はじめに
Crystal言語というものが一体どのように動いているのかを調べてみようと思いました。しかし情報科学のバックグラウンドのない人間が少し調べたぐらいではCrystalがなぜ動いているのかはわかりませんでした。理解できた部分について書いていきます。
元々はCrystalのアドベントカレンダーのために準備した記事でした。後半は勉強不足により未完になっているのですが、近日中に完成する見込みが立たないのでこのまま公開します。(前編と書いてありますが、後編は出ない可能性が高いです)
Crystal言語とは?
Crystalは、Ruby言語に非常によく似た文法を持つ静的型付け言語です。文法はRubyによく似ており、実行速度は非常に高速です。メタプログラミングはマクロによって実現しています。型推論のおかげで型を宣言しなくても、かなりの程度までRubyと似たコードを書くことができます。
いきなり元資料
Crystalの動作する仕組みについては、上記のスライドが公開されています。
この記事はこのスライドの前半について、情報を要約、整理、追加したものです。
Crystalのコードが実行されるまでの仕組み
コンパイラはテキストファイルから、実行可能なファイルを作成する
Crystalのコードはどのようにして実行されるのでしょうか。
テキスト形式でコードを書き、crystal コマンドを利用してビルドすると、実行可能ファイルが生成されます。
最も簡単なCrystalのプログラム、x=0 をコンパイルします。
x = 0
ビルドします。
crystal build test.cr
実行ファイルを GHex で見てみましょう。こんな感じです。
これは人間が見てもよくわかりません。
かわりにアセンブリ言語のコードを出力してみましょう。アセンブリ言語は、機械語を人間がわかるように文字列で表現するものです。--emit asm オプションを指定することで、実行ファイルの変わりに、アセンブリ言語のコードを出力することができます。
crystal build --emit asm --prelude empty test.cr
prelude は、事前に読み込むファイルの指定です。emptyを指定すると、何も読み込まれないために小さなアセンブリ言語のコードが生成されます。こんな感じです。
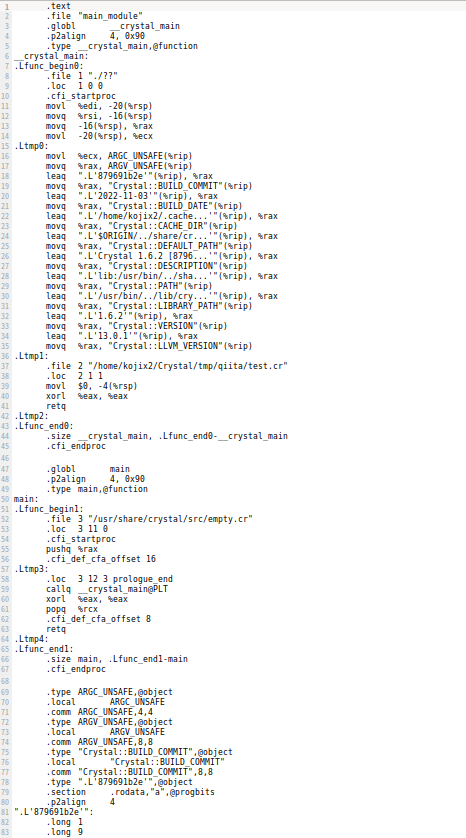
CPUに対する命令が並んでいます。コンパイラはテキストファイルから、CPUに対する命令のリストを作成しています。Crystalは最終的にはアセンブリ言語のコードを生成すればいいわけですね。
コンパイラはCPUの命令セットによって異なる実行ファイルを生成する
生成される実行可能ファイルは、プラットフォームによって異なります。たとえば、Ubuntu(x86-64)で作成された実行ファイルと、Raspberry Pi(AArch64)上で生成される実行は異なります。Ubuntuの実行ファイルをRaspberry Piにコピーアンドペーストしても動きません。これは、CPUの命令セットアーキテクチャに互換性がないからです。

だから、コンパイラはCPU環境に合わせた実行ファイルを出力する必要があります。
CrystalのコンパイラはLLVMに実行可能ファイルの作成を委託している
しかし、全てのCPUの命令セットに対応するバイナリを出力するコンパイラを作成するのは大変です。プログラミング言語の開発者にとって大きな負担になります。開発者の利用しているCPUに対して最適化されていても、別のCPUに対しては効率の悪い実行ファイルが吐き出される歪な実装ができてしまうかもしれません。
そのため、Crystalでは、LLVMという「コンパイラ基盤」と呼ばれるプログラムに、下流の部分を丸投げしているそうです。LLVMがそれぞれのプラットフォームに向けて最適化された実行ファイルを出力します。
それではCrsytalはLLVMにどうやってLLVMに実行可能ファイルの作成を依頼しているのでしょうか。
Crystalは中間表現 LLVM-IR を作成する
LLVMでは LLVM IRと呼ばれる中間表現を作成しているそうです。このLLVM IRとは、一種のプログラミング言語のようなもので、理想化されたアセンブリ言語のようなものだそうです。
LLVM IR は↓のようなファイルです。(x=0 を LLVM IR に変換したもの)
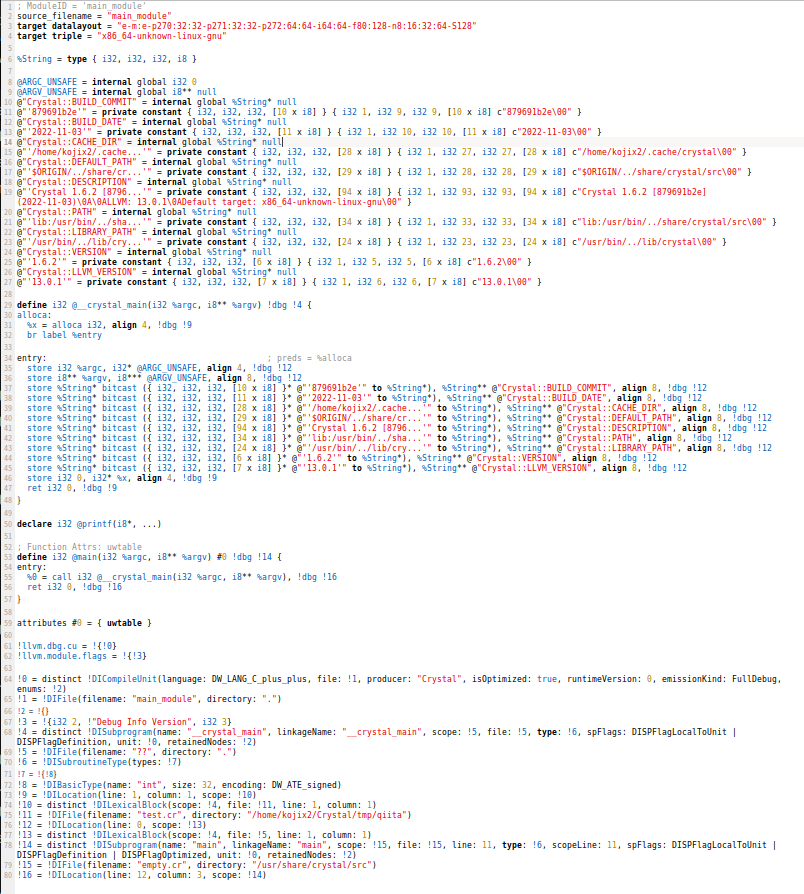
アセンブリ言語のコードを準備するためにはLLVM_IRを準備すればいいわけですね。
LLVM IR(LLVM中間表現)のコードを出力してみよう
crystal build コマンドの --emit オプションに llvm-ir を指定すると、LLVM中間表現が出力されます。先ほどのCrystal言語で書かれたスクリプトを用意します。
x = 0
crystal build --emit llvm-ir --prelude empty test.cr
--prelude オプションは、Crystalの実行時に最初に読み込むファイルを指定しています。デフォルトではこちらのファイルが読み込まれます。これを empty に切り替えることで出力されるファイルがずっと小さくなります。(これによって puts などよくあるメソッドが使えなくなりますのでご注意ください。)
test.ll というファイルが生成されていると思います。これが LLVM IR (LLVM中間表現)です。
LLVM IR(LLVM中間表現)からアセンブリ言語のコードを出力する
つぎに、このLLVM IRからアセンブリ言語のコードを作成します。これは、LLVM の LLC というコマンドを用います。
llc --relocation-model=pic test.ll
私の環境では --relocation-model=pic オプションをつけないと次のアセンブラから実行ファイルを作る工程が動きませんでした。これはメインメモリのどこにプログラムが配置されても実行できるようになるものだそうです。
アセンブリ言語をコンパイルする
clang test.s
./test
これで、LLVM IR 中間表現から実行ファイルが作成される様子を再現ことができました。
ちなみに --prelude=empty を指定しない場合、リンクするライブラリを指定する必要があります。たとえば、
clang test.s -levent -lgc -lm
といった感じです。ここでは、libevent, libgc, libmath にリンクします。エラーメッセージを参考にして適宜必要なライブラリを指定してみてください。このように、Crystal言語は、いくつかのC言語のライブラリに依存しています。したがって、マルチプラットフォーム対応もLLVMに頼るだけでは難しい場合があります。たとえば、wasm を出力する際にはwasm用のライブラリを用意する必要があります。
今回はCrystalのコンパイラにが出力するLVM IRを観察しましたが、Crystal言語を使ってLLVM中間表現を自分で出力する時は標準添付のLLVMバインディングを利用します。
上流を構成する、Lexer、Parser、Semantic
ここまで、CrystalはコードからLLVM中間表現を作成することがわかりました。ではその工程はどうなっているのでしょうか。正直にいうと、今回はよくわかりませんでした。しかし、他の多くの言語と同じく、まずは、Lexerと、Parserを利用しています。
字句解析器(Lexer)を使ってみよう
字句解析器(Lexer)は、コードの文字列を解析して、トークン(token 単語や記号などの小さな意味を持つ単位)に分解します。下記のようなコードで、CrystalのLexerを使うことができます。
require "./src/compiler/crystal/syntax"
str = ARGF.gets_to_end
a = Crystal::Lexer.new(str)
loop do
t = a.next_token
p t
break if t.type == Crystal::Token::Kind::EOF
end
こんな感じで、タブ区切りテキストを表示できるようにしておくと、
require "./src/compiler/crystal/syntax"
str = ARGF.gets_to_end
a = Crystal::Lexer.new(str)
loop do
t = a.next_token
puts [t.type,
t.value,
t.number_kind,
t.line_number,
t.column_number,
t.filename,
t.delimiter_state.kind,
t.delimiter_state.nest,
t.delimiter_state.end,
t.delimiter_state.open_count,
t.delimiter_state.heredoc_indent,
t.delimiter_state.allow_escapes,
t.macro_state.whitespace,
t.macro_state.nest,
t.macro_state.control_nest,
t.macro_state.delimiter_state,
t.macro_state.beginning_of_line,
t.macro_state.yields,
t.macro_state.comment,
t.macro_state.heredocs,
t.passed_backslash_newline,
t.doc_buffer,
t.raw,
t.start,
t.invalid_escape,
t.location].map { |i| i.to_s }.join("\t")
break if t.type == Crystal::Token::Kind::EOF
end
test.crを解析させると
x = 0
こんな結果が得られます。一行目を見ると、INDENT, SPACE, =, NUMBER, NEWLINE, EOF などが非常に細かい単位で分類されていることがわかると思います。
IDENT x i32 1 1 STRING 0 0 true true 0 0 true false false false 0 false :1:1
SPACE i32 1 2 STRING 0 0 true true 0 0 true false false false 0 false :1:2
= i32 1 3 STRING 0 0 true true 0 0 true false false false 0 false :1:3
SPACE i32 1 4 STRING 0 0 true true 0 0 true false false false 0 false :1:4
NUMBER 0 i32 1 5 STRING 0 0 true true 0 0 true false false false 0 false :1:5
NEWLINE i32 1 6 STRING 0 0 true true 0 0 true false false false 0 false :1:6
EOF i32 3 1 STRING 0 0 true true 0 0 true false false false 0 false :3:1
構文解析器(Parser)を使ってみよう
ParserはLexerを継承しています。かなり不格好ですが次のようなコードを作成しました。
require "./src/compiler/crystal/syntax"
str = ARGF.gets_to_end
a = Crystal::Parser.parse(str)
def puts_ast(ast)
puts "\e[32m# #{ast.class}\e[0m" # green
puts ast
puts
end
if a.is_a?(Crystal::Expressions)
a.expressions.each do |ast|
puts_ast(ast)
end
else
puts_ast(a)
end
これを自分自身に対して実行すると次のような出力が得られます。コードがいくつかの単位に分割されていることがわかります。
# Crystal::Require
require "./src/compiler/crystal/syntax"
# Crystal::Assign
str = ARGF.gets_to_end
# Crystal::Assign
a = Crystal::Parser.parse(str)
# Crystal::Def
def puts_ast(ast)
puts("\e[32m# #{ast.class}\e[0m")
puts(ast)
puts
end
# Crystal::If
if a.is_a?(Crystal::Expressions)
a.expressions.each do |ast|
puts_ast(ast)
end
else
puts_ast(a)
end
Parserが作成したASTノードを渡り歩くにはビジターモデルというものが使われているようです。が、すみません。今回はそこまで理解できていません。
コンパイラ
def compile(source : Source | Array(Source), output_filename : String) : Result
source = [source] unless source.is_a?(Array)
program = new_program(source)
node = parse program, source
node = program.semantic node, cleanup: !no_cleanup?
result = codegen program, node, source, output_filename unless @no_codegen
@progress_tracker.clear
print_macro_run_stats(program)
print_codegen_stats(result)
Result.new program, node
end
Semantic
Semanticはとても難しいらしく、ここまでくると解説資料も少なくなります。ここではVisitorモデルというのが使われているらしいです。
Aryさんの資料のPart2があります(ひょっとするとこれも未完成かもしれません)
私は諦めてしまいましたが、興味がある人はご覧ください。
LLVM IRはこの先で出力されているのだと思いますが、去年はそこまで追いかけることはできませんでした。
まとめ
Crystal --> assembly
crystal build --emit asm --prelude empty test.cr
Crystal --> LLVM IR
crystal build --emit llvm-ir --prelude empty test.cr
LLVM IR --> assembly
llc --relocation-model=pic test.ll
assembly --> executable
clang test.s
必要に応じて、リンクするライブラリを指定
clang test.s -levent -lgc -lm
llvm .ll -> .bc
llvm-as test.ll
lli test.bc
今回よくわからなかったこと
今回はCrstalのコードがどのように動いているのか簡単に観察しました。
この記事を書いたモチベーションの一つは、Crystalが分割コンパイルができない問題の理由を理解したいという気持ちです。Crystalで作成した関数を共有ライブラリに出力して他のライブラリから呼び出すことは推奨されていないとされます。その理由が知りたいと思っていました。
伝聞によるとCrystalは型を数値として管理しているらしく、最初にすべてのコードを読み込んで、型を数値にするらしく、分割コンパイルすると型の整合性が取れないようです。
分割コンパイルするときに、Aのコンパイルで作成した数値と型との対応は、Bの分割コンパイルで作成した数値と型の対応と異なり、整合性が取れなくなると理解しています。しかし、これはAryさんがわかりやすく説明するために単純化したもので、実際にはもっと難しい問題なのだろうと思います。
これを理解する前にSemanticsの中身を理解する必要があるようです。Aryさんのスライドによると、Aryさんの実装も特定の論文や既存のベストプラクティスに依拠しているわけではなく、試行錯誤しながら自分で組み立てたというふうに書いてある気がします。
これについては数日調べた程度で理解するのはおこがましいというものでしょう…。今回の探索はここまでとします。
最後に
この記事を書くまで、私はアセンブリ言語や、LLVM中間表現などに一回も触れたことがありませんでした。Rubyでスクリプトを書いているとなかなかこういった低レベルに触れる機会は少ないので、こういった新しい世界を学習する機会を与えてくれたCrystal言語とその作者に感謝しています。Crystal言語の開発の中心はアルゼンチンにありますが、オープンソースのプログラミング言語であり、誰でもその開発に参加することは可能です。この記事を見てCrystal言語に興味を持った方は、ぜひCrystal言語そのものの開発に挑戦してみてはいかがでしょうか。
この記事は以上です。
参考文献