Google ドライブからファイルをダウンロードするのを試してみました。これがうまくいけば、ファイルを置くだけで処理できるシステムを作ろうと思っています。
今回の記事より簡単なものが公式にあります。
公式クイックスタート(Java, Node, Python)
https://developers.google.com/drive/api/v3/quickstart/python
ソース
以下の Python を実行します。初回実行時には client_secret.json が必要です。成功すると token.pickle が作成されます。実行すると Google ドライブの AAA というフォルダ直下の jpg,png をダウンロードします。
# -*- coding: utf-8 -*-
from __future__ import print_function
import pickle
import os.path
import io
import sys
# pip install --upgrade google-api-python-client google-auth-httplib2 google-auth-oauthlib
from googleapiclient.discovery import build
from google_auth_oauthlib.flow import InstalledAppFlow
from google.auth.transport.requests import Request
from googleapiclient.http import MediaIoBaseDownload
SCOPES = ['https://www.googleapis.com/auth/drive']
FOLDER_NAME = 'AAA'
def main():
# OAuth
drive = None
creds = None
if os.path.exists('token.pickle'):
with open('token.pickle', 'rb') as token:
creds = pickle.load(token)
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
creds.refresh(Request())
elif os.path.exists('client_secret.json'):
flow = InstalledAppFlow.from_client_secrets_file(
'client_secret.json', SCOPES)
creds = flow.run_local_server(port=0)
with open('token.pickle', 'wb') as token:
pickle.dump(creds, token)
if creds and creds.valid:
drive = build('drive', 'v3', credentials=creds)
if not drive: print('Drive auth failed.')
# Folfer list
folders = None
if drive:
results = drive.files().list(
pageSize=100,
fields='nextPageToken, files(id, name)',
q='name="' + FOLDER_NAME + '" and mimeType="application/vnd.google-apps.folder"'
).execute()
folders = results.get('files', [])
if not folders: print('No folders found.')
# File list
files = None
if folders:
query = ''
for folder in folders:
if query != '' : query += ' or '
query += '"' + folder['id'] + '" in parents'
query = '(' + query + ')'
query += ' and (name contains ".jpg" or name contains ".png")'
results = drive.files().list(
pageSize=100,
fields='nextPageToken, files(id, name)',
q=query
).execute()
files = results.get('files', [])
if not files: print('No files found.')
# Download
if files:
for file in files:
request = drive.files().get_media(fileId=file['id'])
fh = io.FileIO(file['name'], mode='wb')
downloader = MediaIoBaseDownload(fh, request)
done = False
while not done:
_, done = downloader.next_chunk()
if __name__ == '__main__':
main()
準備から実行まで
1. Google APIs にアクセス
https://console.developers.google.com/apis/credentials
Google アカウントでログインします。初回はプロジェクト作成が呼ばれるので、My Project など付けてください。
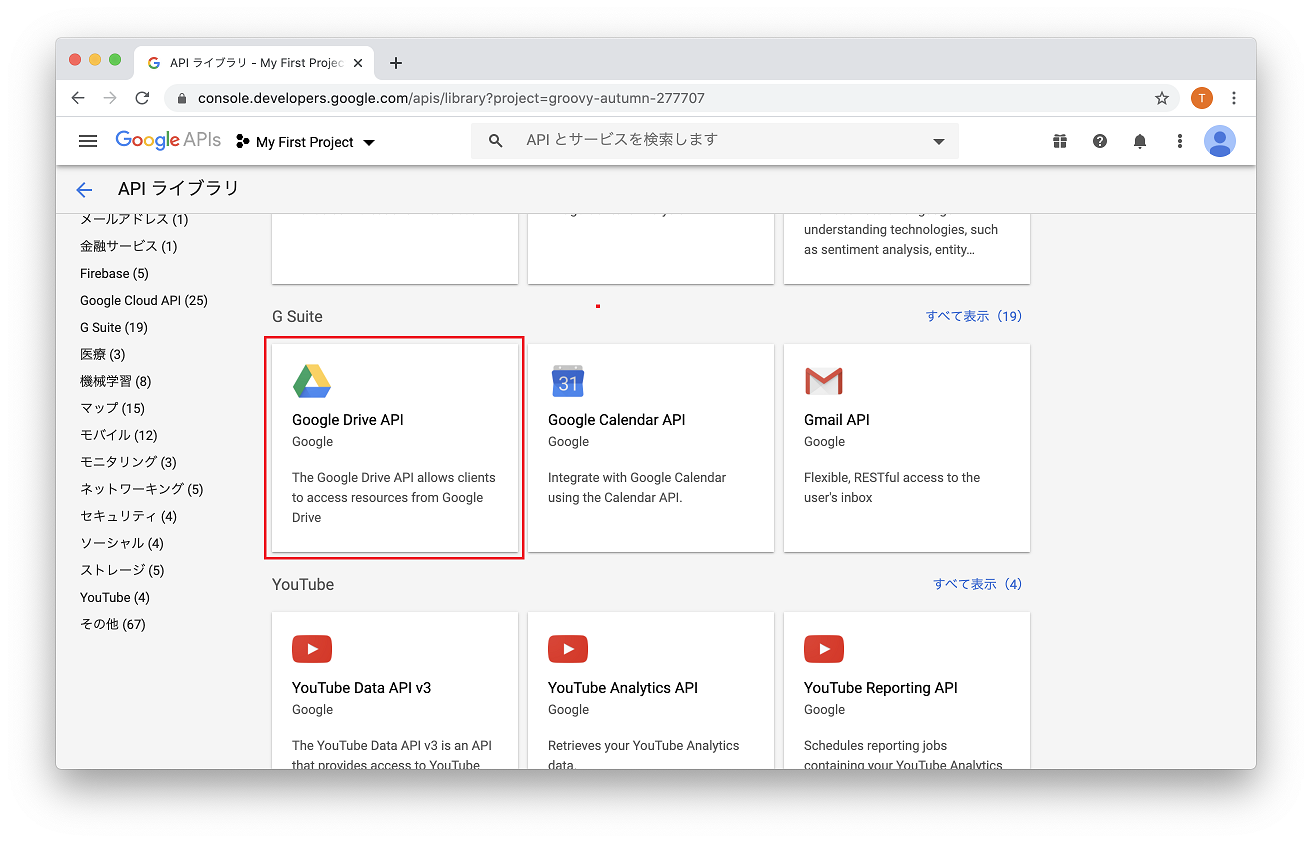
2. Google Drive API を有効
ライブラリから GoogleDriveAPI を選び、API を有効にします。
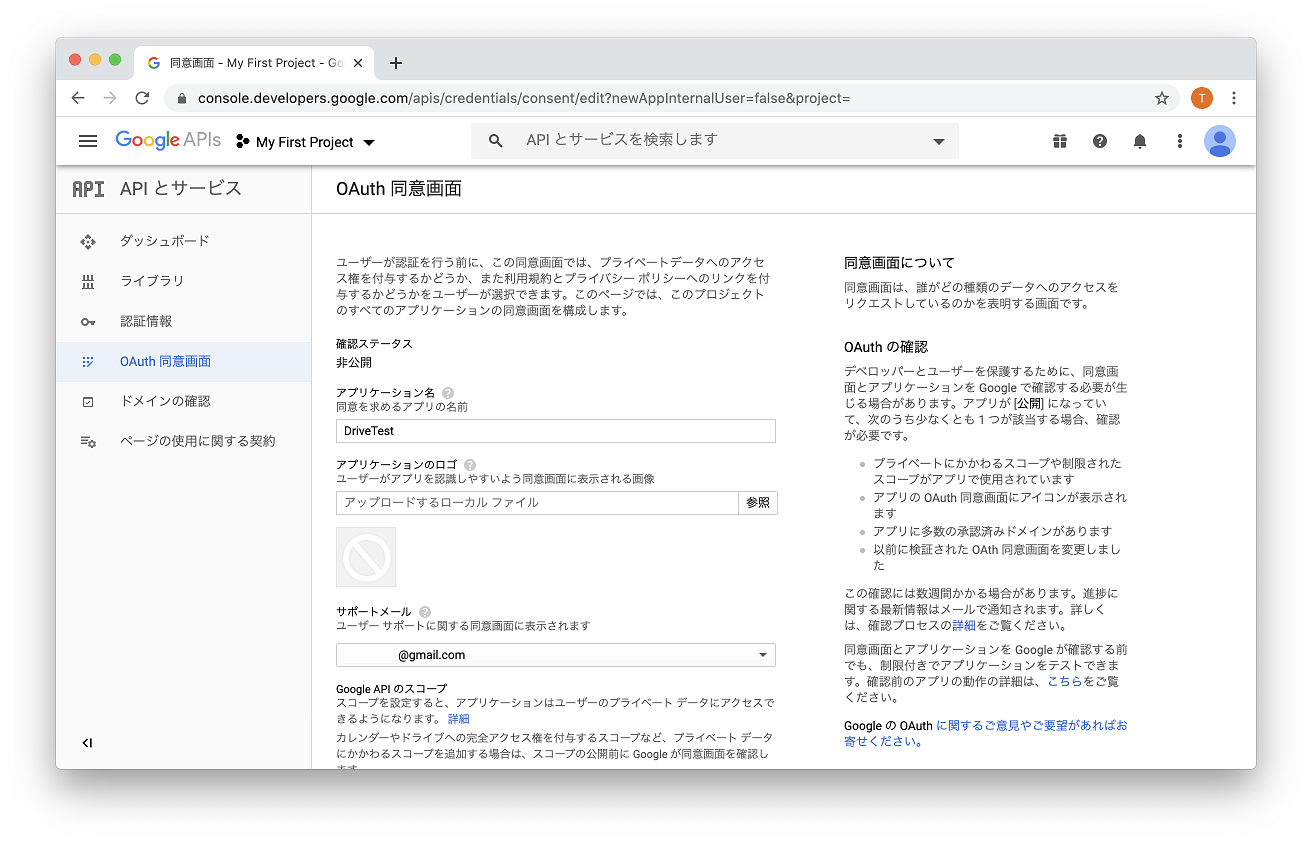
3. OAuth 同意画面の作成
同意画面の作成を行います。
UserType = 外部
アプリケーション名 = 適当な名前(後で変更可能)
他は空白でOKです。ここで付けた名前は認証画面で表示されます。

4. client_secret.json をダウンロード
OAuth クライアントIDを作成します。認証情報を作成から OAuthクライアントID を選び、アプリケーションの種類 = デスクトップアプリ で作成します。作成されたら、クライアントIDのダウンロードボタンを押すと、client_secret-xxx.json がダウンロードされます。


5. アプリを実行
上記の python コードを実行します。
pip install --upgrade google-api-python-client google-auth-httplib2 google-auth-oauthlib
python main.py
ブラウザが立ち上がるので Google アカウントでログインします。「このアプリは確認されていません」で「詳細を表示」「安全でないページに移動」を選びます。認証に成功すると token.pickle が作成されます。Google ドライブの AAA フォルダ直下の jpg,png ファイルがダウンロードされると成功です。


実行結果
Google ドライブに次のようにファイルを置いてみました。AAA という名前のフォルダの直下をダウンロードします。Google ドライブは同じフォルダー名、同じファイル名を作成できることに注意です。
| フォルダ | ファイル | 結果 |
|---|---|---|
| AAA | img1.jpg | OK |
| AAA | img1.jpg | OK |
| AAA/AAA | img2.jpg | OK |
| AAA/BBB | img3.jpg | NG |
| AAA | img4.jpg | OK |
| BBB | img5.jpg | NG |
| BBB/AAA | img6.jpg | OK |
| / | img7.jpg | NG |
解説
OAuth 認証
SCOPES = ['https://www.googleapis.com/auth/drive']
# 既に token があるとき
creds = None
if os.path.exists('token.pickle'):
with open('token.pickle', 'rb') as token:
creds = pickle.load(token)
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
creds.refresh(Request())
elif os.path.exists('client_secret.json'):
# 認証URLが発行されるのでログインして許可します
flow = InstalledAppFlow.from_client_secrets_file(
'client_secret.json', SCOPES)
creds = flow.run_local_server(port=0)
# ピクルで保存
with open('token.pickle', 'wb') as token:
pickle.dump(creds, token)
SCOPES = ['https://www.googleapis.com/auth/drive'] にはすべての権限があるので、実際には範囲を絞った方がいいと思います。
初めは Node で作りました。そのときは、URL → ログインして許可 → コードが表示されるのでアプリにコピペ → トークンゲットです。python の方が楽です。
今回初めて pickle(ピクル、漬物)というものを使いました。オブジェクト(実体のあるクラスなど)を丸ごとバイナリー保存できるみたいです。 他の言語でいうシリアライズでしょうか。便利そうです。
Google ドライブからリストを取得
results = drive.files().list(
# 上限数
pageSize=100,
# 取得したいパラメーター
fields='nextPageToken, files(id, name, parents)',
# クエリー(指定しなければ全部取得)
q='name contains ".jpg" or name contains ".png"'
).execute()
files = results.get('files', [])
for file in files:
print(file['name'] +' '+ file['parents'][0])
parents は親フォルダーのIDです。ここではフォルダーの名前は分からないので、別途IDを調べる必要があります。上記の main.py コードでは、フォルダー名からIDを取得して、ファイルを検索しています。
上記の例は .jpg .png で検索しています。検索しないと余計なファイルなどで json が大きくなってしまいます。他にも mimeType="application/vnd.google-apps.folder" と書けばフォルダーのみの検索もできます。
今回はやってないですが、pageSize=100 を超えた場合は、nextPageToken を使って再取得する処理が必要です。
fields files() のパラメータ一覧
コードで fields='files(id, name, parents)' と書くと parents が取得できます。初め何を指定してよいのか分からず悩んでいました。結果的には fields='files' で実行するとすべて取得できます。すべて取得するとJsonが長くなるので指定した方がよいです。取得した結果を載せておきます。
{"kind":"drive#file",
"id":"1PTrhGA14N-xxxx",
"name":"img1.jpg",
"mimeType":"image/jpeg",
"starred":false,
"trashed":false,
"explicitlyTrashed":false,
"parents":["1Jigt87nbz-xxxx"],
"spaces":["drive"],
"version":"1",
"webContentLink":"https://drive.google.com/xxxx",
"webViewLink":"https://drive.google.com/file/xxxx",
"iconLink":"https://drive-thirdparty.xxxx",
"hasThumbnail":true,
"thumbnailVersion":"1",
"viewedByMe":true,
"viewedByMeTime":"2020-05-23T19:13:29.882Z",
"createdTime":"2020-05-23T19:13:29.882Z",
"modifiedTime":"2013-08-13T23:05:18.000Z",
"modifiedByMeTime":"2013-08-13T23:05:18.000Z",
"modifiedByMe":true,
"owners":[{xxxx}],
"lastModifyingUser":{xxxx},
"shared":false,
"ownedByMe":true,
"capabilities":{xx,xx,xx},
"viewersCanCopyContent":true,
"copyRequiresWriterPermission":false,
"writersCanShare":true,
"permissions":[{xxxx}],
"permissionIds":["1485xxxx"],
"originalFilename":"img1.jpg",
"fullFileExtension":"jpg",
"fileExtension":"jpg",
"md5Checksum":"95c10exxxx",
"size":"492642",
"quotaBytesUsed":"492642",
"headRevisionId":"0BzjG8APx-xxxx",
"imageMediaMetadata":{"width":1920, "height":1200, xx},
"isAppAuthorized":false}
まとめ
Google ドライブからファイルのダウンロードを試してみました。実際にやってみて色々気付かされました。
AWS S3 同様、Googleドライブもクラウドであること。ローカルファイルの検索のようにはいかず、ひと癖あります。AWSの場合はこちらで用意したモノをお客様に提供しているのですが、Googleドライブの場合はお客様側のモノを想定しています。なのでもう少し手間が必要になりそうです。
AWS Lambda を使えば個人的にもなんかできそう。