行動認識 Activity Recognition(または Action Recognition) が手軽に試せるようになりました!
Google の AI サービスは、様々ありますが、ビデオを入力とするものは2つ用意されています:
https://cloud.google.com/video-intelligence/?hl=JA
- Video Intelligence API
- AutoML Video Intelligence
上の Video Intelligence API に関しては、上記のページからデモが簡単に試せますので、どんなものか雰囲気が掴めます。以下の画像のように、動画中にどんな物体が写っているか教えてくれます。(2019/12/29時点では試せないようです)
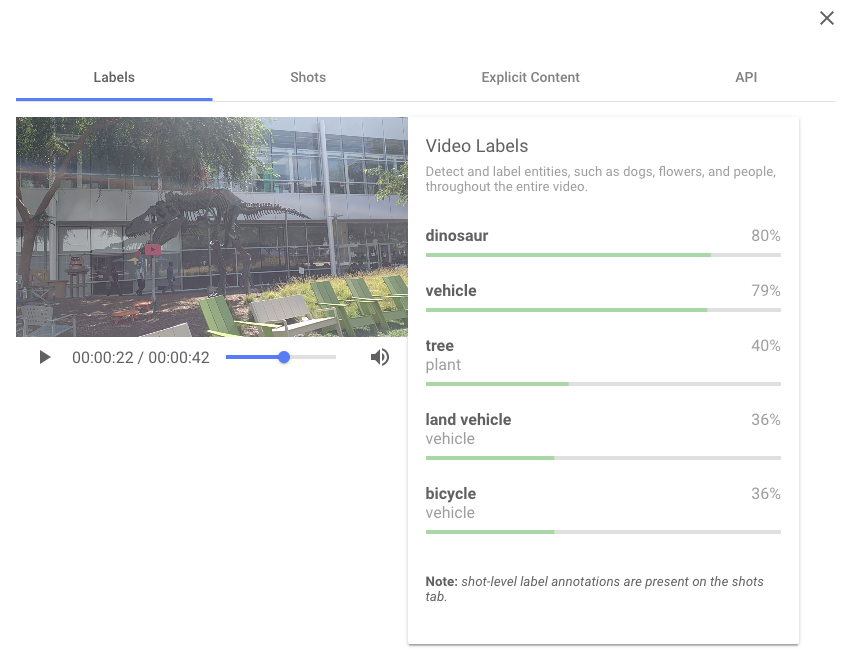
Video Intelligence API では、以下のように、どんな行動かは、ある程度は認識してくれるようですが、
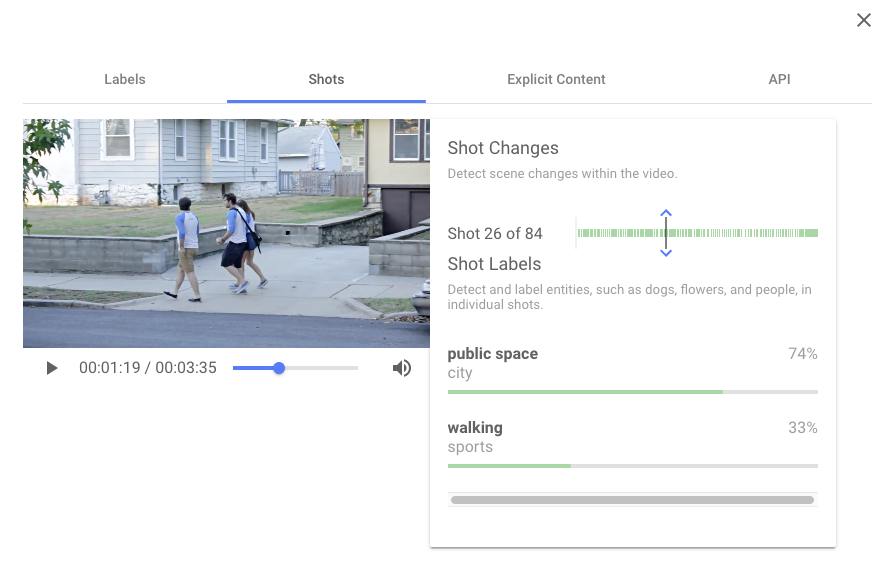
既存のデータセットにない特殊な動作を認識させたい場合には、もう一方の AutoML Video Intelligence が役に立ちます。動画中で「どの区間」で「どんな行動」を行っているかを認識してくれるのは変わらないのですが、「どんな行動」かを指定することができるのです。
(ベータ版ですので、日々インターフェースが変更されています。以下の説明とは現状異なっていることをご了承ください。)
AutoML Video Intelligence では、教師データとして、カスタムデータセット(短いビデオクリップとそれが表す行動のラベル)を用意します。それを学習させると、未知のビデオに対し「どの区間」で「どんな行動」をしているかを教えてくれます。
AutoML というぐらいですから、 Google先生がいつも通り、機械学習を自動的にうまい具合にやってくれるわけです。
試してみた
基本的に、以下のサイトに従うだけなのですが、システムが常に更新されているようで、説明通りに使えません。
https://cloud.google.com/video-intelligence/automl/docs/quickstart-console?hl=JA
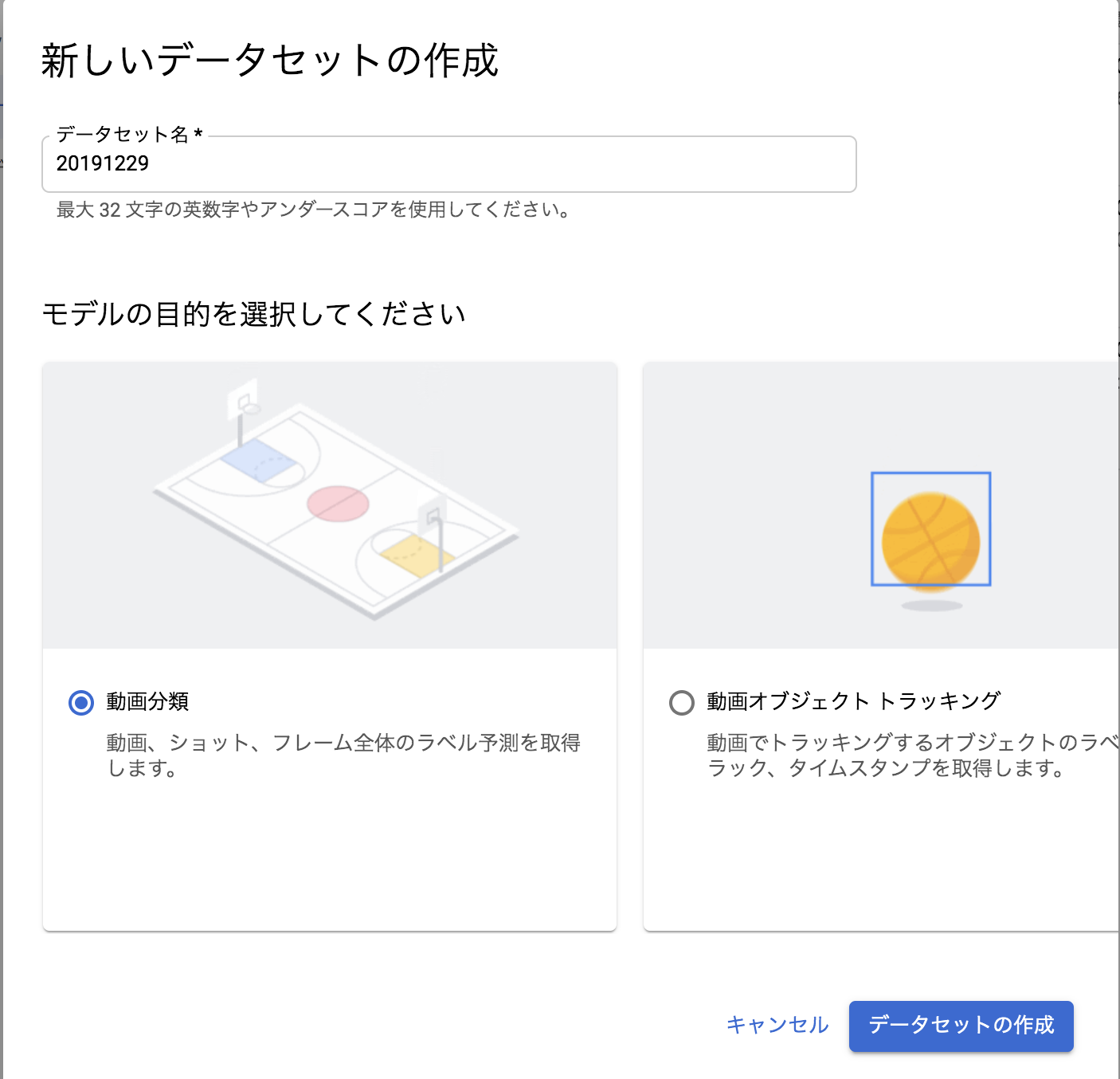
データセットの作成
まず、[Create Dataset] をクリックした時点で出てくるダイアログがもうすでに違います。前は「動画分類」しかできなかったんですがね。「動画オブジェクトトラッキング」も面白そうですが、今回は「動画分類」を試します。
モデルのトレーニング
あと、説明ではいくつものラベルを読み込んでいるスクショがありますが、デモでは認識できるラベルの数が5つになってます。
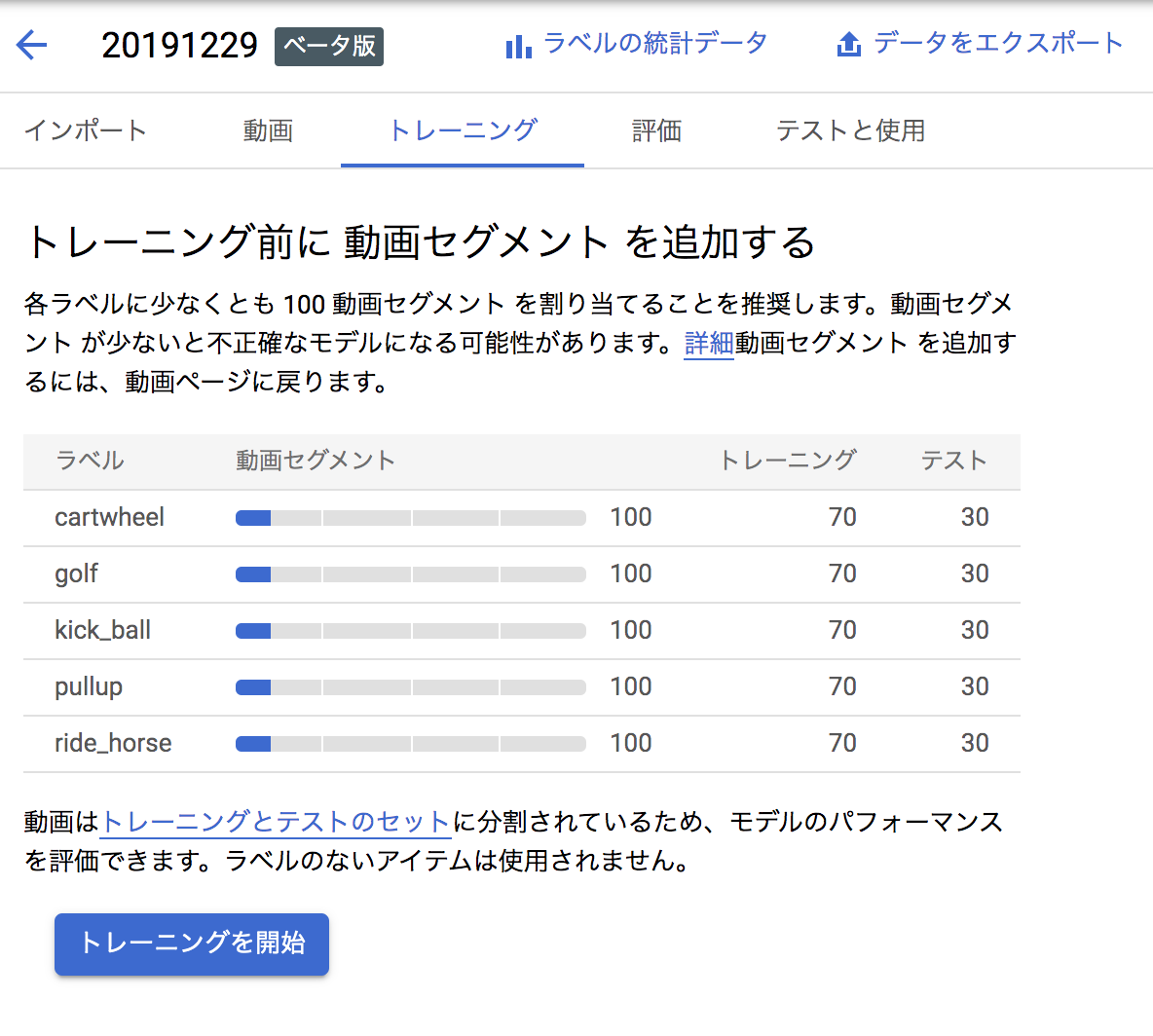


モデルのトレーニングが終わると、メールが届きます。
動画を分類する
「動画を分類する」の "アノテーション結果を受け取る Cloud Storage バケット内のディレクトリを選択します。" とさらっと書いてありますが、
説明通り、Result Bucket 欄に my-storage-bucket と入力しても動きません。
そもそも、 Bucket(バケット)ってなんだよ?ってことになるのですが、 Google Cloud Storage というのを自分で作成しないといけません。
しかも、このバケットは、Result Bucket 欄の横の?マークをクリックするとわかるのですが、us-central1リージョン内に作成しないといけません。
バケットの作り方については、例えばここを参考にしてみてください(かならずus-central1リージョンに作ってね!):
https://thinkit.co.jp/story/2015/03/30/5801
そうすると、認識結果が指定したバケット内に保存されます。
結果を表示する
以上のサイトの説明では、単体動作のビデオクリップを選んでるだけで面白くないので、学習に利用したレゾリューションが同じビデオクリップを組み合わせた動画を作って認識させてみました。(学習に利用したデータをテストに利用するのは邪道ですけど、適当な動画がすぐ手に入らなかったので。。。)
0-3秒:懸垂(pullup)
3-5秒:ゴルフ(golf)
5-6秒:側転(cartwheel)
7-8秒:乗馬(ride_horse)
9-11秒:ボールキック(ball_kick)
まず、
gs://[central1で作成したバケット名]/test-data/concat.mp4,0,12
を作成し、以下に置きます:
gs://[central1で作成したバケット名]/test-data/concat.csv
二列目の0と三列目の12 は、一列目で指定する動画の 0秒から12秒までを認識させるという意味と思われます。
[入力 CSV] で、上記の文字列を入力します。
[結果バケット] は、[central1で作成したバケット名]を入力します。
認識結果
認識の単位が1秒ごとで荒いので、1秒たってから、その動作カテゴリが認識された形となっています。
8月に試した結果:
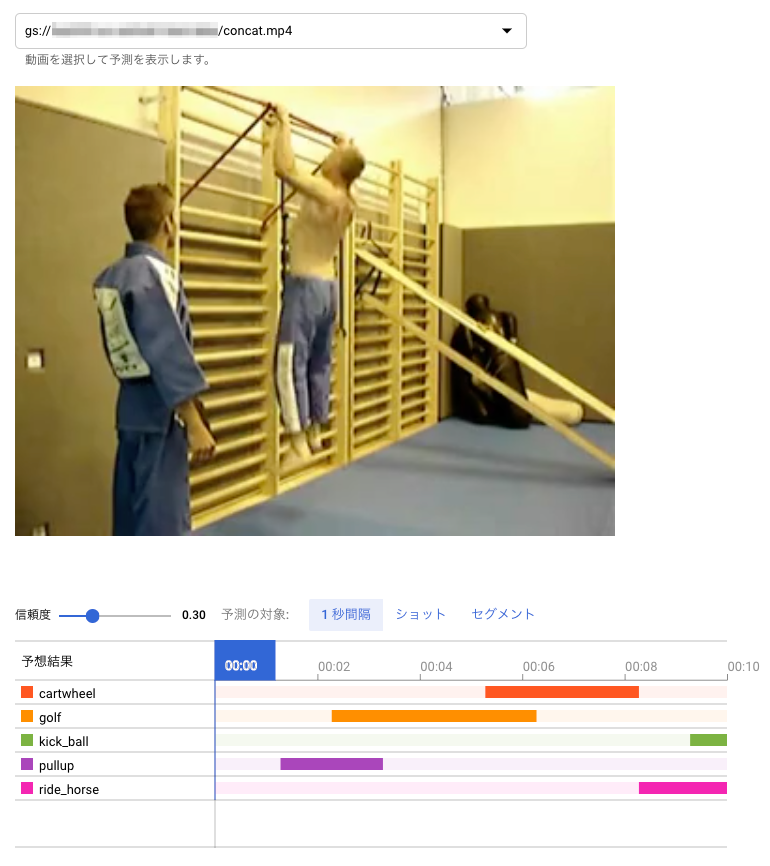
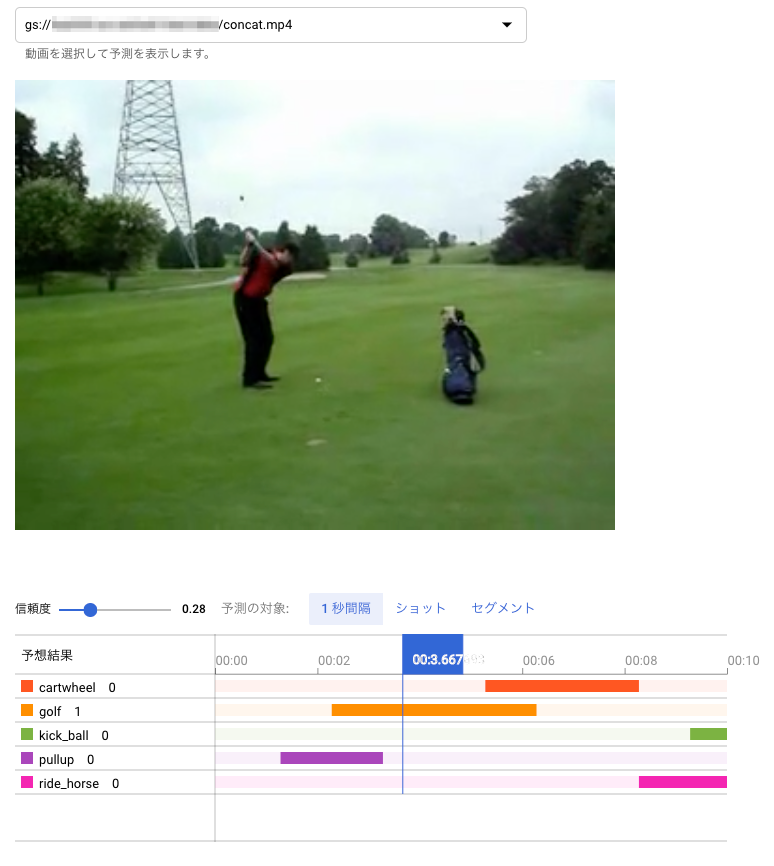
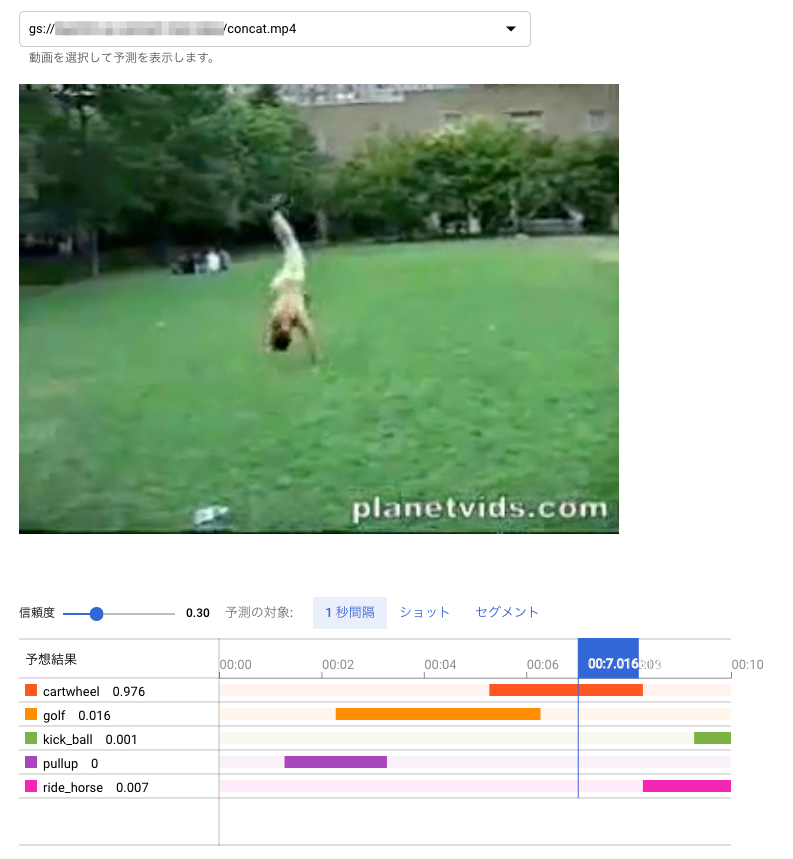
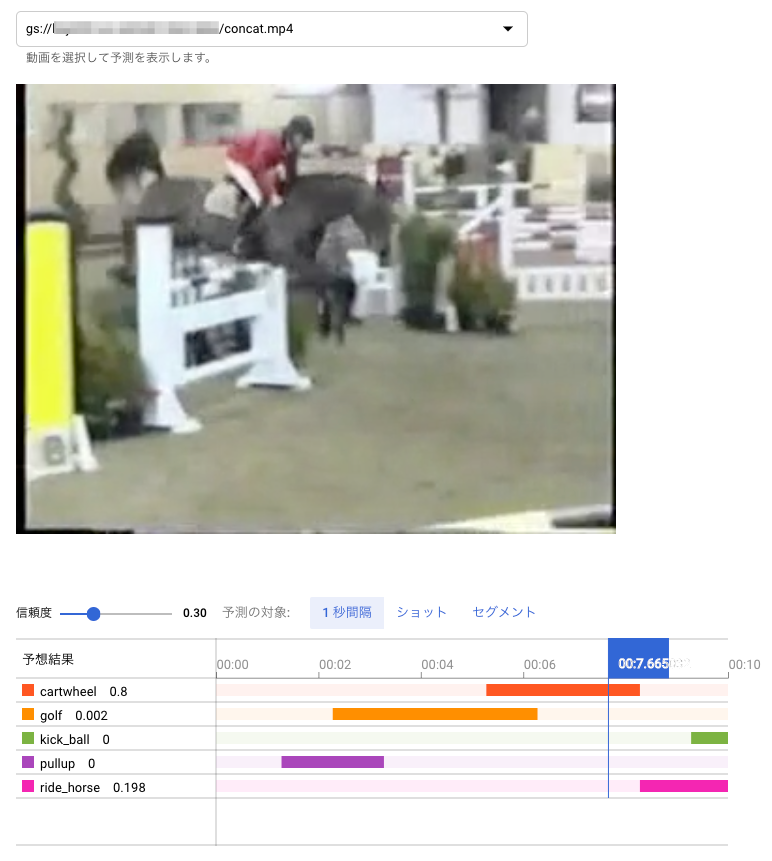
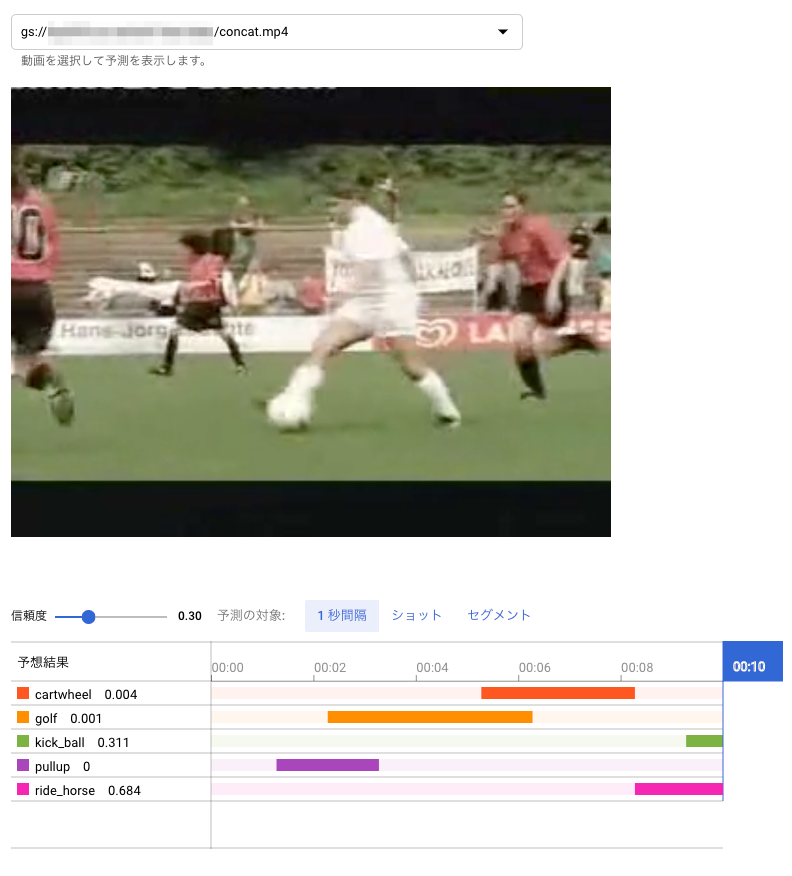
以上の画面では、信頼度を 0.3 に設定して表示させています。初期の認識画面では、信頼度が0.5になっているのですが、最後の画像をみてもわかるように、明らかに kick_ball のシーンになっているのにもかかわらず、ride_horse の信頼度 0.684 より kick_ball が 0.311 と低くなってバーが表示されないからです。
12月に試した結果:
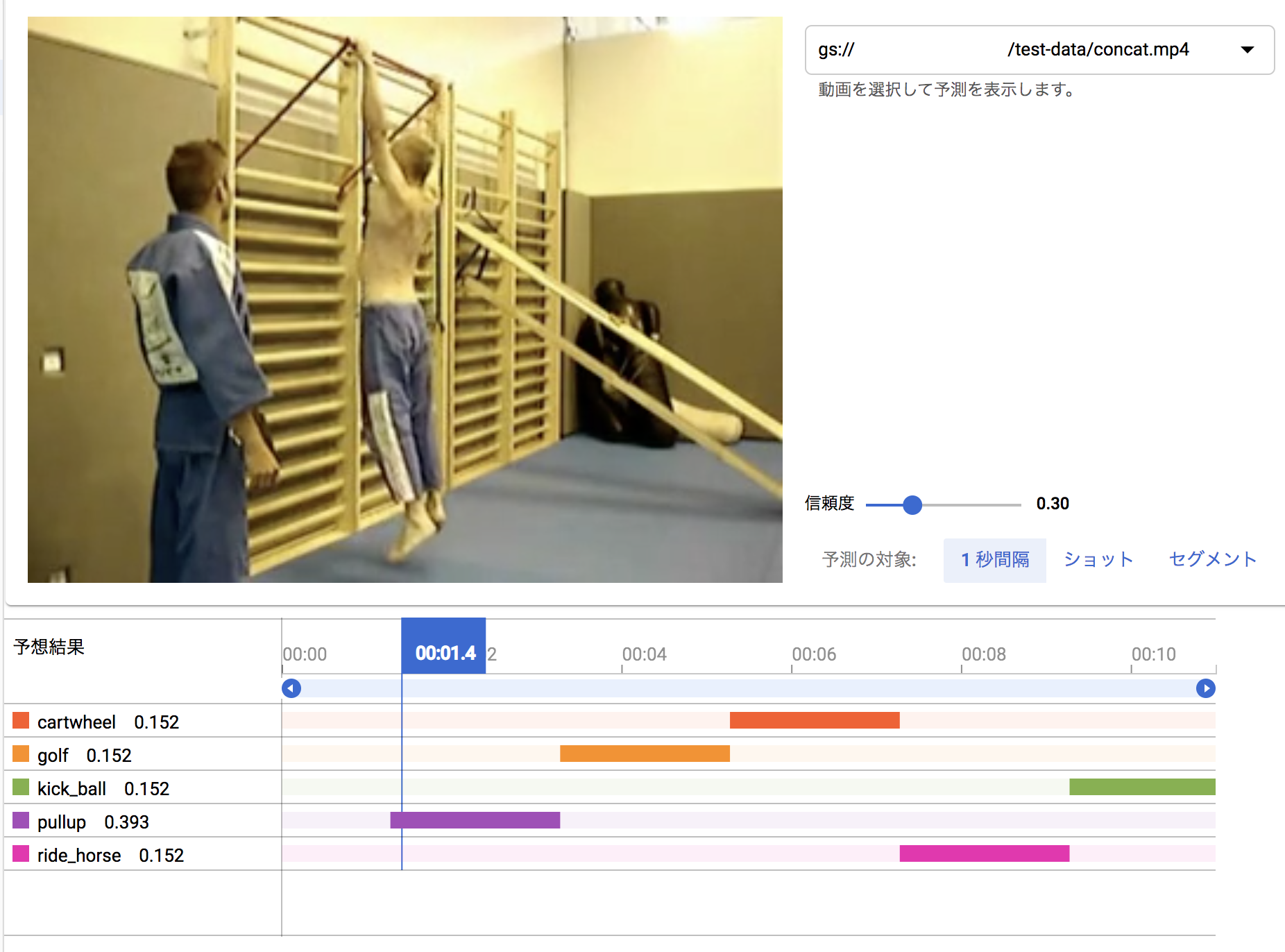
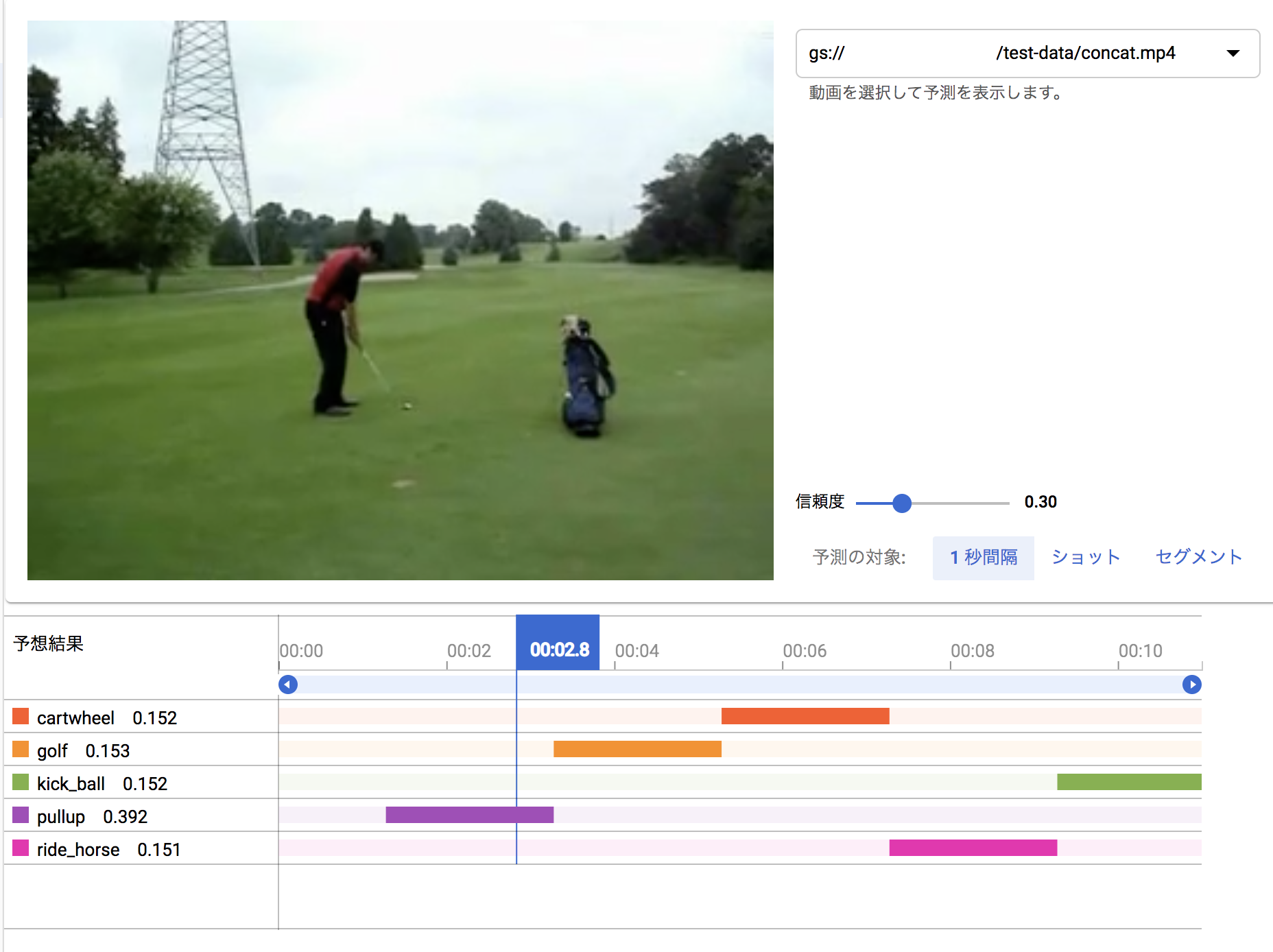
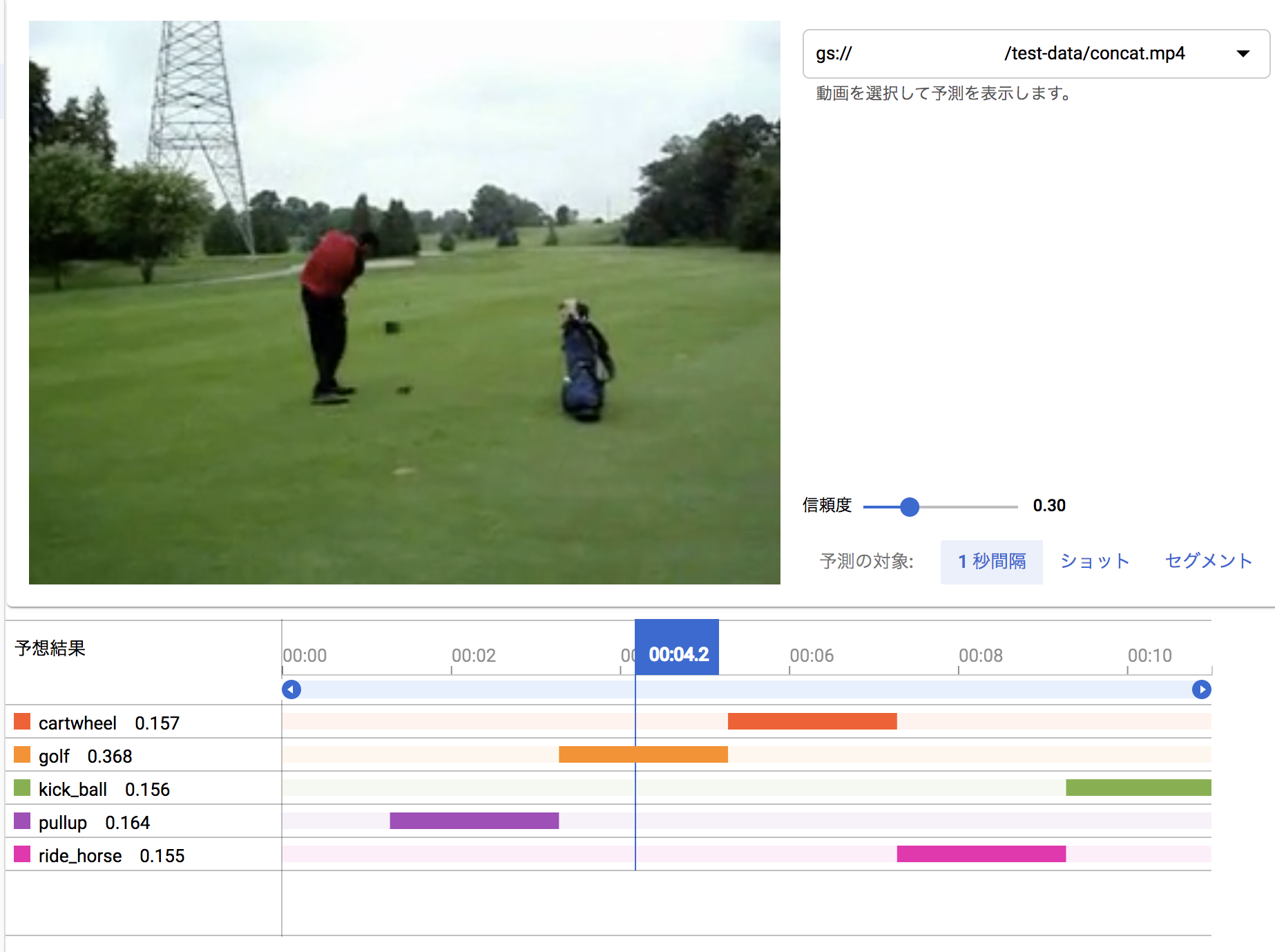
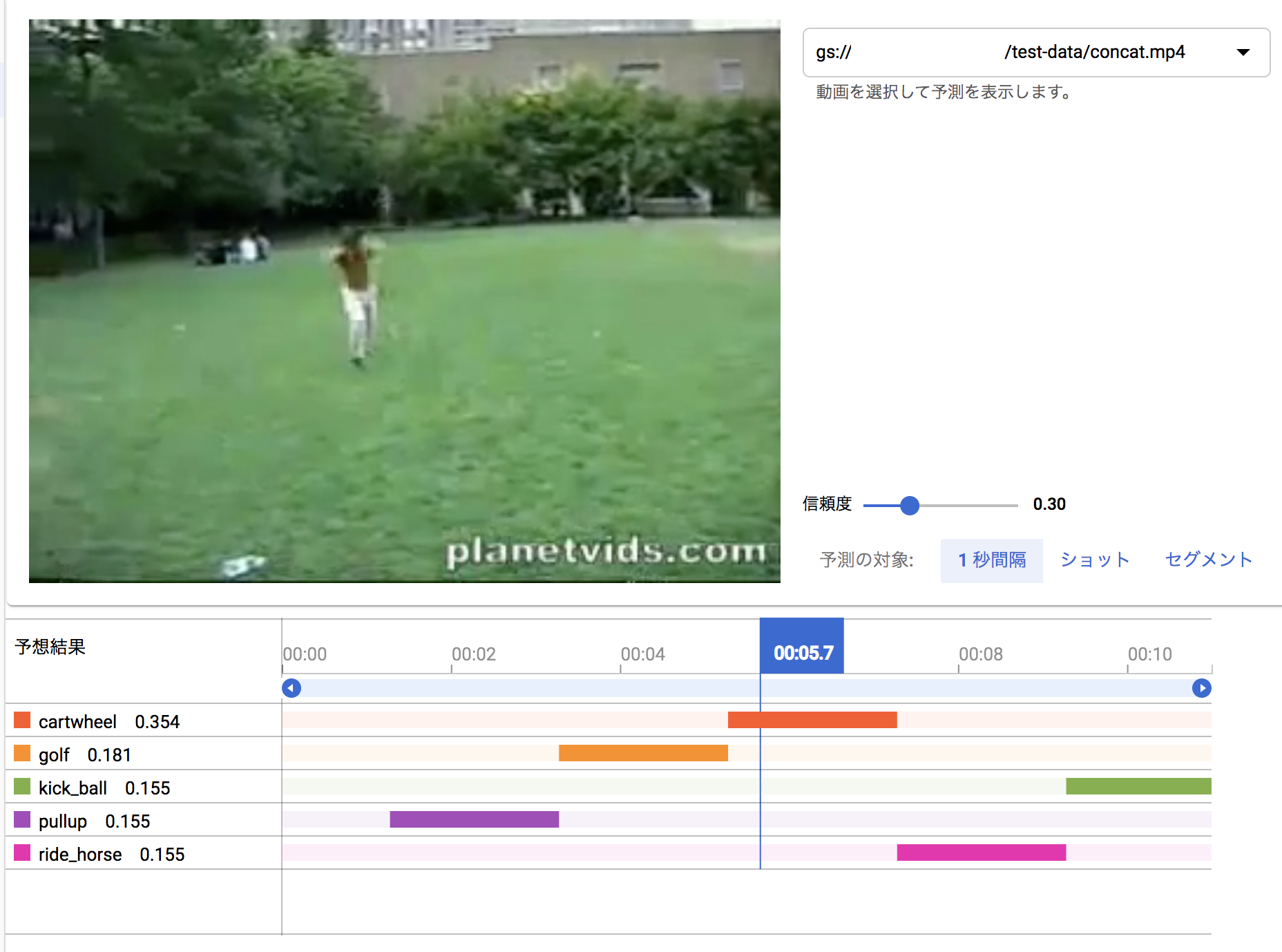
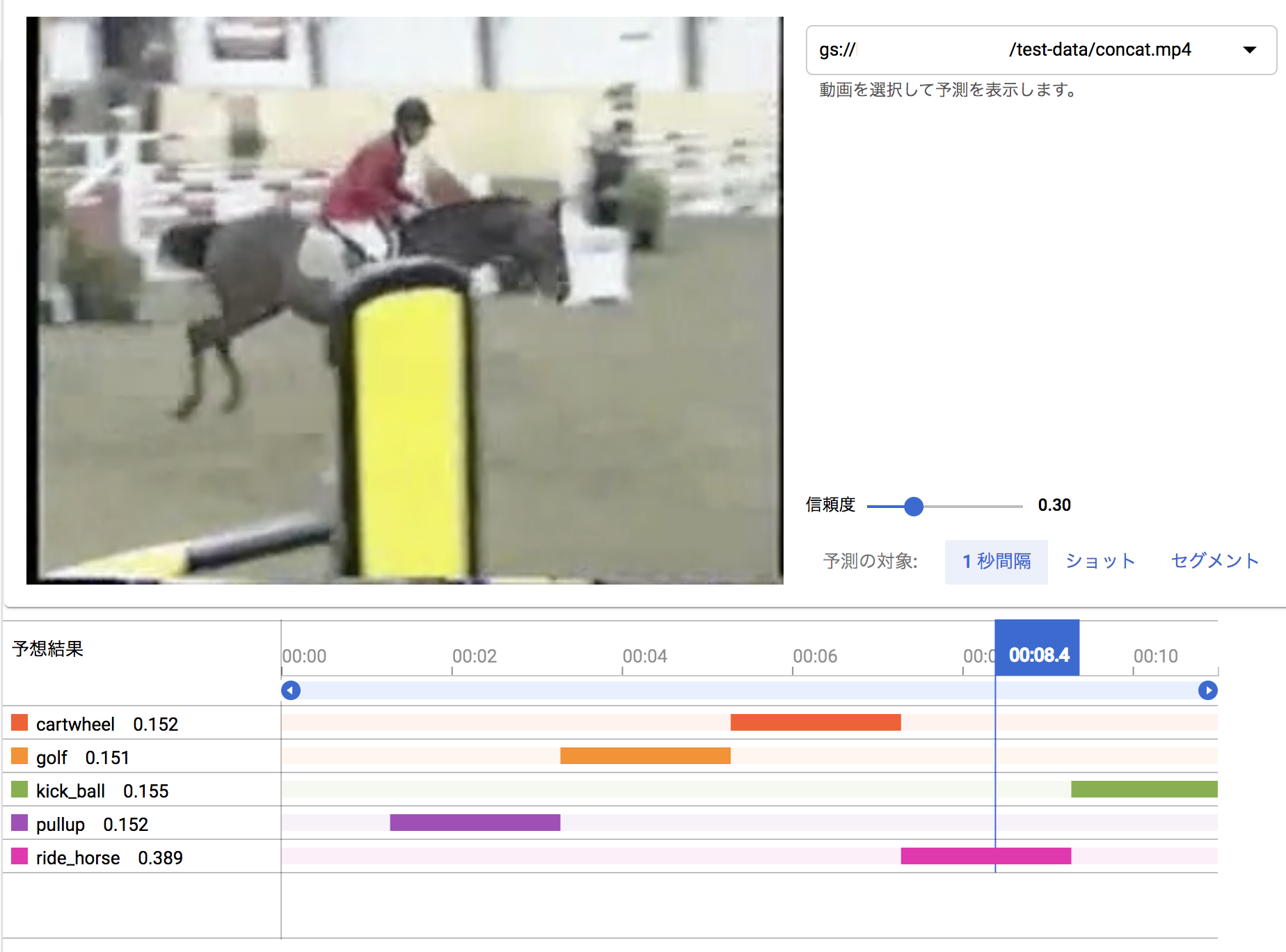
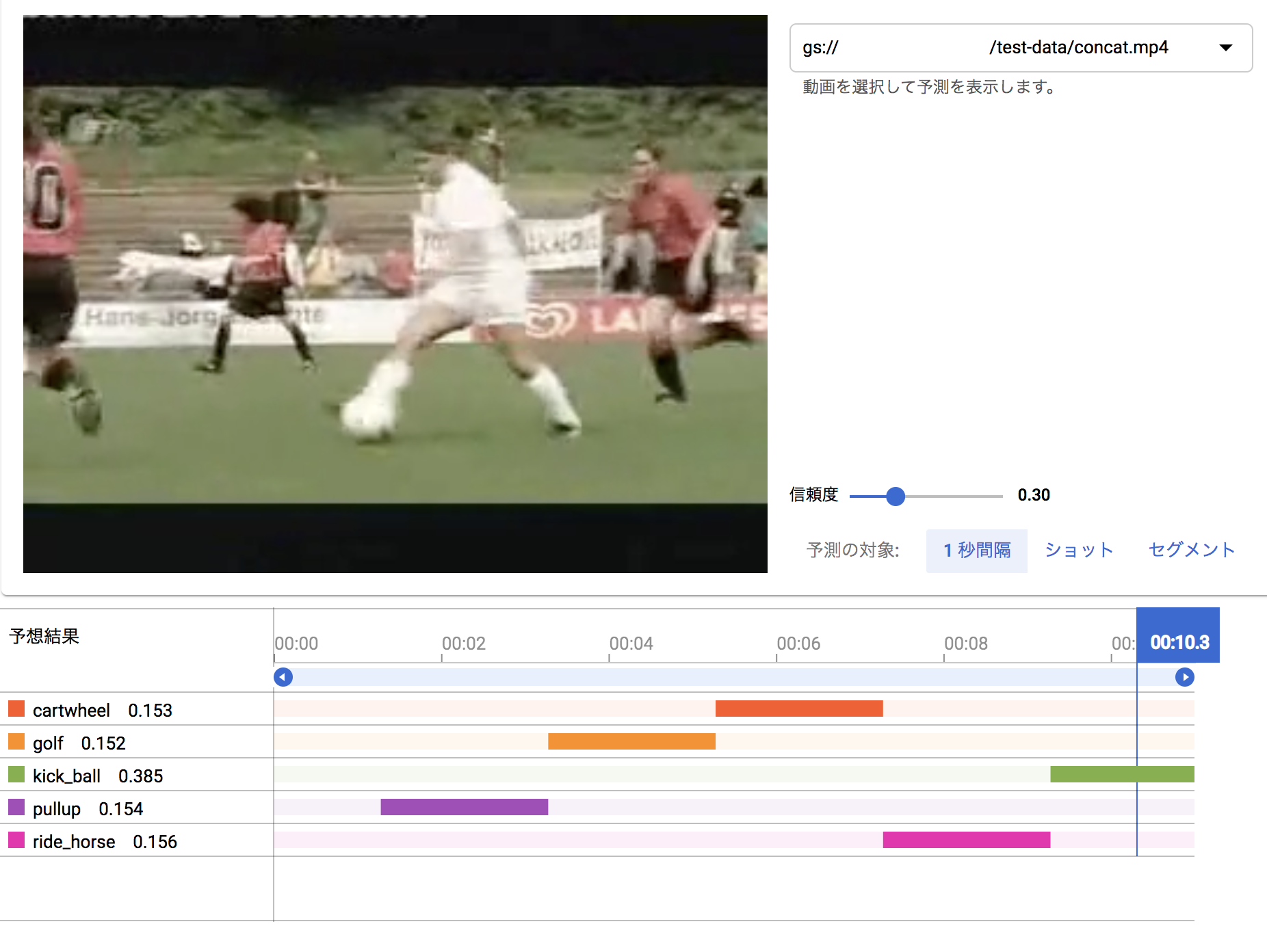
この見せ方も、複数の信頼度曲線で表すとわかりやすいのになぁと思います。(稜線が認識結果になりますよね)
料金
結構、計算パワーを使う処理ですので、値段が気になるところです。
前回8月に利用した際は、こんな値段でしたが、トライアルのクレジットで無料になりました:
| 内 容 | 時 間 | 金 額 |
|---|---|---|
| Cloud AutoML AutoML Video Classification Model Training: | 42.109 時間 | ¥13,450 [通貨換算: USD から JPY(レート 108.64 を使用)] |
今回は、だいたい2時間ぐらいの学習でしたので、640円ぐらいの請求になるでしょう。1日経たないと料金がわからないので、わかったら報告します。
ちなみに、かかった費用ですが、月ごとの請求書をみたら、AutoML Video Classification Model Training に 10.527 時間 かかっており、3,382円の請求でしたが、フリートライアルで、無料でした。
いくらかかるか事前に予想できないのが、ちょっと怖いです。どこかに書いてあるんでしょうけど。
https://cloud.google.com/free/docs/gcp-free-tier
おわりに
今回は学習データをテストデータに使うという荒技を使っていますので、実際に実用になるかはわかりませんが、スポーツ映像を解析する上で、ビデオ中でどんな行動をとっているかわかると、手間が省けますよね。サッカーだと、ゴールシーンだけざっと見るとかできそうです。
行動認識についての情報は、Qiitaでは、ココ:
https://qiita.com/tags/%E8%A1%8C%E5%8B%95%E8%AA%8D%E8%AD%98
海外のサーベイは、いいかわからないけど、とりあえずココ:
http://blog.qure.ai/notes/deep-learning-for-videos-action-recognition-review
Activity Net コンテスト:
http://activity-net.org/challenges/2019/challenge.html