はじめに
今回は統計検定2級の範囲の標準化得点について学んでいきます。標準化得点は学校のテストでも利用しているので、馴染みがありますね!!そもそも標準化得点って何?、なんで必要なの?って事を明らかにしていこうと思います!!
📊 標準化得点(zスコア)とは?
標準化得点(zスコア)とは、あるデータが平均からどれだけ離れているかを「標準偏差を基準に」示す指標です。
✅ 数式と意味
標準化得点は、次の式で定義されます:
$$
z = \frac{x - \mu}{\sigma}
$$
- $x$:個々のデータ
- $\mu$:平均(mean)
- $\sigma$:標準偏差(standard deviation)
- $z$:標準化得点(zスコア)
🧠 直感的な理解
- $z = 0$:平均と同じ
- $z > 0$:平均より大きい
- $z < 0$:平均より小さい
- $z = 1$:平均より1標準偏差上
- $z = -2$:平均より2標準偏差下
🎯 なぜ使うの?
1. 単位やスケールが異なるデータの比較に使える
たとえば:
- テストA:100点満点、平均70点、あなたの点数80点
- テストB:50点満点、平均30点、あなたの点数35点
どちらも $z = 1.0$(=平均より1標準偏差上)
→ どちらも相対的には同じくらい良い成績!
2. 分布内での相対的位置がわかる
正規分布を前提にすると、zスコアから「全体の中でどれくらいの位置にいるか」がわかります:
| zスコア | 下位%(累積確率) | 上位% |
|---|---|---|
| $-2.0$ | 2.28% | 97.72% |
| $-1.0$ | 15.87% | 84.13% |
| $0.0$ | 50.00% | 50.00% |
| $1.0$ | 84.13% | 15.87% |
| $2.0$ | 97.72% | 2.28% |
3. 統計解析・機械学習の前処理に役立つ
特徴量のスケールを揃えることで、回帰・分類・クラスタリングなどの精度や収束性が向上します。
🧮 計算例
平均 $\mu = 70$、標準偏差 $\sigma = 10$ のテストで、得点 $x = 85$ の場合:
$$
z = \frac{85 - 70}{10} = 1.5
$$
→ あなたのスコアは平均より 1.5標準偏差分上。
→ 正規分布なら 上位約6.68% に入ります。
🎓 偏差値との関係
偏差値は、zスコアを使ってスケール変換したものです:
$$
偏差値 = 10z + 50
$$
たとえば、zスコアが $1.0$ なら:
$$
偏差値 = 10 \times 1 + 50 = 60
$$
→ 偏差値60は、上位約16% に該当します。
実践
# 📌 日本語フォントインストール(Google Colab専用)
!apt-get -y install fonts-ipafont-gothic > /dev/null
# 📦 ライブラリ
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
from scipy.stats import norm
# 🎌 日本語フォント設定(Colab用)
jp_font = FontProperties(fname="/usr/share/fonts/opentype/ipafont-gothic/ipag.ttf")
plt.rcParams['font.family'] = jp_font.get_name()
# ⚙️ 平均と標準偏差を設定
mu = 70
sigma = 10
# 🎲 スコアを正規分布からランダムに生成
np.random.seed(42)
scores = np.random.normal(loc=mu, scale=sigma, size=20).round(1)
# 🧮 zスコア・パーセンタイル計算
z_scores = (scores - mu) / sigma
lower_percentiles = norm.cdf(z_scores) * 100
upper_percentiles = 100 - lower_percentiles
# 📋 データフレームにまとめる
df = pd.DataFrame({
'スコア': scores,
'zスコア': z_scores,
'上位%': upper_percentiles
}).sort_values('スコア').reset_index(drop=True)
# 📈 正規分布の曲線データを作成
x = np.linspace(mu - 4*sigma, mu + 4*sigma, 400)
y = norm.pdf(x, mu, sigma)
# 🎨 グラフ描画
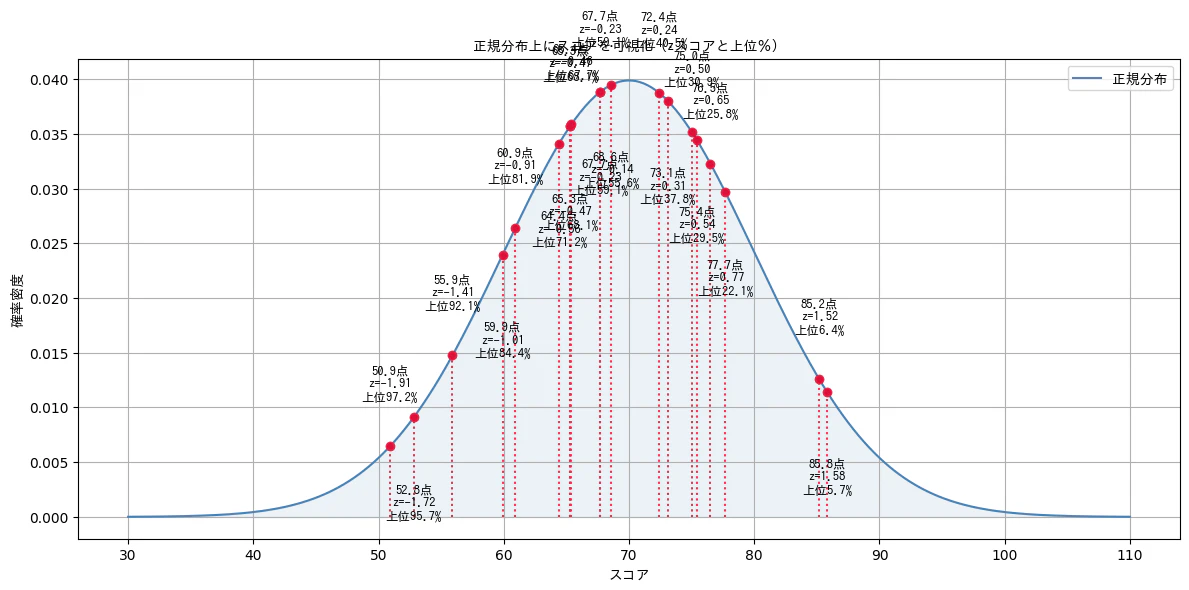
plt.figure(figsize=(12, 6))
plt.plot(x, y, label='正規分布', color='steelblue')
plt.fill_between(x, 0, y, alpha=0.1, color='steelblue')
# 📍 各スコアに点とzスコア・上位%のラベルを表示(重なり回避)
for i, row in df.iterrows():
score = row['スコア']
z = row['zスコア']
upper_pct = row['上位%']
pdf_y = norm.pdf(score, mu, sigma)
offset = 0.004 if i % 2 == 0 else -0.006 # ラベルを交互に上下に
va_align = 'bottom' if offset > 0 else 'top'
# 点と垂直線
plt.plot(score, pdf_y, 'o', color='crimson')
plt.vlines(score, 0, pdf_y, colors='crimson', linestyles='dotted')
# ラベル表示(スコア・zスコア・上位%)
plt.text(score, pdf_y + offset,
f"{score:.1f}点\nz={z:.2f}\n上位{upper_pct:.1f}%",
ha='center', va=va_align,
fontproperties=jp_font, fontsize=9)
# 🖋 グラフ装飾
plt.title("正規分布上にスコアを可視化(zスコアと上位%)", fontproperties=jp_font)
plt.xlabel("スコア", fontproperties=jp_font)
plt.ylabel("確率密度", fontproperties=jp_font)
plt.grid(True)
plt.legend(prop=jp_font)
plt.tight_layout()
plt.show()
# 📌 日本語フォントインストール(Google Colab専用)
!apt-get -y install fonts-ipafont-gothic > /dev/null
# 📦 ライブラリ
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
from scipy.stats import norm
# 🎌 日本語フォント設定(Colab用)
jp_font = FontProperties(fname="/usr/share/fonts/opentype/ipafont-gothic/ipag.ttf")
plt.rcParams['font.family'] = jp_font.get_name()
# ⚙️ 平均と標準偏差を設定
mu = 70
sigma = 10
# 🎲 スコアを正規分布からランダムに生成
np.random.seed(42)
scores = np.random.normal(loc=mu, scale=sigma, size=20).round(1)
# 🧮 zスコア・パーセンタイル計算
z_scores = (scores - mu) / sigma
lower_percentiles = norm.cdf(z_scores) * 100
upper_percentiles = 100 - lower_percentiles
# 📋 データフレームにまとめる
df = pd.DataFrame({
'スコア': scores,
'zスコア': z_scores,
'上位%': upper_percentiles
}).sort_values('スコア').reset_index(drop=True)
# 📈 正規分布の曲線データを作成
x = np.linspace(mu - 4*sigma, mu + 4*sigma, 400)
y = norm.pdf(x, mu, sigma)
# 🎨 グラフ描画
plt.figure(figsize=(12, 6))
# ⛅ ±2σ の塗り(全体95.4%)
plt.fill_between(x, 0, y, where=((x >= mu - 2*sigma) & (x <= mu + 2*sigma)),
color='orange', alpha=0.1, label='±2σの範囲')
# ⛅ ±1σ の塗り(全体68.3%)
plt.fill_between(x, 0, y, where=((x >= mu - sigma) & (x <= mu + sigma)),
color='yellow', alpha=0.3, label='±1σの範囲')
# 正規分布の曲線
plt.plot(x, y, label='正規分布', color='steelblue')
# スコアごとの点とラベル
for i, row in df.iterrows():
score = row['スコア']
z = row['zスコア']
upper_pct = row['上位%']
pdf_y = norm.pdf(score, mu, sigma)
offset = 0.004 if i % 2 == 0 else -0.006
va_align = 'bottom' if offset > 0 else 'top'
# 点と線
plt.plot(score, pdf_y, 'o', color='crimson')
plt.vlines(score, 0, pdf_y, colors='crimson', linestyles='dotted')
# ラベル表示
plt.text(score, pdf_y + offset,
f"{score:.1f}点\nz={z:.2f}\n上位{upper_pct:.1f}%",
ha='center', va=va_align,
fontproperties=jp_font, fontsize=9)
# 🖋 ラベルなど装飾
plt.title("正規分布と標準化得点:±1σ, ±2σの範囲と上位%", fontproperties=jp_font)
plt.xlabel("スコア", fontproperties=jp_font)
plt.ylabel("確率密度", fontproperties=jp_font)
plt.grid(True)
plt.legend(prop=jp_font)
plt.tight_layout()
plt.show()
📊 標準化得点(zスコア)とパーセンタイル範囲
| zスコアの範囲 | 含まれる割合(%) | パーセンタイル範囲(下位〜上位) | 意味・解釈 |
|---|---|---|---|
| ±1σ(-1.0〜+1.0) | 約68.3% | 16.0%〜84.1% | 平均的な値(よくある範囲) |
| ±2σ(-2.0〜+2.0) | 約95.4% | 2.3%〜97.7% | ほとんどの値(異常ではない) |
| ±3σ(-3.0〜+3.0) | 約99.7% | 0.15%〜99.85% | ほぼすべて(例外を除く) |
| z < -2.0 | 約2.3% | ~2.3% | 非常に低い値(まれ・要注意) |
| z > +2.0 | 約2.3% | 97.7%~ | 非常に高い値(優秀・外れ値の可能性) |
✅ パーセンタイルの意味:
- 50%:中央値(z=0)
- 16%:z = -1(平均−1σ)
- 84%:z = +1(平均+1σ)
- 2.3% / 97.7%:z = ±2
- 0.15% / 99.85%:z = ±3
上の表を持っておくと、標準化得点で上位何%なのかというのが判定できていいですね!
意思決定の指標になると思います!