現状で顔認識をやろうとすると1回の手順では難しく、顔の検出(Detection)と顔の分類(Classification)の2つの手順を踏みます。顔を学習させたモデルが必要であり、今回それも作ります。
使うもの
-
Vision Framework
iOSの画像解析ライブラリ。顔の検出ができます。
さらに目鼻口を検出できたり、矩形の検出や、文字の検出などもできます。 -
CoreML Framework
iOSの機械学習ライブラリ。学習済みのモデルは Apple Developer からダウンロードできます。InceptionV3(Google)、VGG16(Oxford大学)、ResNet50(Microsoft Research)などあります。
https://developer.apple.com/machine-learning/
モデルというと想像できにくいですが、拡張子mlmodelの100MB程度のファイルです。Xcodeのプロジェクトにコピペして、CoreMLからファイル名を指定するだけで使えます。モデルには1000個のカテゴリーが入っており、画像を与えると、1000個の中で強いて言えば何かを分類します。例えばマウスであったり、コンピューターキーボードであったり、PCモニターの前に座った人をバーバーと分類したりします。 -
Turi Create
学習モデルを作成します。TuriはAppleがを2016年に買収しました。
MACでPythonで動かします。これで作ったモデルをiPhoneに送ります。
モデルの作成
手順
- Python2.7をインストールします。PythonパッケージのAnacondaを使いました。
- Turi Createをインストールします。
- トレーニング画像(顔の画像)をいっぱい集めます。
- ターミナルで python model.py を実行します。
- My.mlmodelが作成されます。
import turicreate as tc
import os
data = tc.image_analysis.load_images('train', with_path=True, recursive=True)
data['label'] = data['path'].apply(lambda path: os.path.basename(os.path.dirname(path)))
data.save('my.sframe')
train_data, test_data = data.random_split(0.9)
model = tc.image_classifier.create(train_data, target='label', max_iterations=100)
predictions = model.predict(test_data)
metrics = model.evaluate(test_data)
print('metrics=' + str(metrics['accuracy']))
model.save('mymodel.model')
model.export_coreml('My.mlmodel')
解説
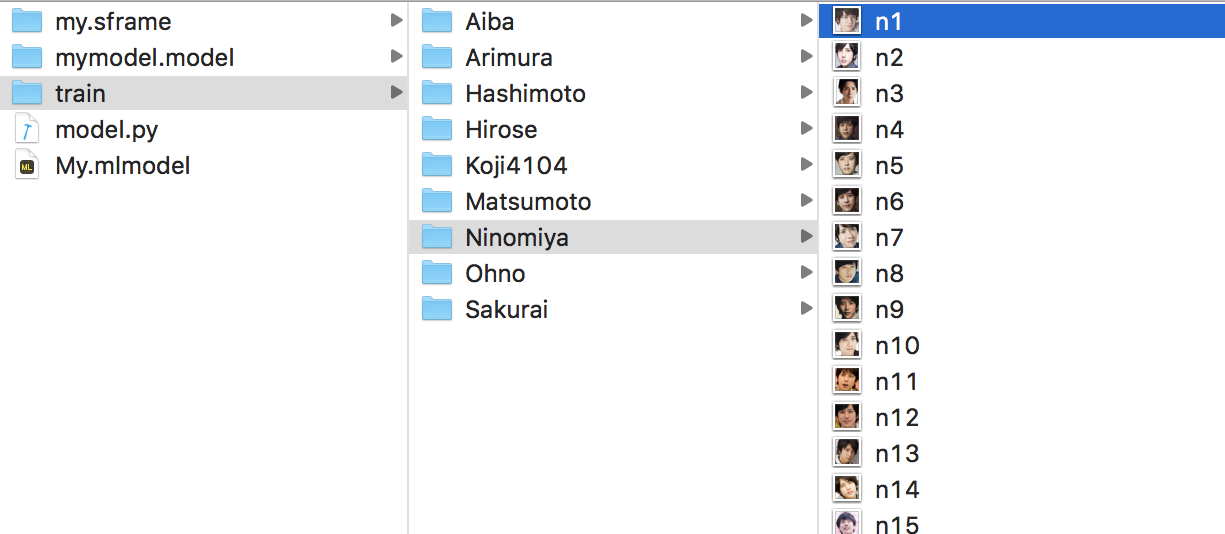
trainフォルダの下にフォルダを作り、トレーニング画像(顔の画像)を50枚くらい入れます。モデル作成時に「フォルダ名」がそのまま「分類名」になります。(コードを変えなくてもいい)上記の例では、相葉や二宮など嵐の5人、有村、橋本、広瀬の女優御三家、そしてKojiの9人です。出来たmy.mlmodelをXCodeプロジェクトにコピペします。
顔認識(検出+分類)
手順
- 以下のコードのMymodel.classify(ciImage)を実行します。
- 分類結果がMymodel.resultsに格納されるので、画面に表示します。
長いですがこれでも当初の1/3になったので全部載せました。この他にも画像を渡したり、結果を表示する仕組みが別途必要です。
import UIKit
import AVFoundation
import Vision
import CoreML
/// CoreMLによる分類
class Mymodel {
/// 結果
public var results:[Result] = []
struct Result {
public var bounds:CGRect = CGRect(x:0,y:0,width:1,height:1)
public var observations:[Observation] = []
}
struct Observation {
public var identifier:String = "" // 名前
public var confidence:Float = 0.0 // 比率
}
/// 分類
func classify(on ciImage: CIImage) {
self.results.removeAll()
// 顔の輪郭検出(複数ある)
let f:Facebounds = Facebounds()
f.detectFacebounds(on: ciImage)
// 輪郭の数だけループ
for face in f.results {
let rc:CGRect = face.bounds
var r:Result = Result()
r.bounds = rc
self.results.append(r)
// 画像を切り出して分類
let ciCropImage = ciImage.cropImage(rect:rc)
let handler = VNImageRequestHandler(ciImage: ciCropImage)
do {
try handler.perform([self.classificationRequest])
} catch {
print(error)
}
}
}
/// 結果の解析
func handleClassification(request: VNRequest, error: Error?) {
guard let observations = request.results as? [VNClassificationObservation]
else { fatalError("unexpected result type from VNCoreMLRequest") }
var obs:[Observation] = []
for observation in observations {
var o:Observation = Observation()
o.identifier = observation.identifier
o.confidence = observation.confidence
obs.append(o)
if obs.count>5 {
break
}
}
if self.results.count>0 {
self.results[self.results.count-1].observations = obs
}
}
// 学習モデル(My.model)
lazy var classificationRequest: VNCoreMLRequest = {
do {
var model: VNCoreMLModel? = nil
model = try VNCoreMLModel(for: My().model)
return VNCoreMLRequest(model: model!, completionHandler: self.handleClassification)
} catch {
fatalError("can't load Vision ML model: \(error)")
}
}()
}
/// Visionを使った顔の輪郭検出
class Facebounds {
let faceDetection = VNDetectFaceRectanglesRequest()
let faceDetectionRequest = VNSequenceRequestHandler()
/// 結果
public var results:[Result] = []
struct Result {
public var bounds:CGRect = CGRect(x:0,y:0,width:1,height:1)
}
/// 輪郭検出
func detectFacebounds(on image: CIImage) {
self.results.removeAll()
try? self.faceDetectionRequest.perform([self.faceDetection], on:image)
if let observations = self.faceDetection.results as? [VNFaceObservation] {
for observation in observations {
// 小数座標をピクセル座標に変換、上下反転
var r:Result = Result()
let rc:CGRect = observation.boundingBox.scaled(sz:image.extent.size)
r.bounds = rc.upsidedown(h:image.extent.size.height)
self.results.append(r)
}
}
}
}
extension CIImage {
func cropImage(rect:CGRect) -> CIImage {
UIGraphicsBeginImageContext(CGSize(width:rect.size.width, height:rect.size.height))
let filter:CIFilter! = CIFilter(name: "CICrop")
filter.setValue(self, forKey:kCIInputImageKey)
filter.setValue(CIVector(cgRect:rect), forKey:"inputRectangle")
let ciContext:CIContext = CIContext(options: nil)
let cgImage = ciContext.createCGImage(filter!.outputImage!, from:filter!.outputImage!.extent)!
UIGraphicsEndImageContext()
return CIImage(cgImage:cgImage)
}
}
extension CGRect {
func scaled(sz:CGSize) -> CGRect {
return CGRect(
x: self.origin.x * sz.width,
y: self.origin.y * sz.height,
width: self.size.width * sz.width,
height: self.size.height * sz.height
)
}
func upsidedown(h:CGFloat) -> CGRect {
return CGRect(
x: self.origin.x,
y: (h - self.size.height - self.origin.y),
width: self.size.width,
height: self.size.height
)
}
}
解説
呼び出すコードはMymodel.classify()です。中の処理は、まずVisionに1枚の画像を渡して、顔の輪郭の矩形を取得します。Visionの結果は座標で出るのですが、小数で上下反転で出るため座標を変換します。次に顔の画像を切り出して、CoreMLによる画像の分類を行います。結果は名前と比率が出ます。名前はモデルの作成時に作ったフォルダ名で、比率は全部足して100%になるように出ます。
結果

自作アプリ「It's my Live」をベースに改造しています(Appleストア公開中)。今回は上位2つを表示しています。結果は偶然良いものを使っており、実際の認識率は5割〜7割くらいです。男性5人、女性3人、眼鏡の私1人。眼鏡が原因なのか私の認識率はとても高かったです。顔はおでこから下の顔部分だけがいいです。初めわざと大きく切り取ってましたが、髪も無い方が認識率が上がります。トレーニング画像を何度も作り直すのに時間を費やしました。
これから
顔認識は夢やアイデアがいっぱいあるのですが、こういうのは前後のシステムを含めてアップルやアマゾンがやるのではないかと思います。隙間商法をやるとすれば、作物の害虫の検出とか、毒キノコの判別などでしょうか。害虫の検出なら監視カメラを複数置いて集中管理するサーバー型になるだろうし、毒キノコの判別なら山の上でも使えるアプリ型になると思います。
しかしそれでは画像マッチングの延長に過ぎず、害虫を検出したからどうなのか、そもそもなぜ害虫と呼ばれるようになったのか。そんなことを考えながら今回試行錯誤していく上で、いくつかのアイデアが浮かびました。それに向けてまた2ヶ月くらい土日頑張ろうと思います。