よくドキュメントはOfficeで書くと思うんですが、その中でもExcelって、セルの位置とか諸々あって翻訳をする必要性が出た時に色々と苦労していました。
市販のソフトを使うものいいのですが、ライセンスの制限やらで結局は決まった1台でしか翻訳が出来ない、、、という事態に陥りがちです。
PandasでExcelを読み込むことできる、という記事を見つけたので、実際にPandasで仕様書っぽいExcelを読み込んだ際に、それは翻訳に耐えられる中身(例えばそのままAmazon Translateにかけられるか?など)になっているのか、確認してみました。
前提
- 下記のURLにある仕様書(試験成績書)を翻訳対象とします。(これができれば、ある程度複雑な仕様書も翻訳できるのではなかろうか、、、という期待の下)
https://thinkit.co.jp/article/140/3?page=0%2C1 - Excelの読み込みにはPandasを利用します
- Pandasの読み込み結果が良さそうだったら、Amazon Translateにそのままかけてみてどうなるか、検証します。
Excelの読み書き
こちらのページを参考にしました。
[note.nkmk.me]
https://note.nkmk.me/python-pandas-read-excel/
https://note.nkmk.me/python-pandas-to-excel/
事前インストール
読み書きをするために、以下をインストールしておきます。
$ pip install xlrd
# 読み込み用
$ pip install xlwt
$ pip install openpyxl
# 書き込み用
読み込んだExcelシートをそのままExcelとして出力してみる
とりあえずまずはそのまま読み込ませてみます。ただしヘッダやインデックスは指定したくないので、こんな実装で。
import os
import sys
sys.path.append(os.path.join(os.path.abspath(os.path.dirname(__file__)), 'libs'))
import pandas as pd
import openpyxl
def main():
# Read excel file with pandas
df = pd.read_excel('data.xls', sheet_name='test', header=None)
# Write excel file
df.to_excel('pandas_to_excel.xlsx', sheet_name='new_test', index=False, header=False)
if __name__ == '__main__':
main()
これで出力できた結果が以下。まずは読み込み時のExcel。いい感じにレイアウトや書式設定がされています。
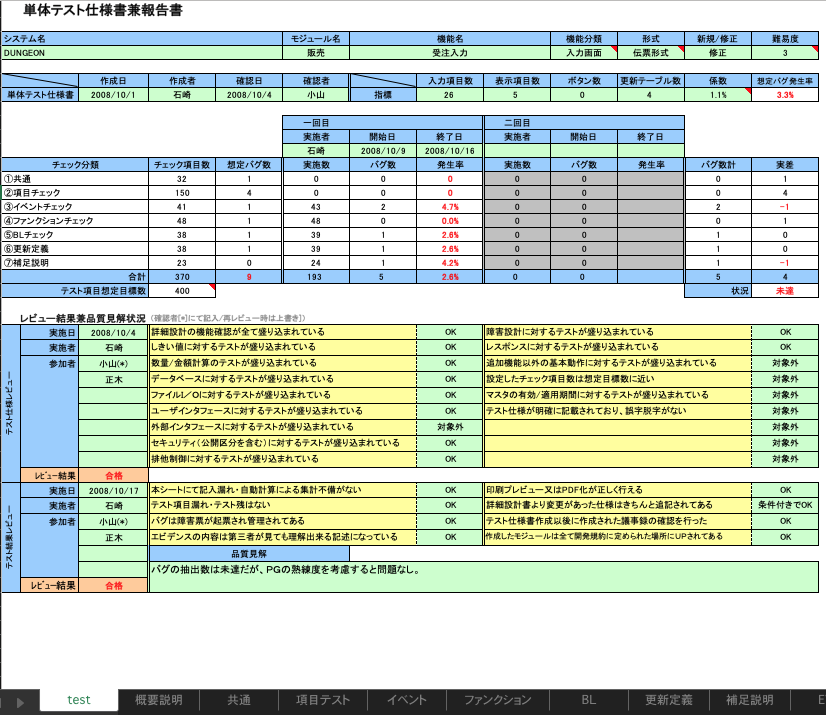
これを読み込ませてそのまま出力した結果がこちら。
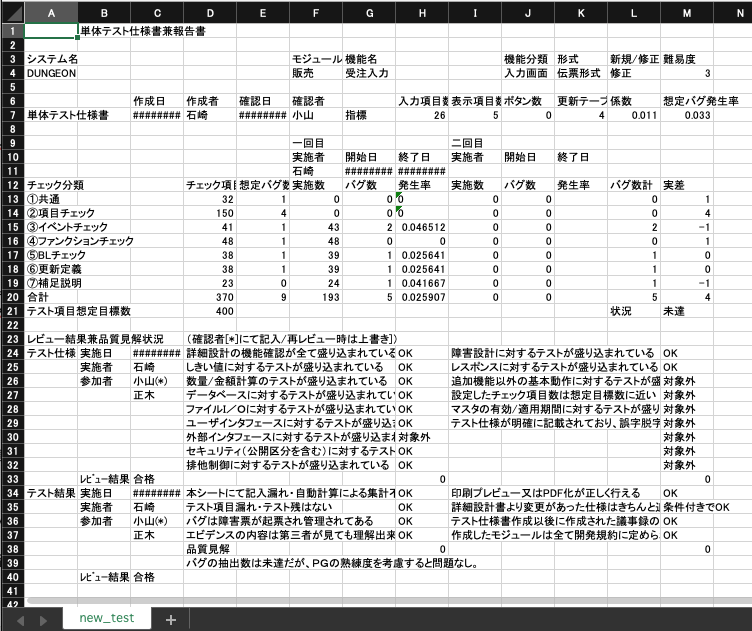
書式の設定は当たり前ですが保持されず、ただし書き込み位置はオリジナルと同じようです。これなら「中身だけ翻訳」ということができそうですね。
DataFrameをAmazon Translateにかけてみる
次に、実際に読み込めたデータをAmazon Translateにかけてみます。「日本語→英語」で変換をかけられるようにし、boto3を利用することとします。
import boto3
REGION = 'us-east-1'
SRC_LANG = 'ja'
DIST_LANG = 'en'
translate = boto3.client(service_name='translate', region_name=REGION, use_ssl=True)
def translate_df(df):
translate = boto3.client('translate', region_name=REGION)
response = df.applymap(lambda c: translate.translate_text(Text=c, SourceLanguageCode=SRC_LANG, TargetLanguageCode=DIST_LANG)['TranslatedText'] if c != '' and type(c) == str else c)
return response
Amazon Translateを利用するところで、Lambda式を使っています。以下のような流れになっています。
- (事前に空白でNaNを変換している)空白ではなく、かつ型が文字列の場合(DatetimeはTranslateできない)、Amazon Translateを呼び出す。
- 戻り値のうち、翻訳したテキストのみを取り出すための指定
['TranslatedText']を実装している(詳細は下記)
Amazon Translateを呼び出すと、以下のようなJSONで結果が返ってくるので、TranslatedTextのみを受け取れるようにしています。
{
"TranslatedText": "Unit Test Specifications and Report",
"SourceLanguageCode": "ja",
"TargetLanguageCode": "en",
"ResponseMetadata": {
"RequestId": "daabb017-10c4-11e9-b617-d373f8e7a2f8",
"HTTPStatusCode": 200,
"HTTPHeaders": {
"content-type": "application/x-amz-json-1.1",
"date": "Sat, 05 Jan 2019 08:35:28 GMT",
"x-amzn-requestid": "daabb017-10c4-11e9-b617-d373f8e7a2f8",
"content-length": "108",
"connection": "keep-alive"
},
"RetryAttempts": 0
}
}
さて、全体の実装はこんな感じになりました。
import os
import sys
sys.path.append(os.path.join(os.path.abspath(os.path.dirname(__file__)), 'libs'))
import pandas as pd
import openpyxl
import boto3
REGION = 'us-east-1'
SRC_LANG = 'ja'
DIST_LANG = 'en'
translate = boto3.client(service_name='translate', region_name=REGION, use_ssl=True)
def translate_df(df):
translate = boto3.client('translate', region_name=REGION)
response = df.applymap(lambda c: translate.translate_text(Text=c, SourceLanguageCode=SRC_LANG, TargetLanguageCode=DIST_LANG)['TranslatedText'] if c != '' and type(c) == str else c)
return response
def main():
# Read excel file with pandas
df = pd.read_excel('data.xls', sheet_name='test', header=None)
df = df.fillna('')
df_new = translate_df(df)
# Write excel file
df_new.to_excel('pandas_to_excel.xlsx', sheet_name='new_test', index=False, header=False)
if __name__ == '__main__':
main()
出来上がりのExcelは?
いい感じにポジションは保ったままで翻訳されたようです。何気に日本人の個人名もきちんとローマ字に翻訳されているのはすごいですね。この辺はAWSの力、というやつか。
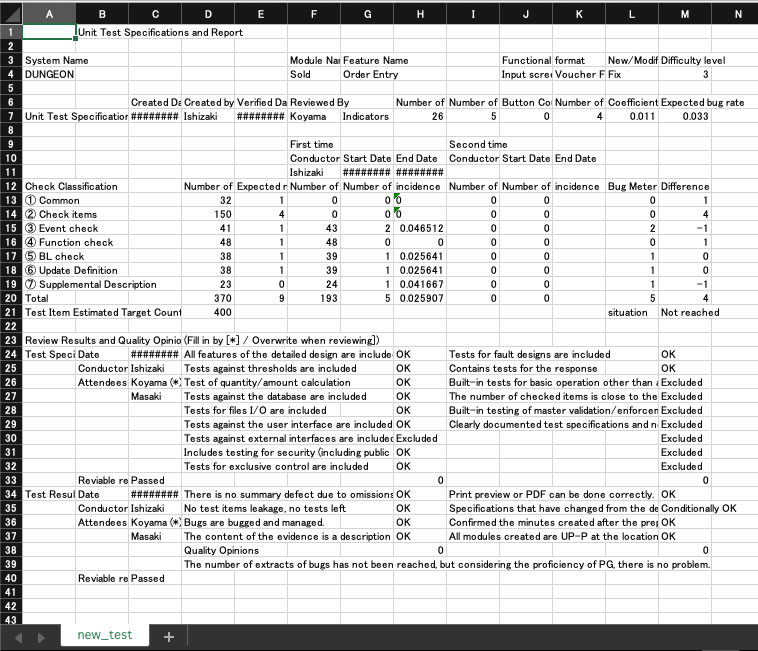
これを元のExcelの書式を設定したものにコピーしてみました。
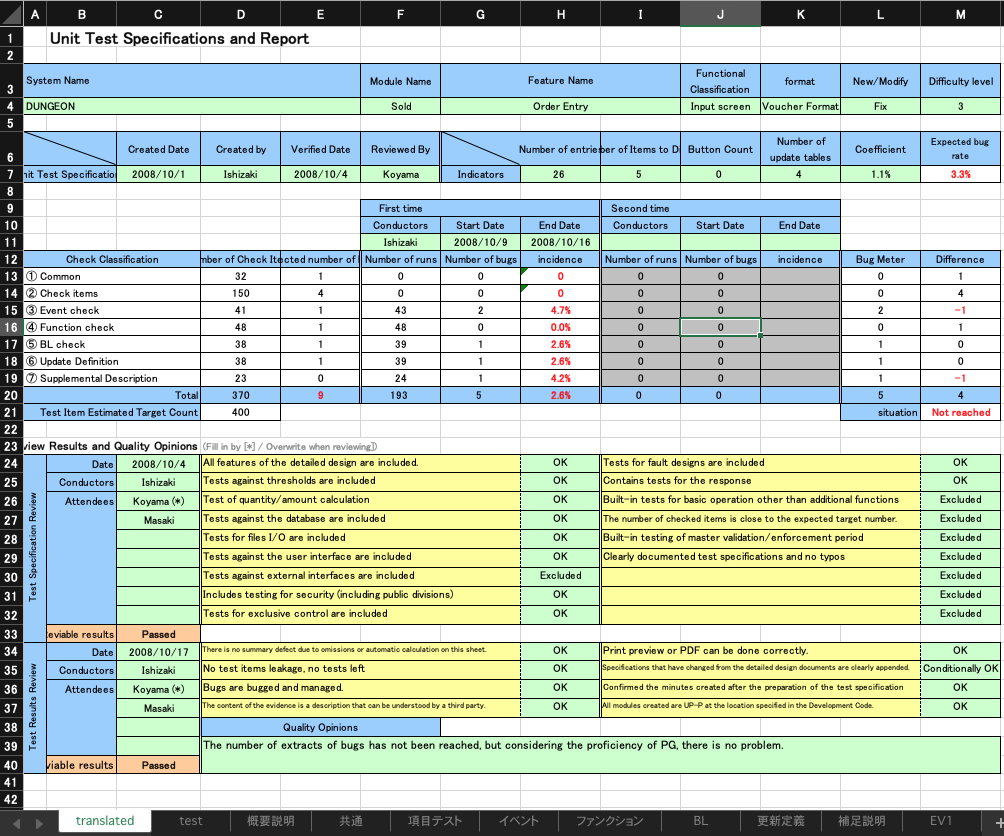
細かく一つ一つ見ていくと怪しい翻訳もありますが(^^;このレベルなら許容範囲内かな、、、と。
| No | 日本語 | 英語 |
|---|---|---|
| 1 | 詳細設計の機能確認が全て盛り込まれている | All features of the detailed design are included. |
| 2 | 本シートにて記入漏れ・自動計算による集計不備がない | There is no summary defect due to omissions or automatic calculation on this sheet. |
| 3 | バグは障害票が起票され管理されてある | Bugs are bugged and managed. |
| 4 | エビデンスの内容は第三者が見ても理解出来る記述になっている | The content of the evidence is a description that can be understood by a third party. |
いくつか拾ってみました。ぱっと見No.3は「ちょっと何言ってるかわからない状態」ですが、それ以外は、まぁ言いたいことはわかる、レベルです。IT業界のドキュメントでここまでできるのはなかなかですね。
まとめ
思った以上にAmazon Translateの精度が高かったことと、PandasがExcelを柔軟にDataFrameに変換してくれる便利さに驚きました。うまくWebサービスとして利用できるようにすれば、誰でもどこからでも変換できるサービスにできそうですね。(あとはAmazon Translateの利用料金次第。S3のようにリクエスタ支払いの指定ができれば、一般公開しても面白そうなんですがね。)
Amazon Translate利用料金
https://aws.amazon.com/jp/translate/pricing/