Azure で提供しているHDInsight Spark は、現在のところ 1.5.2、1.6.2、1.6.3、2.0.2、2.1.0 (プレビュー) がリリースされています。各ノードは全てLinux(Ubuntu)の仮想VMが使われておりSparkのバージョンにより、Ubuntu のバージョンは少しづつ異なります。なお対応する仮想VM はこちらのリンクHDInsight の価格を参照いただきたいのですが、注意点としまして、
デプロイ後は仮想VMの種類を変更することができない。
コスト削減のためにAシリーズの低価格のものを使用すると、パフォーマンスが出ない恐れがあるので、ヘッドノード・ワーカーノード共にデフォルト以上の性能の仮想VMを推奨します。(ここでデフォルトとはポータルでデプロイ時にあらかじめセットされているVMタイプのことを指します)
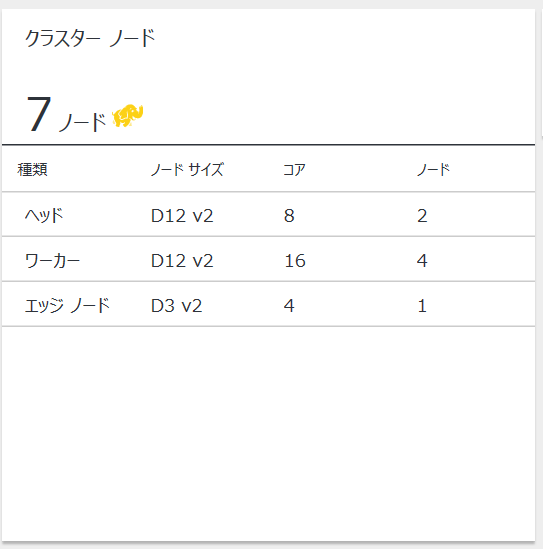
ちなみにデプロイすると、以下のような物理構成で環境が構築されます。

以下にそれぞれの部分について説明をすると、
ヘッドノード
ヘッドノード(マスターノードとも言います)は、デフォルトで2重化されており、主にクラスタやSpark ジョブの管理・制御用のコンポーネントや、Jupyter のようなアプリケーションがインストールされています。それぞれのモジュールは様々にいろんな機能を提供しているので、ここでは詳細な説明を避けますが、主に以下のコンポーネントが含まれます。
- Resource Manager (YARN)
- NameNode(HDFS)
- Hive Metastore
- HiveServer2
- App Timeline Server
- History Server
- Ambari Metrics Collector / Metrics Monitor
- Thrift サーバ
- Jupyter
- Livy
- Oozie など。
ヘッドノードは2重化されているため、Resouce Manager やNameNode はActive/Stanby 構成を取っており冗長化しています。Hive Metastore と HiveServer2 は両方のノードでActive な状態で動作しています。またApp Timeline Server とHistory Server は両方のノードにインストールされていますが、Ambari Metrics Collector が動作している方のノードのみで動作するようになっています。
ワーカーノード
ワーカーノードは実際にSpark ジョブが実際に動作する仮想VM なので、ジョブ実行に必要なものがインストールされており、ヘッドノードに比べると、以下のような必要最小限のコンポーネントのみが含まれます。
- NodeManager(YARN)
- DataNode(HDFS)
- Metrics Monitor(Ambari)
- Zookeeper
Zookeeper
Zookeeper は、分散環境での設定情報の集中管理や、リソースの競合を防止するための機構を提供したり、自動フェイルオーバーの提供などを行います。上述のResouce Manager(YARN)やNameNode(HDFS)のActive/Stanby 構成はZookeeperによるものです。ちなみにZookeeperには、A シリーズの仮想VM が使用されているのですが、VM タイプをデプロイ時やデプロイ後に変更することができません。またデプロイすると3台のZookeeperが構築されますが、台数を増やすことも現状サポートされておりません。ちなみにSpark のZookeeper は課金対象となっていないです。
ゲートウェイノード
Azure ポータルから確認することはできませんが、2台のGateway ノードというものが裏で存在しています。HDInsight Spark をデプロイすると各ノードの仮想VM は仮想ネットワーク上に構成されるようになり、それぞれのノードの通信は仮想ネットワークを介して行われることになります。ただしユーザは直接ノードにアクセスすることができず、Gateway を介してノードへのアクセスが許可されています。外部からのアクセスはデフォルトではヘッドノードへのSSH とAmbari のWEB UI へのアクセスのみが許可されていますが、アクセス時のユーザ認証やリクエストのフォワーディングはGateway によって自動制御されています。Gateway は外からは見えないためユーザは一切管理を行う必要がありません。
Azure Blob ストレージ
Blob ストレージは、HDInsight Spark のデフォルトストレージとして使用されています。IFとしてはHDFS ですが中身がBlob ストレージとなっています。そのため、SSH でノードにログインしてhadoop コマンドでストレージの中身にアクセスすることも可能となっています。普通のSpark のようにHDFS を構築することも可能ではありますが、Azure 上での取り扱いの良さを考慮して、Blob ストレージがデフォルトとして採用されていると思われ、開発時などはAzure Storage Explorer が利用できることから非常に重宝しています。
エッジノード
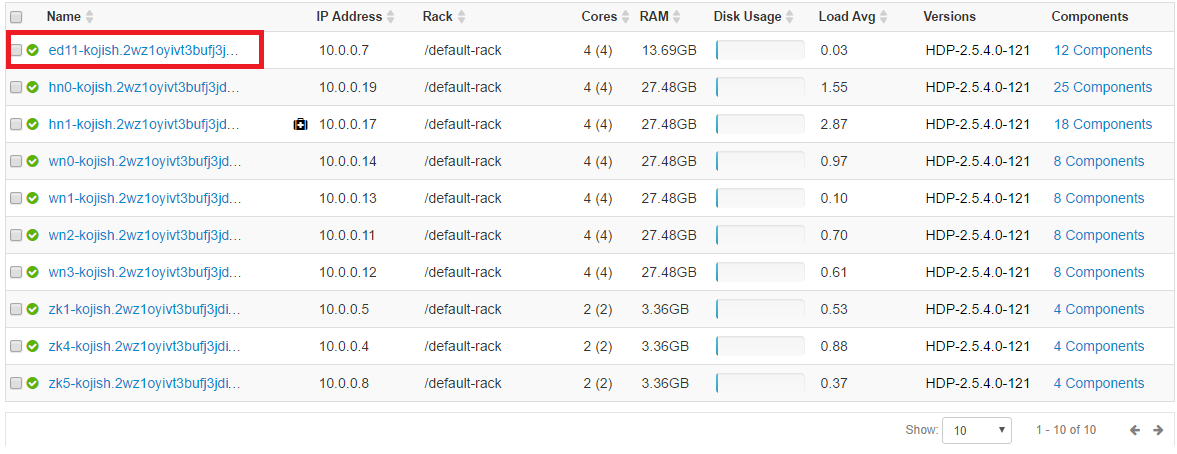
最後にエッジノード(任意で追加可能)というものがあります。例えばHDInsight のクラスターに作業用のLinux VM や何がしかのアプリを動作させるためのノードを追加したいことがあるかと思います。個別にLinux の仮想VM を立てても良いのですが、エッジノードとしてVM を追加すると、デフォルトで Spark2 Client やYARN Client などのクライアントツールが事前にインストールされたVM をクラスタへ追加することが可能になります。詳細はHDInsight での空のエッジ ノードの使用を参照ください。なおエッジノードを追加すると、下記のようにポータルやAmbari(赤枠内)からもノードの情報が見えるようになります。