この記事は 自分でNextflowスクリプトを書きたい人の記事です。例えばRNA-Seqをやりたい場合、自分でスクリプトを書くよりもnf-core/rnaseq の使い方を調べましょう。
Nextflowとは
- ワークフロー言語の一つ。AWS, GCP, Azureなどの計算資源をシェルスクリプトのように使う。
- その中身はGroovyのDSL。Groovyは、Javaプラットフォーム上で動く言語。Rubyの影響が強い。
- Groovyは、Githubトレンドでは、GradleとNextflowに使われている。Gradleはビルド自動化ツールで、Nextflowと似ている。Groovy言語はこういうのが得意みたい。
- スペインのPaolo Di Tommasoさんら、バルセロナのSeqera Labs社が中心に開発。
- EU圏の人が多く利用している印象でヨーロッパ色が強い(≠アメリカ)。
なぜ雑であることは大切なのか
完璧にやろうとすると、なかなか上達しない。Nextflowは主にクラウドで使われるため、なかなか雑にやることが難しい。そこで意図的に「雑」に振って、試行回数を増やす方法をしたい。
コミュニティ
- Slack - 活発だが、主にnf-coreの人たちが多いので、NextflowをAWS用のシェルスクリプトとして使いたい人たちにはあまり参考にならない印象がある。
Nextflow Tower
便利なウェブアプリ。これがあるからNextflowを使っている。GUIでAWSに処理を投げられる。
ヘルプに、AWSやGCPなどの設定の方法が書かれています。説明書は英語ですが、Google翻訳を使えばなんとか理解できる。個人的には /fusion/s3/ を有効にしている。
Github、Gitlabへリポジトリを作成
Nextflow Tower はGithubやGitlabのプライベートリポジトリからソースコードを実行できる。アクセストークンが必要。
新しいprocessを追加したくなったらブランチを切って、AWSで実行し、よさそうだったら main ブランチに追加するというような使い方をするとローカルPCに近い感覚でAWSを使うことができる。ただし、スクリプトを変更してからTowerからLaunchしても、実際にAWSで実行するまでに、10分〜20分ぐらいの待ち時間がかかるので、短期間に開発のサイクルを回すことはできない。
Webエディタの利用
NextflowのスクリプトはAWSなどクラウド上で実行するので、ローカル環境のエディタで編集するよりもWebエディタを利用した方が楽な気がするがどっちでもよい。
Dockerイメージの作成
Nextflowを実行するには仮想環境が必要で、Docker、Singlarity、Podmanなどがサポートされている。特にこだわりはないのでDockerを使う。バイオインフォのツールのインストールはminicondaを使う。Docker界隈では、レイヤーは薄ければ薄い方がよいと言われているが、個人がNextflowを使うケースでは、何回も実行するものではないので、気にする必要はないと思われる。
Dockerfileの作成には、ハマりどころがいくつもある。
# Miniconda3
FROM continuumio/miniconda3
LABEL maintainer="someone@mail.com"
RUN apt update -y --allow-releaseinfo-change && \ # (1)
apt upgrade -y && \
apt install -y procps && \ # (2)
conda config --add channels bioconda && \
conda update -n base conda && \
conda install samtools=1.12 && \ # (3)
conda install bwa-mem2
CMD ["/bin/bash"]
-
--allow-releaseinfo-changeこれが必要。 -
procpsこれも必須です。ないとpsコマンドが使えないとして、Nextflowが異常終了する。 - Dockerfile に限らないことですが、Biocondaはバージョンを指定しないとツールを正しくインストールしてくれない場合がありえる。要注意。
Docker Hub にイメージをアップロードする
時間がかかるので、Github ActionsやGitlab CI/CDなどを利用して自動でイメージをビルドしてDockerhubにアップロードさせるようにすると良いと思う。
ちなみに、Dockerイメージではなく、Dockerfileを指定できるようにするという提案はリジェクトされているため今後も実現する可能性は高くないと思われます。
AWS S3 (オンラインストレージ)にデータをアップロードする
データのIOはボトルネックになりやすく、ダウンロード、アップロードには時間がかかります。個人的にはNASのクラウドシンク機能を使用しています。ファイルのリストもCSV形式で作成してアップロードしておきます。
最小限のNextflowスクリプト
こんな感じのスクリプトから開始します。(疑似コード的に適当に書いており、実際に動かしていないので動作しない可能性があります)
ID, path1, path2 のCSVファイルから始めるのがポイントだと思います。
#!/usr/bin/env nextflow
nextflow.enable.dsl=2
params.input = ''
params.outdir = ''
params.ref = ''
Channel
.fromPath(params.input)
.splitCsv(header:true)
.map{ row-> tuple(row.id, file(row.f1), file(row.f2)) }
.view()
.set{ input_ch }
process BWA2 {
publishDir "$params.outdir/$id", mode: 'copy', overwrite: true
input:
tuple val(id), path(f1), path(f2)
output:
path '$id.sam'
script:
"""
bwa-mem2 mem $params.ref $f1 $f2 > $id.sam
"""
}
workflow {
BWA2(input_ch)
}
これだけだと、よくメモリ不足でコケたりしますし、あるプロセスでは別のコンテナを使いたいという場合もよくあると思いますので、
cpus 8
memory "32 GB"
container 'kojix2/hogefuga:latest'
をプロセスごとに設定していきます。全体の設定は、nextflow.configというファイルを用意して、
process {
container = "kojix2/lo9leev2ho"
cpus = 2
memory = '8 GB'
}
とすることができます。ところで、この nextflow.config が何のファイル形式なのか調べましたがわかりませんでした。NextflowスクリプトのDSLっぽいです。
ブランチを切って実行する
コマンドから実行することもできるのでしょうが、私はTower経由でGUIで実行しています。
Rubyのスクリプトを書くときはあまりブランチを切らないのですが、NextflowではGitのブランチ機能は本当に便利だなと思いました。ブランチを切りながらプロセスをどんどん追加して、ブランチ内でコミットを繰り返して修正し、大丈夫そうだったらメインにマージするということを繰り返します。そして実際にどのプロセスを実行するかは workflow の中で調節します。
ただし、ブランチを切ってカオスにならないように、ちゃんとブランチには意味のある名前をつけましょう…。
Nextflow REPL Console
Nextflowの書き方がよくわからない場合は、リファレンスを見るだけでなくREPLで実行したくなります。
Nextflowの元言語のGroovyには Groovy Console というのがあります。これをNextflowで使えるようにした Nextflow Console というものがあります。これは単に nextflow console と打ち込むと起動します。
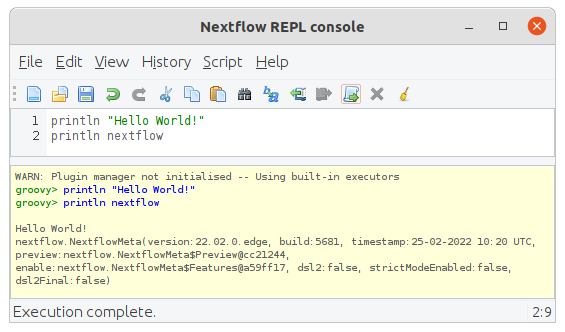
Hello Worldを実行して、ビルトインの変数 nextflow を呼び出したところ。
詳しくは公式ブログ記事をご覧ください。
実行に失敗したら - トラブルシューティング
ありとあらゆるところで失敗します。Nextflowを一回実行するところまでたどりつけません。
DockerやS3のトラブル
やってみて感じたのは、Nextflowとは関係ない部分での失敗がかなり多いことです。具体的には、
- Dockerのイメージの作成ミス
- Docker Hubへのアップロードし忘れ
- S3 のアドレスの指定ミス
- S3 にデータが存在しない
メモリ不足
メモリー不足は頻繁に発生します。Javaのメモリ割当が不足してストップすることもよくあります。140番とか150番台のよくわからないエラーが発生してしている場合は、真っ先にメモリ不足を疑うべきです。
メモリ不足は、ほとんどのファイルで発生せず、ごく一部の例外的に大きなサイズのファイルを処理する時だけ発生することがあります。そんな時のために、自動的にメモリのサイズを2倍にリトライしてくれる書き方が存在します。
process foo {
memory { 2.GB * task.attempt }
time { 1.hour * task.attempt }
errorStrategy 'retry'
script:
<your job here>
}
デフォルトではリトライ回数は1回です。なので、無限にメモリを増やし続けることはありません。しかし、次の記述を加えてリトライ回数を増やすこともできます。
maxRetries 3
Nextflow Towerの良くないところは、ログに大雑把な情報しか表示されないことです。
実行時の標準出力のログなどは、自分でAWS CLIなどを使ってダウンロードして観察しなければならない場合があります。エラーメッセージの最後に、標準出力へのリンクが表示されますので、それをダウンロードして観察します。そうすることで原因がわかる場合もあります。
エラーの原因がどうしてもわからない場合は、最終的にはAWSにログインして調査するしかないですが、このあたりはまだ何もわからないので試行錯誤です。
カレントディレクトリではない場所のファイルを操作するコマンドには要注意
例えば、gzip 解凍のようにパス元のファイルを操作するコマンドはトラブルを起こしやすいです。Nextflowはインプットに指定しないファイルはコピーしないで直接処理するらしい。カレントディレクトリの操作だけで終結するといいけれども、元パス先のファイルを操作するとトラブルになりがち。具体的には、解凍する必要のない圧縮ファイルを解凍されてしまったり、インデックスを作成するときに、元ファイルにインデックスを作成したり、気が付かないうちにツールが作成したファイルが、残ってしまうなどのことが起きる。
小さく実行する
NextflowはTowerから一回実行命令を出すと、Hello World のような簡単なものでも15分ぐらいかかり、1時間に最大でも3-4回しか試行できないことになります。普段PCの眼の前のターミナルで無数のエラーを出しながら、必要あれば修正をすればいいという発想で開発をしていると、このことは大変ストレスに感じられます。あまり良い対策方法はないような気がしますが、実行サンプルを1個か2個に減らして、これがうまくいくまで回し続けるという感じになるかと思います。
結果のファイルをコピーするべきかどうか
これ、よくわかってないんですけど、デフォルトではリンクが生成されるようになっているようです。自分の場合は最後まで実行したらWorkディレクトリをサクサク消してしまうので、保存する必要がある中間ファイルや、最終産物は必ずコピーして保存するようにしています…。
nf-core のスクリプトを参考にしない(方がいいと思う)
コミュニティとしてのnf-coreはすごいし、ツールとしてのnf-coreのワークフロー群は快適で便利だなと思っていますが、僕はRuby育ちなので、ソースコードとしてのnf-coreには違和感を持っています。nf-coreのスクリプトは複雑でしっかりしすぎてて難しい。
さらにnf-coreの哲学は、オリジナルのNextflowの哲学と少し距離があるのではないかと思っています。
Nextflowのメインの開発者は、Paolo Di Tommaso さんというスペイン在住の方です。Nextflow言語のコミット履歴を見ますと、Nextflow言語は、Paolo Di Tommaso さんがほとんど独力で開発されてきたことがわかります。
コミットログを見てると、このプロジェクトはちょっと危ういなと感じるかもしれません。一人の天才的人物に率いられているプロジェクトは、OSSの世界にはたくさんあります。しかし、開発体制としては主席開発者が何らかの理由で抜けると、プロジェクトが停滞する危険性があります。
そんなNextflowの作者の Paolo Di Tommaso さんが自分で作っているワークフローがあります。いわばNextflow作者公式のワークフローといってもいいでしょう。
僕はコレのワークフローに目を通したことがあるのですが「おや?『nf-core』のワークフローとはなんだか随分雰囲気が違うな!」と感じました。CalliNGS-NFは、nf-coreと違って簡潔で、Rubyのスクリプトを書く人間からみて「こういう風であってほしいな」という納得感がある、そんな気がしました。根拠のない個人の感想ですが、実際に私はCalliNGS-NFにいくつかプルリクエストを送ってマージされていますので、感想を述べるぐらいは許されるでしょう。
コンピュータの技術で「あれ?なんでこれこうなっているんだろう?」って感じるところは、多くの場合は技術的なズレよりも、目的意識のズレから発生していることが多い。nf-coreも、それを必要としている人の立場に立って見ると目的に合致する構成となっているのだと思います。ただし、その合理性はNextflowのオリジナルな出発点と、違うものになっている気がします。
そういう意味では nf-core のセカンドシステム症候群は心配で、これを、本当に持続的にメンテナンスできるのかは少々疑問に思っています。
いろいろ書きましたが、個人が解析にAWSを利用する目的で使い捨てのNextflowのスクリプトを自分で作成する場合は、nf-coreは参考にしないほうよいのではないかというのが私の意見です。
マーケティングからは距離を置く
もう一つ、ワークフロー言語界隈全体で私が奇妙だと感じているところがあります。それは無理やり「イケてる感」を出そうとする傾向があるところです。JVM言語、Groovy、DSLって、良い意味で枯れた組み合わせだと思うのですが、Nextflowのマーケティング的はイケてる感を出したいみたいですね。その動機がなにかを考えると、私はこの感覚が好きになれません。
Nextflowに限らず、ワークフロー界隈はそういう雰囲気があります。大手クララウド業者の資金を背景に盛り上がりを見せていますが、必要以上の宣伝を急いでいる傾向を感じますね。The Biostar Handbookじゃないですが、そういったものからは少し身を引いて構えるのが一般的な態度だと思います。
Nextflowは、TowerのUIの作り込みとか、クラウド環境との親和性の高さとか、民間企業が開発していることのメリットが発揮されていますが、一方で、科学的な探究心や、時代を超えた普遍的な価値の追求において、やや頼りない面があるかもしれません。
まとめ
Nextflowは計算資源がない環境においても、クラウド事業者に課金さえすれば、個人であっても潤沢な計算資源が使えるワークフロー言語であり、その目的を達成するためには大変便利なツールです。
この記事は以上です。