
はじめに
https://github.com/yoshoku/rumale
このページはRumaleの公式リファレンスを、DataCamp.comの提供するScikit-Learnチートシートを参考に、並び替えたものです。(この記事を書いている人は機械学習の初心者です。編集リクエストを歓迎します。)
インストール
gem install rumale
yardで公式リファレンスを見る
Rumaleには、このチートシートには載っていないアルゴリズムや機能もいっぱいあります。
最新の情報を確認してください。
gem install yard # yardのインストール
yard server -gd # yard serverを起動
ブラウザで http://localhost:8808 にアクセス
もちろん https://www.rubydoc.info/gems/rumale を見てもいいです。
周辺的なツール
作業中に結果を可視化したくなるケースはよくあると思います。Rubyの可視化ライブラリはまだ定番がないので、各自好きなのを使っていいと思います。
-
numo-gnuplot
- NArrayと相性がよい
-
GR.rb
- 便利
-
Flammarion で Plotly を使う
- dRubyサーバーを立てて、フラマリオンをフロントオブジェクトにするなど
- iruby-plotly
- PyCallでmatplotlibやSeaborn
データフレーム
基本 (A Basic Example)
require 'rumale'
ruby_labels = Rubyの配列
# [0,0,0,0,0,1,1,1,1,1,2,2,2,2,2] など
ruby_samples = Rubyの配列
# [[sample_1], [sample_2], [sample_3], .. [sample_n]] など
# NArrayへの変換
labels = Numo::Int32.cast(ruby_labels)
amples = Numo::DFloat.cast(ruby_samples)
# データ前処理
# ラベルのエンコーディング、サンプルの正規化など
# モデルの作成
model = Rumale::NearestNeighbors::KNeighborsClassifier.new
model.fit(samples, labels)
# 予想
model.predict(new_samples)
# 評価
puts model.score(test_samples, testl_labels)
データを読み込む (Loading The Data)
Rubyの配列をNArrayに変換します。
labels = Numo::Int32[*ruby_array]
# labels = Numo::Int32.cast(ruby_array) も同じ
samples = Numo::DFloat[*ruby_array]
# samples = Numo::DFloat.cast(ruby_array) も同じ
Libsvm形式のファイルを読み込む。
# Load the training dataset.
samples, labels = Rumale::Dataset.load_libsvm_file(‘pendigits’)
データの前処理 (Preprocessing The Data)
標準化 (Standardization)

特徴量の平均を0、分散を1にする変換
normalizer = Rumale::Preprocessing::StandardScaler.new
new_training_samples = normalizer.fit_transform(training_samples)
new_testing_samples = normalizer.transform(testing_samples)
正規化 (Normalization)
normalizer = Rumale::Preprocessing::L2Normalizer.new
new_samples = normalizer.fit_transform(samples)
二値化 (Binarization)
Numo::NArrayの機能でできる
na[na >= thresh] = 1
na[na < thresh] = 0
カテゴリ特徴量の符号化 (Encoding Categorical Features)
カテゴリ特徴量をNArrayに変換
encoder = Rumale::Preprocessing::LabelEncoder.new
labels = Numo::Int32[1, 8, 8, 15, 0]
encoded_labels = encoder.fit_transform(labels)
# => Numo::Int32#shape=[5]
[1, 2, 2, 3, 0]
decoded_labels = encoder.inverse_transform(encoded_labels)
# => [1, 8, 8, 15, 0]
labelsは、Ruby Arrayでも可
encoder = Rumale::Preprocessing::LabelEncoder.new
labels = ["あ", "い", "い", "あ", "う", "う"]
encoded_labels = encoder.fit_transform(labels)
# => Numo::Int32#shape=[6]
# [0, 1, 1, 0, 2, 2]
decoded_labels = encoder.inverse_transform(encoded_labels)
# => ["あ", "い", "い", "あ", "う", "う"]
ワンホットエンコーディング (one-hot-encoding)
encoder = Rumale::Preprocessing::OneHotEncoder.new
labels = Numo::Int32[0, 0, 2, 3, 2, 1]
one_hot_vectors = encoder.fit_transform(labels)
# => Numo::DFloat#shape=[6,4]
# [[1, 0, 0, 0],
# [1, 0, 0, 0],
# [0, 0, 1, 0],
# [0, 0, 0, 1],
# [0, 0, 1, 0],
# [0, 1, 0, 0]]
欠損値を扱う
これに関してはRubyやNArrayでカスタムに処理するしかなさそうです。
たとえば欠損値が0で、その部分を全体の平均で埋める場合はこんな感じでしょうか。
total = samples.sum
zero_idx = samples.eq(0).where
mean_value = total / (sample.size - zero_idx.size)
samples[zero_idx] = mean_value
モデルを作成する (Create Your Model)
教師あり学習の推定器 (Supervised Learning Estimators)
k近傍法 (k-NN) (k-Nearest Neighbors)



Rumale::NearestNeighbors::KNeighborsClassifier.new(n_neighbors: 5)
Rumale::NearestNeighbors::KNeighborsRegressor.new(n_neighbors: 5)
- n_neighbors : The number of neighbors.
線形モデル (Linear Regression)
Rumale::LinearModel::LinearRegression.new(
fit_bias: # (Boolean) — The flag indicating whether to fit the bias term.
bias_scale: # (Float) — The scale of the bias term.
max_iter: # (Integer) — The maximum number of iterations.
batch_size: # (Integer) — The size of the mini batches.
optimizer: # (Optimizer) — The optimizer to calculate adaptive learning rate. If nil is given, Nadam is used.
random_seed: # (Integer) — The seed value using to initialize the random generator.
)
optimizer: AdaGrad, Adam, Nadam, RMSProp, SGD, goldFin
リッジ回帰 (Ridge Regression)
L2正則化
Rumale::LinearModel::Ridge.new(
reg_param: # (Float) — The regularization parameter.
fit_bias: # (Boolean) — The flag indicating whether to fit the bias term.
bias_scale: # (Float) — The scale of the bias term.
max_iter: # (Integer) — The maximum number of iterations.
batch_size: # (Integer) — The size of the mini batches.
optimizer: # (Optimizer) — The optimizer to calculate adaptive learning rate. If nil is given, Nadam is used.
random_seed: # (Integer) — The seed value using to initialize the random generator.
)
ラッソ回帰 (Lasso Regression)
L1正則化
Rumale::LinearModel::Lasso.new(
reg_param: # (Float) — The regularization parameter.
fit_bias: # (Boolean) — The flag indicating whether to fit the bias term.
bias_scale: # (Float) — The scale of the bias term.
max_iter: # (Integer) — The maximum number of iterations.
batch_size: # (Integer) — The size of the mini batches.
optimizer: # (Optimizer) — The optimizer to calculate adaptive learning rate. If nil is given, Nadam is used.
random_seed: # (Integer) — The seed value using to initialize the random generator.
)
ロジスティック回帰 (Logistic Regression)
Rumale::LinearModel::LogisticRegression.new(
reg_param: # (Float) — The regularization parameter.
fit_bias: # (Boolean) — The flag indicating whether to fit the bias term.
bias_scale: # (Float) — The scale of the bias term. If fit_bias is true, the feature vector v becoms [v; bias_scale].
max_iter: # (Integer) — The maximum number of iterations.
batch_size: # (Integer) — The size of the mini batches.
optimizer: # (Optimizer) — The optimizer to calculate adaptive learning rate. If nil is given, Nadam is used.
random_seed: # (Integer) — The seed value using to initialize the random generator.
)
線形サポートベクトルマシン (Support Vector Machine)
svc = Rumale::LinearModel::SVC.new(
reg_param: # (Float) — The regularization parameter.
fit_bias: # (Boolean) — The flag indicating whether to fit the bias term.
bias_scale: # (Float) — The scale of the bias term.
max_iter: # (Integer) — The maximum number of iterations.
batch_size: # (Integer) — The size of the mini batches.
probability: # (Boolean) — The flag indicating whether to perform probability estimation.
optimizer: # (Optimizer) — The optimizer to calculate adaptive learning rate. If nil is given, Nadam is used.
random_seed: # (Integer) — The seed value using to initialize the random generator.
)
ナイーブベイズ (Naive Bayes)
- GaussianNB
- BernoulliNB
- MultinomialNB
Rumale::NaiveBayes::GaussianNB.new
Rumale::NaiveBayes::BernoulliNB.new(smoothing_param: 1.0, bin_threshold: 0.0)
Rumale::NaiveBayes::MultinomialNB.new(smoothing_param: 1.0)
決定木 (Decision Tree)
Rumale::Tree::DecisionTreeClassifier.new(
criterion: # (String) — The function to evaluate spliting point. Supported criteria are ‘gini’ and ‘entropy’.
max_depth: # (Integer) — The maximum depth of the tree. If nil is given, decision tree grows without concern for depth.
max_leaf_nodes: # (Integer) — The maximum number of leaves on decision tree. If nil is given, number of leaves is not limited.
min_samples_leaf: # (Integer) — The minimum number of samples at a leaf node.
max_features: # (Integer) — The number of features to consider when searching optimal split point. If nil is given, split process considers all features.
random_seed: # (Integer) — The seed value using to initialize the random generator. It is used to randomly determine the order of features when deciding spliting point.
)
Rumale::Tree::DecisionTreeRegressor.new(
criterion: # (String) —The function to evaluate spliting point. Supported criteria are ‘mae’ and ‘mse’.
max_depth: # (Integer) —The maximum depth of the tree. If nil is given, decision tree grows without concern for depth.
max_leaf_nodes: # (Integer) —The maximum number of leaves on decision tree. If nil is given, number of leaves is not limited.
min_samples_leaf: # (Integer) —The minimum number of samples at a leaf node.
max_features: # (Integer) —The number of features to consider when searching optimal split point. If nil is given, split process considers all features.
random_seed: # (Integer) —The seed value using to initialize the random generator. It is used to randomly determine the order of features when deciding spliting point.
)
ExtraTree
ランダムフォレスト (Random Forest)
Rumale::Ensemble::RandomForestClassifier.new(
n_estimators: # (Integer) —The numeber of decision trees for contructing random forest.
criterion: # (String) —The function to evalue spliting point. Supported criteria are ‘gini’ and ‘entropy’.
max_depth: # (Integer) —The maximum depth of the tree. If nil is given, decision tree grows without concern for depth.
max_leaf_nodes: # (Integer) —The maximum number of leaves on decision tree. If nil is given, number of leaves is not limited.
min_samples_leaf: # (Integer) —The minimum number of samples at a leaf node.
max_features: # (Integer) —The number of features to consider when searching optimal split point. If nil is given, split process considers all features.
random_seed: # (Integer) —The seed value using to initialize the random generator. It is used to randomly determine the order of features when deciding spliting point.
)
Rumale::Ensemble::RandomForestRegressor.new(
n_estimators: # (Integer) —The numeber of decision trees for contructing random forest.
criterion: # (String) —The function to evalue spliting point. Supported criteria are ‘gini’ and ‘entropy’.
max_depth: # (Integer) —The maximum depth of the tree. If nil is given, decision tree grows without concern for depth.
max_leaf_nodes: # (Integer) —The maximum number of leaves on decision tree. If nil is given, number of leaves is not limited.
min_samples_leaf: # (Integer) —The minimum number of samples at a leaf node.
max_features: # (Integer) —The number of features to consider when searching optimal split point. If nil is given, split process considers all features.
random_seed: # (Integer) —The seed value using to initialize the random generator. It is used to randomly determine the order of features when deciding spliting point.
)
AdaBoost (Adaptive Boosting)
Rumale::Ensemble::AdaBoostClassifier.new(
n_estimators: # (Integer) —The numeber of decision trees for contructing random forest.
criterion: # (String) —The function to evalue spliting point. Supported criteria are ‘gini’ and ‘entropy’.
max_depth: # (Integer) —The maximum depth of the tree. If nil is given, decision tree grows without concern for depth.
max_leaf_nodes: # (Integer) —The maximum number of leaves on decision tree. If nil is given, number of leaves is not limited.
min_samples_leaf: # (Integer) —The minimum number of samples at a leaf node.
max_features: # (Integer) —The number of features to consider when searching optimal split point. If nil is given, split process considers all features.
random_seed: # (Integer) —The seed value using to initialize the random generator. It is used to randomly determine the order of features when deciding spliting point.
)
Rumale::Ensemble::AdaBoostRegressor.new(
n_estimators: # (Integer) —The numeber of decision trees for contructing random forest.
threshold: # (Float) —The threshold for delimiting correct and incorrect predictions. That is constrained to [0, 1]
exponent: # (Float) —The exponent for the weight of each weak learner.
criterion: # (String) —The function to evalue spliting point. Supported criteria are ‘gini’ and ‘entropy’.
max_depth: # (Integer) —The maximum depth of the tree. If nil is given, decision tree grows without concern for depth.
max_leaf_nodes: # (Integer) —The maximum number of leaves on decision tree. If nil is given, number of leaves is not limited.
min_samples_leaf: # (Integer) —The minimum number of samples at a leaf node.
max_features: # (Integer) —The number of features to consider when searching optimal split point. If nil is given, split process considers all features.
random_seed: # (Integer) —The seed value using to initialize the random generator. It is used to randomly determine the order of features when deciding spliting point.
)
教師なし学習の推定器 (Unsupervised Learning Estimators)
主成分分析 (PCA)
 

Rumale::Decomposition::PCA.new(
n_components: # (Integer) —The number of principal components.
max_iter: # (Integer) —The maximum number of iterations.
tol: # (Float) —The tolerance of termination criterion.
random_seed: # (Integer) —The seed value using to initialize the random generator.
)
非負値行列因子分解 (NMF)

Rumale::Decomposition::NMF.new(
n_components: # (Integer) —The number of components.
max_iter: # (Integer) —The maximum number of iterations.
tol: # (Float) —The tolerance of termination criterion.
eps: # (Float) —A small value close to zero to avoid zero division error.
random_seed: # (Integer) —The seed value using to initialize the random generator.
)
t-SNE

Rumale::Manifold::TSNE.new(
n_components: # (Integer) —The number of dimensions on representation space.
perplexity: # (Float) —The effective number of neighbors for each point. Perplexity are typically set from 5 to 50.
metric: # (String) —The metric to calculate the distances in original space. If metric is 'euclidean', Euclidean distance is calculated for distance in original space. If metric is 'precomputed', the fit and fit_transform methods expect to be given a distance matrix.
init: # (String) —The init is a method to initialize the representaion space. If init is 'random', the representaion space is initialized with normal random variables. If init is 'pca', the result of principal component analysis as the initial value of the representation space.
max_iter: # (Integer) —The maximum number of iterations.
tol: # (Float) —The tolerance of KL-divergence for terminating optimization. If tol is nil, it does not use KL divergence as a criterion for terminating the optimization.
verbose: # (Boolean) —The flag indicating whether to output KL divergence during iteration.
random_seed: # (Integer) —The seed value using to initialize the random generator.
)
k平均法 (KMeans)

Rumale::Clustering::KMeans.new(
n_clusters: # (Integer) —The number of clusters.
init: # (String) —The initialization method for centroids (‘random’ or ‘k-means++’).
max_iter: # (Integer) —The maximum number of iterations.
tol: # (Float) —The tolerance of termination criterion.
random_seed: # (Integer) —The seed value using to initialize the random generator.
)
DBSCAN (Density-based spatial clustering of applications with noise)
Rumale::Clustering::DBSCAN.new(
eps: # (Float) —The radius of neighborhood.
min_samples: # (Integer) —The number of neighbor samples to be used for the criterion whether a point is a core point.
)
混合ガウスモデル (Gaussian Mixture Model, GMM)
Rumale::Clustering::GaussianMixture.new(
n_clusters: # (Integer) —The number of clusters.
init: # (String) —The initialization method for centroids: # ('random' or 'k-means++').
max_iter: # (Integer) —The maximum number of iterations.
tol: # (Float) —The tolerance of termination criterion.
reg_covar: # (Float) —The non-negative regularization to the diagonal of covariance.
random_seed: # (Integer) —The seed value using to initialize the random generator.
)
モデルを学習させる (Model Fitting)
model.fit(samples, labels)
model.fit(samples)
model.fit_transform(x)
予測 (Prediction)
y_pred = model.predict(samples)
モデルを評価する (Evaluate Model’s Performance)
modelはBase::RegressorやBase::Classifierをincludeしており、それぞれscoreメソッドでEvaluationMeasureを呼んでいる。
クラス分類の評価指標 (Classification Metrics)
Accuracy Score

evaluator = Rumale::EvaluationMeasure::Accuracy.new
puts evaluator.score(ground_truth, predicted)
回帰の評価指標 (Regression Metrics)
平均絶対誤差 (Mean Absolute Error, MAE)
evaluator = Rumale::EvaluationMeasure::MeanAbsoluteError.new
puts evaluator.score(ground_truth, predicted)
平均二乗誤差 (Mean Squared Error)
evaluator = Rumale::EvaluationMeasure::MeanSquaredError.new
puts evaluator.score(ground_truth, predicted)
R2 Score
決定係数 (coefficient of determination)と言うらしい。回帰モデルの予想の正確さを測る指標
evaluator = Rumale::EvaluationMeasure::R2Score.new
puts evaluator.score(ground_truth, predicted)
クラスタリングの評価指標 (Clustering Metrics)
Adjusted Rand Index
evaluator = Rumale::EvaluationMeasure::AdjustedRandScore.new
puts evaluator.score(ground_truth, predicted)
交差検証 (Cross-Validation)
svc = Rumale::LinearModel::SVC.new
kf = Rumale::ModelSelection::StratifiedKFold.new(n_splits: 5)
cv = Rumale::ModelSelection::CrossValidation.new(estimator: svc, splitter: kf)
report = cv.perform(samples, labels)
mean_test_score = report[:test_score].inject(:+) / kf.n_splits
モデルを調整する (Tune Your Model)
グリッドサーチ (Grid Search)

# ランダムフォレスト
rfc = Rumale::Ensemble::RandomForestClassifier.new(random_seed: 1)
# パラメータ
pg = { n_estimators: [5, 10], max_depth: [3, 5], max_leaf_nodes: [15, 31] }
# 層化 k 分割交差検証
kf = Rumale::ModelSelection::StratifiedKFold.new(n_splits: 5)
# グリッドサーチ
gs = Rumale::ModelSelection::GridSearchCV.new(estimator: rfc, param_grid: pg, splitter: kf)
gs.fit(samples, labels)
# 結果
p gs.cv_results
p gs.best_params
パイプラインを使用する例
rbf = Rumale::KernelApproximation::RBF.new(random_seed: 1)
svc = Rumale::LinearModel::SVC.new(random_seed: 1)
pipe = Rumale::Pipeline::Pipeline.new(steps: { rbf: rbf, svc: svc })
pg = { rbf__gamma: [32.0, 1.0], rbf__n_components: [4, 128], svc__reg_param: [16.0, 0.1] }
kf = Rumale::ModelSelection::StratifiedKFold.new(n_splits: 5)
gs = Rumale::ModelSelection::GridSearchCV.new(estimator: pipe, param_grid: pg, splitter: kf)
gs.fit(samples, labels)
p gs.cv_results
p gs.best_params
パイプライン
一連の処理ステップをまとめることができる。
rbf = Rumale::KernelApproximation::RBF.new(gamma: 1.0, n_coponents: 128, random_seed: 1)
svc = Rumale::LinearModel::SVC.new(reg_param: 1.0, fit_bias: true, max_iter: 5000, random_seed: 1)
pipeline = Rumale::Pipeline::Pipeline.new(steps: { trs: rbf, est: svc })
pipeline.fit(training_samples, traininig_labels)
results = pipeline.predict(testing_samples)
参考資料
- Rumale公式リファレンス
- 書籍『Pythonではじめる機械学習』
- Python For Data Science Cheat Sheet Scikit-Learn
- Sklearnのpreprocessingの全メソッドを解説
アヒルちゃんについて

Rumaleの作者によると、みにくいアヒルの子の定理にちなんで公式キャラクターがアヒルになったそうです。1
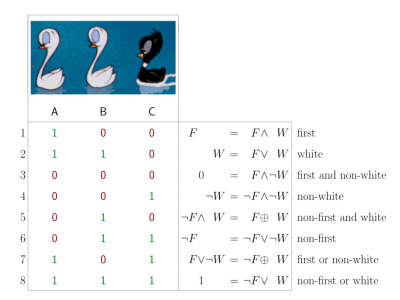
(みにくいアヒルの子の定理 任意の二匹のアヒルの子の類似性は等しい。画像:Wikipediaより)