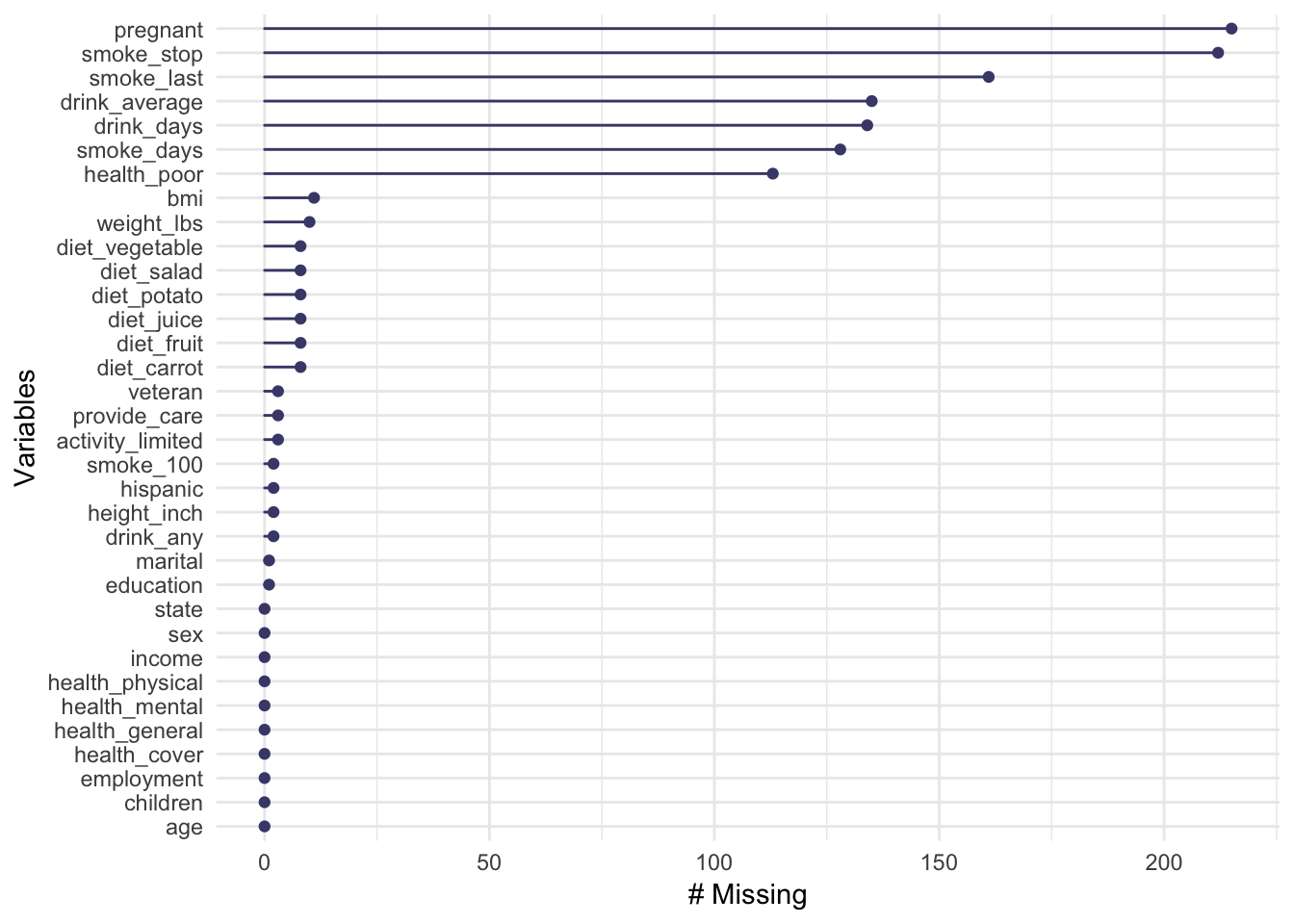
デフォルトでラベルがMissingやVariablesとなっているが、ここは変更可能。ggplot2の構文で書かれているので+ labs(x = "X", y = "Y", title = "TITLE")のように簡単に変更できる。さらに背景のテーマなんかもggplot2の構文で普段通り変更可能です
まとめ
当記事では、naniarパッケージのメインの関数しかまとめていないが、すでに便利そうな関数がたくさんある。一方で全て覚えるのは厳しそうなので、その都度確認できるようにこれからもまとめていきたい。