AWS IoT Analyticsをあまり利用したことがなかったので、利用した備忘録。ただ色々といじってみたかったので本来のIoT Analyticsの用途からは離れていることは受け入れる感じで。
こんな感じのことをやりたい
こういうのを実現するためにAWS IoT Analyticsは使えるんじゃないかな、と。(向いているとは言っていない)
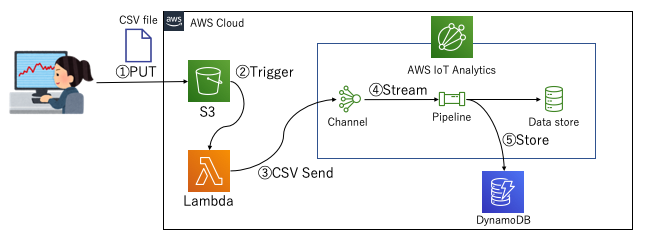
- とあるバケットにCSVファイルが置かれる
- CSVファイル配置をトリガとしてLambdaがキックされ、中身をAWS IoT AnalyticsのChannelに送付する。(この際渡す量をAPI側で調整してあげれば、Pipeline内の処理性能はある一定以上は不要になるので、サイジングをシビアに考える必要がない)
- あとはStream処理でPipelineの中でやりたい処理を実施する。(今回はDynamoDBへのデータ格納)
Pipeline(AWS IoT Analytics)はVPCの中でLambda処理を動かすことはできないようなので、PipelineのLambdaからVPC内に配置したデータストアへのデータ格納はできないようですが、とりあえずこれができるだけでも色々とメリットを得られるので良さそうです。
- Channelはデータの受信したデータをバックアップとして保持しておくことが可能。それを用いてPipeline処理を再度実施することもできる。(例えばPipeline処理を更新したので再度同じデータを通しておく、と言うことも可能。この際データストアに保持されるデータは追加されるのではなく上書きされる仕組みも個人的には嬉しい)
- Pipelineを通したデータの一覧をデータセットとして確認することができる。なんならデータセットを利用して他の処理(AWS Batchなどを使った定期的な重めの処理)を実行することも可能。
全体の成果物は以下
とりあえず以降に説明する内容の成果物は以下に保存
データ配置後トリガで起動するLambdaの実装
早速実装に取り掛かります。図で言うところの②のトリガが発生した以降に起動されるLambdaの実装はこんな感じになります。
def convert_from_csv_to_json(file_path, bucket_name, header=False):
df = pd.read_csv(file_path)
tmp_json ={}
if header:
tmp_json = df.to_json(orient='records')
else:
tmp_json = df.to_json(orient='values')
result_json_array = []
for ele_json in json.loads(tmp_json):
logger.info(ele_json)
result_json = {}
result_tmp_json = {}
result_tmp_json['s3_bucket'] = bucket_name
result_tmp_json['data'] = ele_json
result_json['messageId'] = str(ele_json['account_number'])
result_json['payload'] = json.dumps(result_tmp_json)
result_json_array.append(result_json)
return result_json_array
def send_data_lambda(event, context):
bucket_str = event['Records'][0]['s3']['bucket']['name']
bucket = s3_client.Bucket(bucket_str)
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
file_path = TMP_PATH + key
os.makedirs(os.path.dirname(file_path), exist_ok=True)
bucket.download_file(key, file_path)
json_array = convert_from_csv_to_json(file_path, bucket_str, True)
for json_sub in chunked(json_array, DATA_BATCH_SIZE):
response = iot_analytics_client.batch_put_message(
channelName = 'csv_import_sample_channel',
messages = json_sub
)
return 'All data sending finished.'
だいぶ雑なつくりですが、これでChannelに対してCSVデータを送付することができます。今回扱っているデータはElasticsearchのサンプルで使われるデータのaccounts.csvを利用しています。こんな感じのデータです。
account_number,address,age,balance,city,email,employer,firstname,gender,lastname,state
1,880 Holmes Lane,32,39225,Brogan,amberduke@pyrami.com,Pyrami,Amber,M,Duke,IL
6,671 Bristol Street,36,5686,Dante,hattiebond@netagy.com,Netagy,Hattie,M,Bond,TN
13,789 Madison Street,28,32838,Nogal,nanettebates@quility.com,Quility,Nanette,F,Bates,VA
18,467 Hutchinson Court,33,4180,Orick,daleadams@boink.com,Boink,Dale,M,Adams,MD
これをそれぞれIoT Analyticsに流し込むことになりますが、IoT Analytics側は1データずつ送付されるとそれだけでPipelineの起動数が多すぎになってしまうため、Batch Sizeを調整してまとめてStream処理を走らせられるようにIoT AnalyticsのPipeline部分に設定をしています。
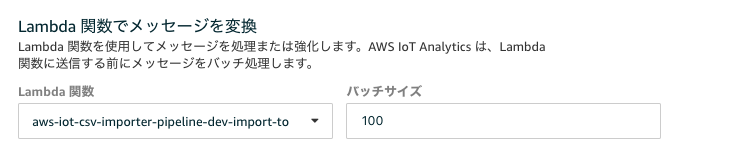
これでデータが送られてきた際、Pipelineに100データずつ流し込んでくれるようになります。
Pipelineで呼び出されるLambda処理
無事Channelへのデータ送付がされたら、次にPipeline処理が呼ばれます。このようなコードを書きました。
def store_data_lambda(event, context):
logger.info("Start store data: {}".format(event))
bucket = s3_client.Bucket(event[0]['s3_bucket'])
key = CONF_PATH
file_path = TMP_PATH + key
os.makedirs(os.path.dirname(file_path), exist_ok=True)
bucket.download_file(key, file_path)
conf_file = open(file_path, 'r')
conf_json = json.load(conf_file)
logger.info(conf_json)
result_json_array = []
tmp_json = {}
for ev in event:
tmp_json = {}
for key, value in ev['data'].items():
if key in conf_json.keys():
tmp_json[conf_json[key]] = value
result_json_array.append(tmp_json)
ddb_table = ddb_client.Table(DYNAMODB_TABLE)
with ddb_table.batch_writer() as batch:
for item_json in result_json_array:
batch.put_item(
Item=item_json
)
return result_json_array
これで実行結果がDynamoDBに格納され、かつIoT Analyticsの時系列DBにも格納されるようになります。
実際に実行してみた結果
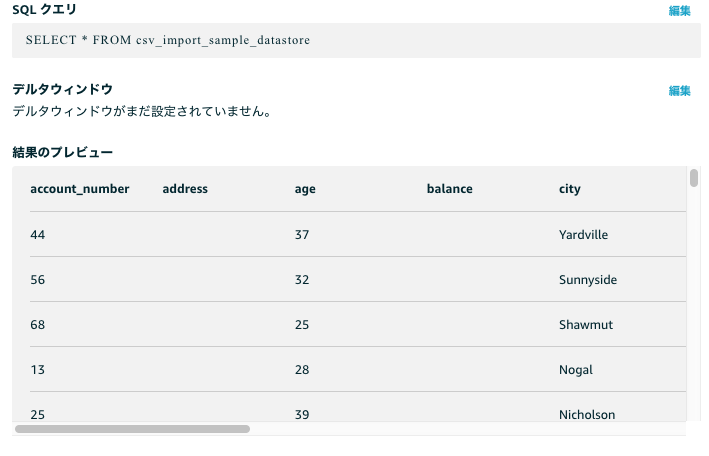
実際にCSVファイルをS3に配置して、この処理を通してみました。IoT Analyticsのデータセット部でクエリを発行することで実施結果が確認できました。(もちろんDynamoDBにもデータは入っていました。)
DynamoDBにも問題なくデータが格納されています。
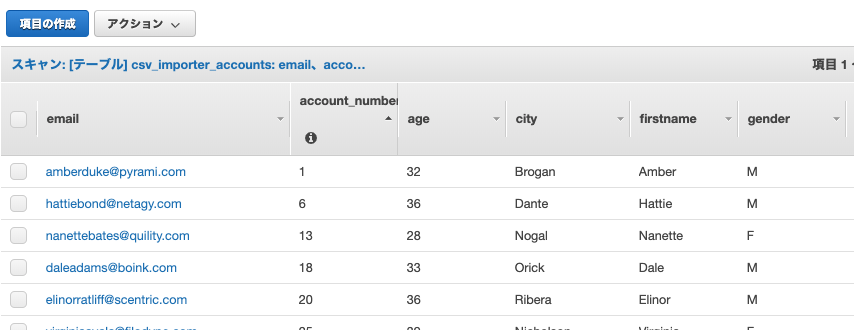
これで無事に処理を通すことができました。
Pipelineの再処理を実施したくなったら?
もしPippeline内の処理を更新した、などで再度データを流したい場合は、AWS IoT Analyticsでポチポチするだけで実現できます。(もちろんCLIで実施することも可能です)

Channelの右側から「メッセージの再処理」を選択します。
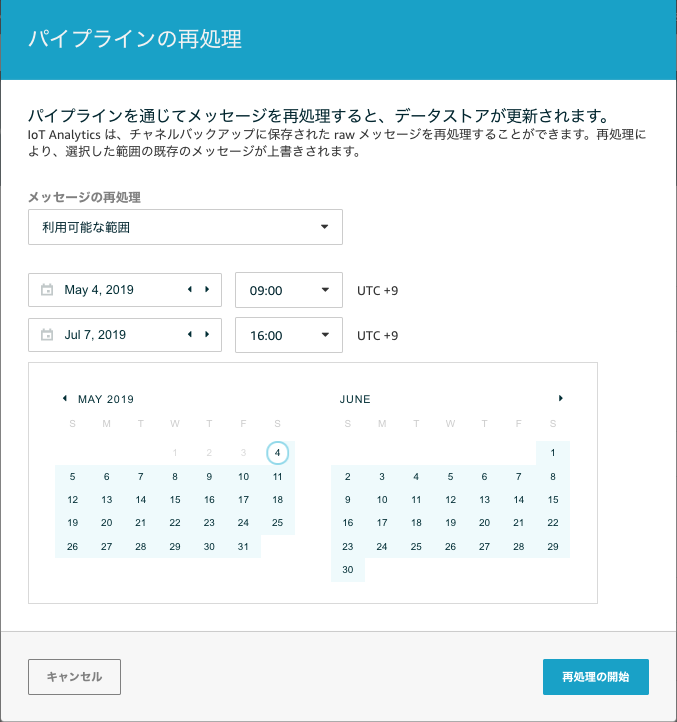
期間でしか絞れないのが惜しいところですが、ここで期間を指定して、その期間でChannelが受信したメッセージをPipelineに再度流すことができます。
ちなみにCLIの場合はstart-pipeline-reprocessingで実施できます。
まとめ
今回はAWS IoT Analyticsが本来期待されている目的とは少し異なる利用法を試してみましたが、IoT ANayticsが持っているメッセージ再処理などの特徴をうまく利用することで、CSVインポート処理を任せてみることもできそうだ、と言うこともわかりました。様々な活用法があるとは思うので、模索していきたいところです。