1GB を超えるようなCSVファイルを高速に読み込みたい
と思ったことありませんか。
1GBを超えるようなCSVファイルを読み込むとき標準のCSVは10分ぐらいかかったりします。待ち時間が苦痛です。
今回はRed Arrowを使ったCSVの読み込みが高速だという噂を聞いたので確かめてみました。
CSVファイルの読み込み速度を比較する
手元のPCでRubyでベンチマークを取る方法を参考にベンチマークをとってみました。
- 使用したCSVファイル
UK Housing Prices Paidprice_paied_records.csv(2.4GB)
CSVファイル → Ruby配列
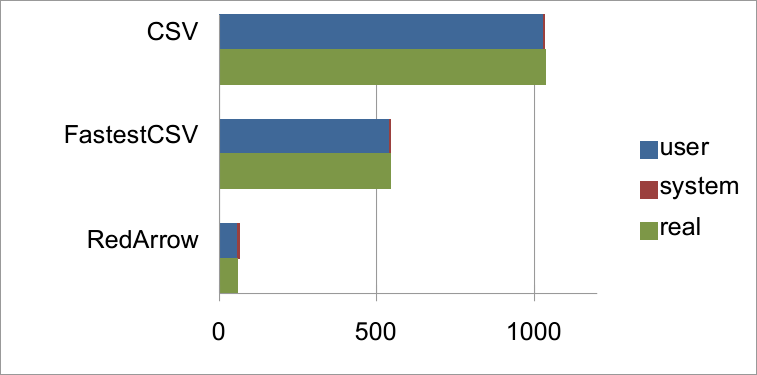
| user | system | total | real | |
|---|---|---|---|---|
| RedArrow | 60.080050 | 6.403419 | 66.483469 | ( 57.881550) |
| FastestCSV | 541.646167 | 1.304506 | 542.950673 | (543.256892) |
| CSV | 1029.813843 | 2.153048 | 1031.966891 | (1034.319889) |
ソース
require 'benchmark'
require 'arrow'
require 'fastest-csv'
Benchmark.bm 12 do |r|
r.report "RedArrow" do
t = Arrow::Table.load("price_paid_records.csv")
a = t.raw_records
end
r.report "FastestCSV" do
a = FastestCSV.read("price_paid_records.csv")
a.shift
end
r.report "CSV" do
a = CSV.read("price_paid_records.csv", headers: true)
end
end
-
CSV.readは全ての要素が文字列になってしまいます。一方Arrowはto_fやto_iの変換もしています。(なので性能でもApache Arrowが余裕をもって勝利しています) -
CSV.tableはCSV.readよりさらに時間・メモリが必要なので省略
Column → 配列
いくつかの列をピックアップして、Rubyの配列に変換します。
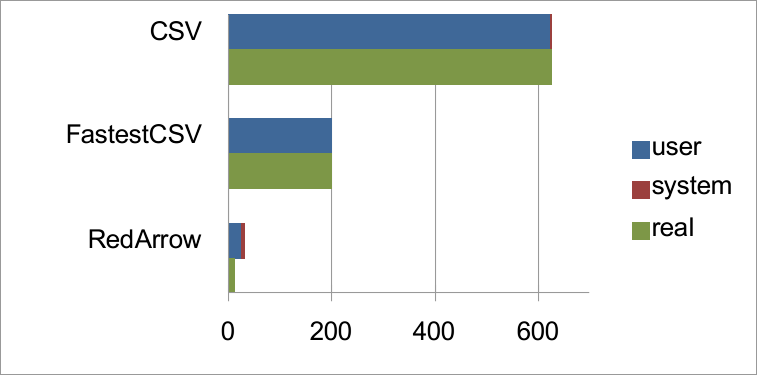
| user | system | total | real | |
|---|---|---|---|---|
| RedArrow | 24.920932 | 6.536532 | 31.457464 | ( 12.017537) |
| FastestCSV | 198.334843 | 0.967939 | 199.302782 | (199.423838) |
| CSV | 624.525033 | 0.840379 | 625.365412 | (625.699603) |
ソース
require 'benchmark'
require 'arrow'
require 'fastest-csv'
# 確認用
# t = Arrow::Table.load("price_paid_records.csv")
# t = t.select_columns(:Price, :District, :County)
# correct_array = t.raw_records.transpose
Benchmark.bm 12 do |r|
r.report "RedArrow" do
t = Arrow::Table.load("price_paid_records.csv")
t = t.select_columns(:Price, :District, :County)
price, district, county = t.raw_records.transpose
# puts [price, district, county] == correct_array
end
r.report "FastestCSV" do
price = []
district = []
county = []
FastestCSV.foreach("price_paid_records.csv") do |row|
price << row[1].to_i
district << row[7]
county << row[8]
end
# remove headers
price.shift; district.shift; county.shift
# puts [price, district, county] == correct_array
end
r.report "CSV" do
price = []
district = []
county = []
CSV.foreach("price_paid_records.csv", headers: true) do |row|
price << row[1].to_i
district << row[7]
county << row[8]
end
# puts [price, district, county] == correct_array
end
end
Arrowはマルチスレッドで動作しているので、total より real が速くなっています。
グラフを見れば一目瞭然で、RedArrowのCSV読み込みは標準のCSVライブラリの18〜52倍高速だという結果になりました。
…おそらく現時点でRubyでCSVファイルを読み込む最速の方法ではないでしょうか。
おまけ Apache Arrow とは
Apache Arrowについて聞いたことがない人も多いと思うので、少しだけ説明を書いておきます。
Apache Arrow は、効率よくメモリーにデータを配置するバックエンド向けのプラットフォームです。下記のような活用方法が期待されています。
- データ解析用ツール間での効率的なデータの通信
- 各種データ解析ツールからApache Arrowのメモリを読み書きできる
- Arrowは多言語のバインディングを持つので、言語の壁を超えてデータを連携する
- コードの記述が簡潔になる、メモリーの使用量も少なくなる、高速化される
© 2016-2019 The Apache Software Foundation
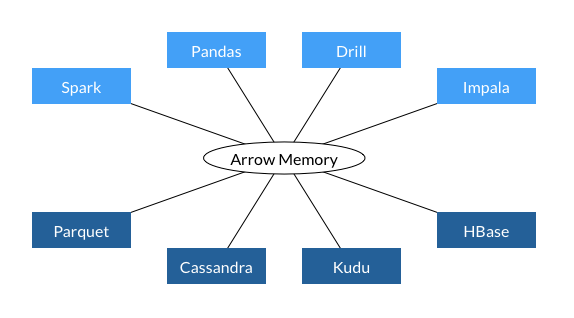
- データ解析ツールの基盤となるバックエンド
- Apache Arrow自体にも機能が追加されていって、単体でもデータフレームとして使えるようになる(予定)
- pandasなどの高速なバックエンドになったり
- Arrowを基盤にして新しいデータ解析ツールが作れる
Apache Arrow は開発中のプロジェクトで、実用的になるまでかなり時間がかかると思われます。
しかし、CSVの高速読み込みは、現段階でも大変役に立つ機能です。大きなCSVファイルを読み書きしたい人や、新しいツールが好きな人は試してみてください。
日本におけるApache Arrowの開発コミュニティ
Arrowで2番目にコミットが多い1方は、Rubyコミッターでもある(@ktouさん)です。そのため国内にApache Arrowを開発をしているコミュニティが存在します。Apacheソフトウェア財団の提供するオープンソースプロジェクトにコミットしたいエンジニアの方は参加してみるとよいのではないのでしょうか。
参考記事
この記事は以上です。