1. Nsight Systemsについて
Cudaの処理が時系列にグラフ上で詳細に確認できるツールです。このツールを用いると,CPU-GPU間の同期や,メモリの確保や開放がいつのタイミングでどれだけ行われたかを確認することができます。
2. 筆者の環境
- Ubuntu22.04
- NVIDIA-SMI 530.30.02
- Cuda 12.1
- GeForce RTX 4090
- gcc 10.4.0
- cmake 3.22.1
==注意==
- サンプルコードはできればCUDA12.1以上で動作させてください。11以下の場合は,古いthrustバージョン向けのコードが実行されます
- gccは11だと動かない場合があります。ビルドが通らなければ10へ変更してください
3. テスト用リポジトリ
① git clone
$ git clone https://github.com/KOKIAOKI/thrust_tutorial.git
② バージョンに注意してください
③ READMEに従ってビルドしてください。
④ ./helloを実行し,Helloが10個出てきたらOKです
4. Nsight Systemsのインストール
こちら↓の画面から,Nsight Systems を選択
https://developer.nvidia.com/gameworksdownload#?dn=nsight-systems

DOWNLOADSの欄にある,Nsight Systems XXXX.X.X (Linux Host .deb Installer) をクリックし,.debファイルをインストールします。
$ sudo apt install your_path/(file_name.deb)
5. Nsight Systemsの使い方
thrustのループ処理で,同期が発生する場合と,非同期処理が行えている場合を,Nsight Systemsを使って比較してみましょう。
5.1 Sync(同期)が頻繁に発生する場合のソースコード
以下を実行します。(HomeディレクトリでOK)
$ nsys profile ~/thrust_tutorial/build/sync
すると,Homeにreport1.nsys-repというファイルが生成されます。
次に,インストールしたNsight Systemsを起動します。

起動すると,このような画面が現れるので,File→Openでreport1.nsys-repを選択します。
このようなグラフが表示されます。ctrlを押しながらマウスホイールを上下させると拡大縮小できます。マウスカーソルをグラフの左側,右側に持っていって拡大縮小することで,特定の場所を拡大することができます。
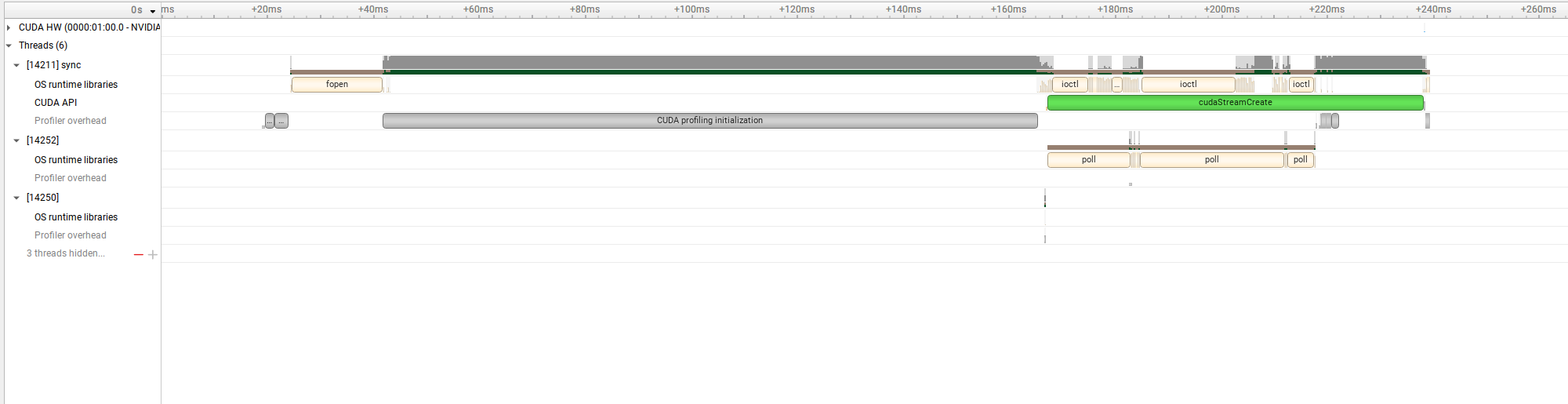
一番右の方を見てみましょう。

thrust::device_vector D(vector_size);ではthrustが自分でCudaMallocによって,GPUメモリ上にデータを割り当ててくれます。
その次に,execution policyであるthrust::cuda::par.on(stream)によって,for文内のthrustの処理は同期的に行われます。その結果,カーネルとカーネルの間にfor文の回数分だけCudaStreamSynchronizeが行われていることが確認できます。
5.2 Sync(同期)が頻繁に発生しない場合のソースコード
以下を実行します。(HomeディレクトリでOK)
$ nsys profile ~/thrust_tutorial/build/nosync
今度はreport2が作成されるので,それを読み込んでみましょう。

今回はexecution policyであるthrust::cuda::par_nosync.on(stream)によって,for文内のthrustの処理は非同期的に行われます。その結果,カーネルの間にCudaStreamSynchronizeが行われていないことが確認できます。
ちなみに,タブを新しいウィンドウにして比較することもできます。

6. (おまけ)Thrustの効率的な非同期処理実装について
6.1 hello.cuのhost,device間のコピーをできるだけ非同期処理にしてみる(hello_async.cu)
thrustの公式チュートリアルでは,host_vector,device_vectorのメモリサイズ確保,コピーはイコール=で一括で行われている。
しかし,コピーの際に1回同期が生じてしまうため,これを非同期にするには,一旦resizeを行ってからcudaMemcpyAsyncを使うことになる。ただし,resizeを行うと一回同期が入るため,1回だけコピーしたいだけだったらイコールを使ったほうがいいかもしれない。
thrust::device_vector<int> D_in(H_in.size());
int size = sizeof(int) * H_in.size();
cudaMemcpyAsync(thrust::raw_pointer_cast(D_in.data()), H_in.data(), size, cudaMemcpyHostToDevice, stream);
6.2 イコールでコピー vs Memcpyasync
thrustのチュートリアルや,hello.cuのように,一つのvectorをコピーするだけでは,あまり非同期処理をわざわざ書くまでもないかもしれない。しかし,いくつものvectorをコピーする場合,=ごとに同期が生じてしまう。
(ただ,resizeが非同期に行えないため,下記のテストではトータルの時間は結局cudaMemcpyAsyncを用いてもほぼ同じとなってしまった)
-
equal_copy.cu
- こちらでは,host→device, device→hostのコピーを10回イコールで行った。
-
memcpyasync.cu
- こちらでは,いったんhost,deviceのresizeを行った後,Memcpyasyncを用いてhost→device, device→hostのコピーを10回行った。
処理時間比較[ms]
| 実行ファイル\回 | 1 | 2 | 3 |
|---|---|---|---|
| ./equal_copy | 0.35 | 0.33 | 0.34 |
| ./memcpyasync | 0.35 | 0.35 | 0.34 |
- equal_copy.cuのnsight
CudaMallocとcudaMemcpyasyncの間には,同期が生じていないが,この操作間に同期が生じている。

- memcpyasync.cuのnsight
device_vectorのresize時は同期が生じている。

cudaMemcpyasync間には当然同期は生じていない。

6.3 結論
大したコードを書かなければイコール=の実装で十分なはず。
ただし,一度resizeしておいたvectorがあって,そこにコピーだけすれば良い場合はMemcpyAcyncを用いると良いかもしれない。(とくにdevice to hostの方)
おわりに
Cudaの挙動はなかなか把握するのが難しい。6章で示したとおり、うまく組んだつもりでも対して処理時間が変わらない場合もある。Nsight Systemsを使って無駄な処理が行われていないかこまめにチェックしてみましょう。