はじめに
今回は統計検定2級の標準誤差について学んでいこうとおもいます!!
📊 標準誤差(Standard Error)とは?
標準誤差(SE) とは、サンプルから計算した 統計量(例:平均) のばらつきの程度を表す指標です。
🔍 標準誤差の意味
- 標準誤差は、「標本平均が母平均からどれくらいズレるか」 を示す。
- 同じ母集団から何度もサンプルを取って平均を計算すると、その平均値は毎回少しずつ違う。
- そのばらつきの大きさが標準誤差。
🧮 標準誤差の公式
母分散が既知の場合
$$
SE = \frac{\sigma}{\sqrt{n}}
$$
- $\sigma$:母標準偏差
- $n$:標本サイズ
母分散が未知の場合(通常はこちら)
$$
SE = \frac{s}{\sqrt{n}}
$$
- $s$:標本標準偏差
🧠 標準偏差との違い
| 用語 | 意味 |
|---|---|
| 標準偏差(SD) | データそのもののばらつき |
| 標準誤差(SE) | 標本平均など推定値のばらつき(=推定の不確かさ) |
📈 例:95%信頼区間の計算
サンプル平均 $\bar{x}$ の 95% 信頼区間は次のように表される:
$$
\bar{x} \pm 1.96 \times SE
$$
(※ 標本サイズが大きいときは正規分布近似が使える)
📘 想定問題(復習)
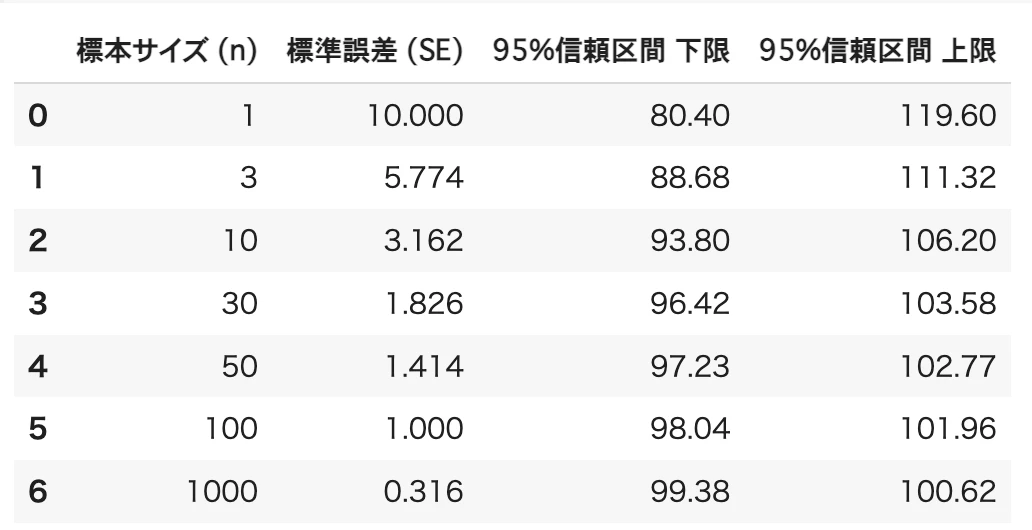
ある商品の重量は平均100g、標準偏差10gの正規分布に従うとする。
標本を n = 1, 3, 10, 30, 50, 100, 1000 個抽出したとき、母平均の95%信頼区間を求めよ。
# 📌 日本語フォントインストール(Google Colab専用)
!apt-get -y install fonts-ipafont-gothic > /dev/null
# ライブラリのインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
from scipy.stats import norm
# フォント設定(日本語対応)
jp_font = FontProperties(fname="/usr/share/fonts/opentype/ipafont-gothic/ipag.ttf")
plt.rcParams['font.family'] = jp_font.get_name()
# パラメータ設定
mu = 100 # 母平均
sigma = 10 # 母標準偏差
z = norm.ppf(0.975) # 95%信頼区間のz値(約1.96)
sample_sizes = [1, 3, 10, 30, 50, 100, 1000]
# 計算
data = []
for n in sample_sizes:
se = sigma / np.sqrt(n)
lower = mu - z * se
upper = mu + z * se
data.append({
"標本サイズ (n)": n,
"標準誤差 (SE)": round(se, 3),
"95%信頼区間 下限": round(lower, 2),
"95%信頼区間 上限": round(upper, 2)
})
df = pd.DataFrame(data)
display(df)
# グラフ描画
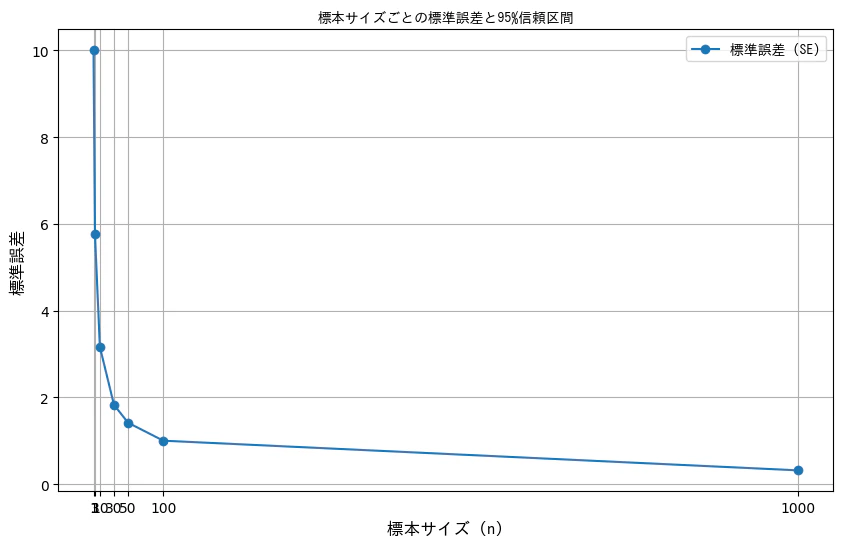
plt.figure(figsize=(10, 6))
plt.plot(sample_sizes, df["標準誤差 (SE)"], marker='o', label='標準誤差 (SE)')
plt.title("標本サイズごとの標準誤差と95%信頼区間", fontsize=14, fontproperties=jp_font)
plt.xlabel("標本サイズ (n)", fontsize=12, fontproperties=jp_font)
plt.ylabel("標準誤差", fontsize=12, fontproperties=jp_font)
plt.grid(True)
plt.xticks(sample_sizes)
plt.legend(prop=jp_font)
plt.show()