Quarkus の REST API で日本語入りの PDF ファイル出力に挑戦。
Java のシステムで往々にしてあるのが PDF出力 でありまして、業務システムで出力する PDF は当然、日本語が入ってくるわけでございます。
そして、なんで今更、しかも Quarkus でチャンレンジしようとしたかと申しますと・・・
こちら、Quarkus の本家リポジトリでプラグインの一覧でございます。
ある日、"Quarkusのプラグインって何が使えるのかしら〜?" と一覧を眺めていると・・・
...
spring-web
swagger-ui
tika
undertow-websockets
...
ん?!待って・・・tika?
あの、tika だよね?オフィス文書とかPDFから文字列抽出するライブラリ、Apache Tika、だよね?!
そう、Tika の中には様々な形式のファイルができるようにそれに対応したライブラリが含まれているわけです。Tika はテキスト抽出がメインのライブラリなので、Tikaのインタフェースではテキストの読み込みしかできませんが、同梱のライブラリを直接、使用すればオフィス文書の読み書きだってできるのです!
そしてここに tika プラグインがあるということは・・・Tika とそれに付随するライブラリが Native化、可能だってことなわけですよね!?
当然、PDFからのテキスト抽出に使われている PDFBox だって使えるはず!ってわけです。これはもう、試してみるしかないでしょう!!
ついでに、日本語フォントも同梱してみて、Quarkusでちゃんと出力できるか、確認してみたいと思います!
1. プロジェクトの作成
以下のコマンドでプロジェクトを作成いたします。例によって、REST APIのサンプルは生成しておいてください〜
$ mvn io.quarkus:quarkus-maven-plugin:1.0.0.CR1:create
...
$ cd my-quarkus-project
(あれ、いつの間にか Quarkus のバージョンが上がってますね・・・)
続いてpom.xml にプラグインを追加します。
前回の記事(【2019年11月版】Quarkus で Hibernate-Panache の REST API 作ってネイティブ化し Jaeger でトレース)の構成に tikaプラグインを追加したものです。Hibernate経由でPostgreSQLに保存したデータもPDFに書き込んでみようという前衛的な構成です。
...
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-smallrye-opentracing</artifactId>
</dependency>
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-jdbc-postgresql</artifactId>
</dependency>
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-smallrye-metrics</artifactId>
</dependency>
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-smallrye-openapi</artifactId>
</dependency>
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-hibernate-orm-panache</artifactId>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.datatype</groupId>
<artifactId>jackson-datatype-jsr310</artifactId>
</dependency>
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-tika</artifactId>
</dependency>
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-resteasy-jsonb</artifactId>
</dependency>
<dependency>
<groupId>io.opentracing.contrib</groupId>
<artifactId>opentracing-jdbc</artifactId>
</dependency>
...
もちろん Opentracing 対応です! PDF の吐き出しにどの時間がかかるかチェックするためです。
2. モデルクラスとREST APIの作成
ここは前回の記事と同じ手順ですので実装コードだけご紹介します。(といっても大したことないんですが・・・)
まず、Hibernateの接続設定から。
quarkus.datasource.url = jdbc:tracing:postgresql://db:5432/mydatabase
quarkus.datasource.driver=io.opentracing.contrib.jdbc.TracingDriver
quarkus.hibernate-orm.dialect=org.hibernate.dialect.PostgreSQLDialect
quarkus.datasource.username = postgres
quarkus.datasource.password = postgres
# drop and create the database at startup (use `update` to only update the schema)
quarkus.hibernate-orm.database.generation = drop-and-create
接続先が docker-compose.yml で指定するサービス名 db になってますのでご注意!
mvn quarkus:dev で開発サーバー起動する場合には接続エラーになるので、その際には docker.for.mac.host.internal などdockerホストを参照してください。
続いてモデルクラス。
import javax.persistence.Entity;
import java.time.LocalDate;
import io.quarkus.hibernate.orm.panache.PanacheEntity;
import com.fasterxml.jackson.annotation.JsonFormat;
@Entity
public class Person extends PanacheEntity {
public enum Status {
Alive, DECEASED
}
public String name;
@JsonFormat(pattern = "yyyy-MM-dd")
public LocalDate birth;
public Status status;
}
お次は REST APIです。
package org.acme.quarkus.sample;
import javax.transaction.Transactional;
import javax.ws.rs.GET;
import javax.ws.rs.POST;
import javax.ws.rs.Path;
import javax.ws.rs.PathParam;
import javax.ws.rs.Produces;
import javax.ws.rs.core.MediaType;
import org.eclipse.microprofile.metrics.MetricUnits;
import org.eclipse.microprofile.metrics.annotation.Timed;
import org.eclipse.microprofile.metrics.annotation.Counted;
import org.acme.quarkus.sample.model.Person;
@Path("/person")
@Produces(MediaType.APPLICATION_JSON)
public class PersonResource {
@POST
@Transactional
@Produces(MediaType.APPLICATION_JSON)
@Counted(name = "performed_create", description = "How many it have been called.")
@Timed(name = "checksTimer_create", description = "A measure of how long it takes to perform creating person.", unit = MetricUnits.MILLISECONDS)
public Person create(Person person) {
person.persist();
return person;
}
@GET
@Path("/{id}")
@Transactional
@Counted(name = "performed_get", description = "How many it have been called.")
@Timed(name = "checksTimer_get", description = "A measure of how long it takes to perform getting person.", unit = MetricUnits.MILLISECONDS)
public Person get(@PathParam("id") Long id) {
return Person.findById(id);
}
@GET
@Path("/{id}")
@Transactional
@Produces(MediaType.TEXT_HTML)
@Counted(name = "performed_html", description = "How many it have been called.")
@Timed(name = "checksTimer_html", description = "A measure of how long it takes to perform getting person.", unit = MetricUnits.MILLISECONDS)
public Person getHTML(@PathParam("id") Long id) {
return Person.findById(id);
}
@GET
@Path("/{id}/pdf")
@Produces("application/pdf")
@Transactional
@Counted(name = "performed_pdf", description = "How many it have been called.")
@Timed(name = "checksTimer_pdf", description = "A measure of how long it takes to perform getting person.", unit = MetricUnits.MILLISECONDS)
public Person getByPDF(@PathParam("id") Long id) {
return Person.findById(id);
}
}
今回は前回のメソッドにPDF出力用と、さらにHTML出力用のエンドポイントをお二つご用意いたしました!
PDF出力用がgetByPDF、HTML出力用がgetHTML となっております。(命名が適当すぎてごめんなさい。。。)
が・・・実装というかシグネチャをよくみていただくとお分かりの通りで、メソッド名以外に何が違うの?というところでありますよね?
public Person get(@PathParam("id") Long id)とpublic Person getHTML(@PathParam("id") Long id)とpublic Person getByPDF(@PathParam("id") Long id)、メソッド名以外は引数も戻り値も同じなんです。
何が違うのか・・・
@Producesで示された、"返却されるコンテンツのタイプ"が違うんです!
で、@Produces(MediaType.APPLICATION_JSON) については前回の記事でもできた通りquarkus-resteasy-jsonbプラグインのパワーで Person Bean をほぼ自動で JSON にすることはできました。
それ以外のメディアタイプについては? ・・・以下の手順になります!
3. カスタムの MessageBodyWriter の実装。
カスタムのメディアタイプに対応するための仕組みが MessageBodyWriterインタフェースの実装となります。
まず、サンプルの実装を元にMessageBodyWriterの実装手順を解説します。
3-1. サンプルのHTML用MessageBodyWriterの実装
例えば PersonBeanからHTMLを出力するカスタムのMessageBodyWriterは以下のような実装となります。
package org.acme.quarkus.sample.writer;
import java.io.IOException;
import java.io.OutputStream;
import java.io.PrintWriter;
import java.io.Writer;
import java.lang.annotation.Annotation;
import java.lang.reflect.Type;
import javax.ws.rs.Produces;
import javax.ws.rs.WebApplicationException;
import javax.ws.rs.core.MediaType;
import javax.ws.rs.core.MultivaluedMap;
import javax.ws.rs.ext.MessageBodyWriter;
import javax.ws.rs.ext.Provider;
import org.acme.quarkus.sample.model.Person;
@Provider
@Produces(MediaType.TEXT_HTML)
public class HTMLWriter implements MessageBodyWriter<Person> {
@Override
public boolean isWriteable(Class<?> type, Type genericType, Annotation[] annotations, MediaType mediaType) {
return true;
}
@Override
public void writeTo(Person t, Class<?> type, Type genericType, Annotation[] annotations, MediaType mediaType,
MultivaluedMap<String, Object> httpHeaders, OutputStream entityStream)
throws IOException, WebApplicationException {
Writer writer = new PrintWriter(entityStream);
writer.write("<html>");
writer.write("<body>");
writer.write("<h2>JAX-RS Message Body Writer Example</h2>");
writer.write("<p>Id: " + t.id + "</p>");
writer.write("<p>Name: " + t.name + "</p>");
writer.write("</body>");
writer.write("</html>");
writer.flush();
writer.close();
}
}
ポイントとしては、
- MessageBodyWriter で受け取るBeanの型を指定した MessageBodyWriter をimplementsする。
- @Produces でこのMessageBodyWriterが出力するメディアタイプを宣言する。
- @Provider でこのクラスをDIコンテナに対してDIしてねと宣言する。
-
isWriteable、writeToの実装
となります。
isWriteable は引数のオブジェクトに対してこのMessageBodyWriterが対応可能かどうかを判断するメソッドです。PersonからHTMLを出力するだけなので適当にtrueを返しておきます。クラスに対して @Produces は複数の設定が可能なので、想定される型の範囲かどうかをチェックするのが本来の役目なんじゃないでしょうか。
続いて、writeToメソッドが実際のコンテンツの作成処理です。ここでは HTMLタグを直打ちしてますが、このようにダウンロードさせたいデータを生成するのがこのメソッドの役割です。
3-2. PDF出力の準備・・・日本語フォント
それでは本丸のPDF用MessageBodyWriterです・・・の前に、今回の目的その2の日本語対応です。
PDFBoxが標準で対応している(Enumで宣言している)フォントの中に日本語のフォントは含まれていません。よって日本語フォントは自前でダウンロードしておく必要があります。
ついでにそのフォントファイルを開いてフォントを指定してPDFを出力する・・・のはちょっとテクニック?が必要なので以下のサイトをご紹介しておきます。
いつも大変お世話になっております、ひしだまさんとこのサイトです。
またここからリンクされている IPA フォントのページもリンクを貼っておきます。
今回は上記サイトからゴシックフォント用のTTCファイル(のZIP)をダウンロードして main/resource 以下に解凍しておきました。
フォントの実際のパスはsrc/main/resources/IPAGTTC00303/ipag.ttcとなります。
プログラムから参照する場合は、IPAGTTC00303/ipag.ttcですね。
フォントファイルの準備ができたところで、PDF出力処理は以下のようにいたしました。
3-3. PDF用MessageBodyWriterの実装
以下のようになります。
package org.acme.quarkus.sample.writer;
import java.io.IOException;
import java.io.OutputStream;
import java.lang.annotation.Annotation;
import java.lang.reflect.Type;
import javax.json.bind.JsonbBuilder;
import javax.ws.rs.Produces;
import javax.ws.rs.WebApplicationException;
import javax.ws.rs.core.MediaType;
import javax.ws.rs.core.MultivaluedMap;
import javax.ws.rs.ext.MessageBodyWriter;
import javax.ws.rs.ext.Provider;
import org.acme.quarkus.sample.model.Person;
import org.apache.fontbox.ttf.TrueTypeCollection;
import org.apache.fontbox.ttf.TrueTypeFont;
import org.apache.fontbox.ttf.TrueTypeCollection.TrueTypeFontProcessor;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.pdmodel.PDPage;
import org.apache.pdfbox.pdmodel.PDPageContentStream;
import org.apache.pdfbox.pdmodel.common.PDRectangle;
import org.apache.pdfbox.pdmodel.font.PDFont;
import org.apache.pdfbox.pdmodel.font.PDType0Font;
@Provider
@Produces("application/pdf")
public class PDFWriter implements MessageBodyWriter<Person> {
@Override
public boolean isWriteable(Class<?> type, Type genericType, Annotation[] annotations, MediaType mediaType) {
return true;
}
@Override
public void writeTo(Person t, Class<?> type, Type genericType, Annotation[] annotations, MediaType mediaType,
MultivaluedMap<String, Object> httpHeaders, OutputStream entityStream)
throws IOException, WebApplicationException {
try(TrueTypeCollection ttc = new TrueTypeCollection(PDFWriter.class.getClassLoader().getResourceAsStream("IPAGTTC00303/ipag.ttc"))){
// ttc.processAllFonts(ttf -> System.out.println(ttf.getName()));
try (PDDocument document = new PDDocument()) {
PDPage page = new PDPage(PDRectangle.A4);
document.addPage(page);
// PDFont font = PDType1Font.HELVETICA;
PDFont font = PDType0Font.load(document, ttc.getFontByName("IPAGothic"), false);
PDFont font_p = PDType0Font.load(document, ttc.getFontByName("IPAPGothic"), false);
try (PDPageContentStream cs = new PDPageContentStream(document, page)) {
cs.beginText();
cs.setFont(font_p, 12);
cs.newLineAtOffset(30, 600);
cs.showText("JSON:" + JsonbBuilder.create().toJson(t));
cs.newLineAtOffset(0, -100);
cs.showText("僕はなんだか日本語を出力してみたい気持ちに駆られたのであった。ダメね。あなたはいつもこんな調子で。");
cs.setFont(font, 12);
cs.newLineAtOffset(0, -100);
cs.showText("僕はなんだか日本語を出力してみたい気持ちに駆られたのであった。ダメね。あなたはいつもこんな調子で。");
cs.endText();
}
document.save(entityStream);
}
}
}
}
ちなみに java で日本語フォントを扱う上で一番厄介なのがgetFontByNameで指定するフォント名ですね。これ、最初からわかるサイトとかツールとかないんでしょうか?
javaのプログラムで以下のように・・・
ttc.processAllFonts(ttf -> System.out.println(ttf.getName()));
とかやって中身を取り出してみないとフォントファイルに格納されている正しいフォント名の綴りがわからないんですけど??
PDFの座標系は左下が原点(0,0)隣、上方向、右方向がプラスとなります。つまり、上からプロットすると一旦、一番上まであげて、マイナスYで下に下がっていくようなプログラムを書くことになります。
特に今回、使用したPDPageContentStream#newLineAtOffset は前回指定した開始位置からの相対座標となるので、(0,-100)のようにダイレクトにマイナスの値を入れていくことになります。
あとは PSF に好きに文字なり線なりを書き込んで、entityStreamに書き込めば出来上がりです!
実際のダウンロードの処理=Mime type: multipart の処置はよろしくやってくれます。これだけでもめちゃくちゃ便利ですね。。。
4. DB、Jaegerの用意など
ここは前回と同じですので割愛させていただきます。
5. ネイティブ化
今回のネイティブ化に当たって一番苦労したのが、外部リソースというかフォントファイルの取り込みです。。。
以下で手順をご紹介いたします。
5-1. リソースファイルの取り込み
ネイティブ化に当たって、外部リソースの含め方についてはこちらに解説があります。
resource/META-INF以下は Web用のリソースなので自動で取り込まれますよ〜ということと、それ以外のパスは自分でやってね!ということなので、頑張ります!
パターンについてはgithubサイトの解説の方により詳しく載っています。
またこちらのブログ記事も非常に参考になりました。
今回は必要なフォント一つだけですが、*.ttc を含めるように 設定用のjsonを作成しましょうか。
{
"resources": [
{
"pattern": ".*\\.ttc$"
}
]
}
で、このファイルをネイティブビルド時に読み込まれるように applications.properties に追記します。
...
quarkus.native.additional-build-args=-H:ResourceConfigurationFiles=${project.basedir}/src/main/resources/resources-config.json
ちなみに、上記のプロパティは mvn quarkus:dev ではあっさりエラーとなり、サーバーが起動しません。。。無視してくれていいのに、無視してくれません。
5-2. ビルド用Dockerの準備
いつものようにネイティブのビルドには GraalVMがインストール済みのイメージを使います。
Dockerfile は以下のようになります。
## Stage 1 : build with maven builder image with native capabilities
FROM quay.io/quarkus/centos-quarkus-maven:19.2.1 AS build
COPY src /usr/src/app/src
USER root
RUN chown -R quarkus /usr/src/app
USER quarkus
RUN mvn -f /usr/src/app/pom.xml -Pnative -Dmaven.test.skip=true clean package
## Stage 2 : create the docker final image
FROM registry.access.redhat.com/ubi8/ubi-minimal
WORKDIR /work/
COPY --from=build /usr/src/app/target/*-runner /work/application
RUN chmod 775 /work
EXPOSE 8080
CMD ["./application", "-Dquarkus.http.host=0.0.0.0"]
で、これを使用するdocker-compose.yamlを作成いたします。
version : "3"
services:
quarkus:
build:
context: .
ports:
- 8082:8082
networks:
- default
- monitor-net
depends_on:
- jaeger
- db
db:
image: postgres
ports:
- 5432:5432
environment:
- POSTGRES_DB=mydatabase
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=postgres
adminer:
image: adminer
restart: always
ports:
- 8080:8080
jaeger:
image: jaegertracing/all-in-one
environment:
- COLLECTOR_ZIPKIN_HTTP_PORT=9411
ports:
- 5775:5775/udp
- 6831:6831/udp
- 6832:6832/udp
- 5778:5778
- 16686:16686
- 14268:14268
- 9411:9411
networks:
monitor-net:
external:
name: dockprom_monitor-net
Hibernateの接続先を db としたので、PostgreSQLのサービス名は db としています。
また jaeger も同様です。
以下のコマンドでビルド&実行致します。
$ docker-compose up -d
6. 実行、しかし!!
無事にコンテナが起動したら以下のコマンドでデータ投入とPDFのダウンロードをしてみます。
$ curl -H 'Content-Type:application/json' -d '{"name":"Alice","birth":"2010-10-11","status":"Alive"}' http://localhost:8082/person
...
$ curl -o 1.pdf -H 'content-type: application/pdf' http://localhost:8082/person/1/pdf
...
注意点としてはPDFやHTMLの生成ロジックはあくまで Personのコンバーター として実装されている、という点です。つまり、対象のレコードがなければコンバートされない=データが返ってきません。(HTTPステータスは200で正常なのに。)
で、ここでダウンロードした PDF を開こうとすると・・・エラーで開けません!!
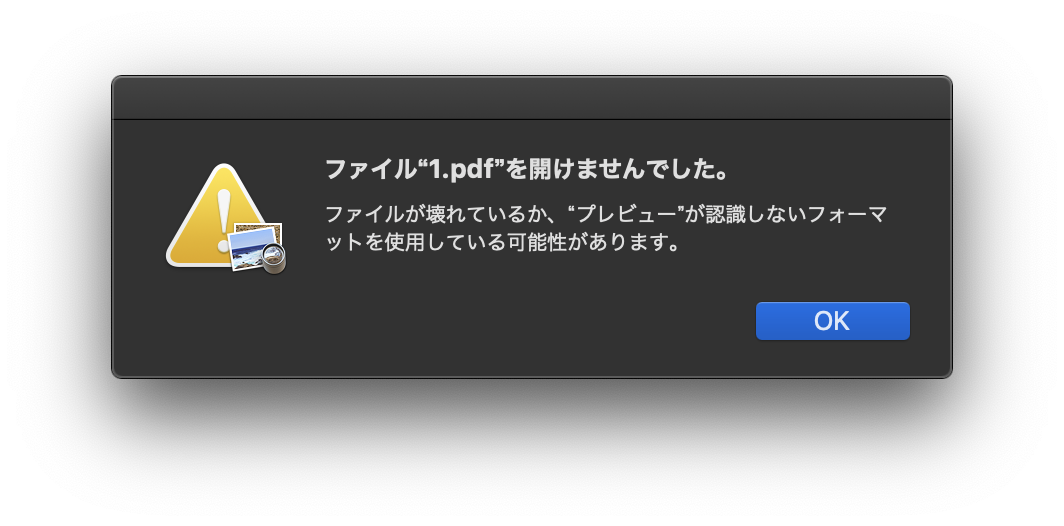
Oh...no...
Quarkusのログを確認すると実行時エラーで以下のような例外が発生しています。
Caused by: java.io.IOException: Error: Could not find referenced cmap stream Identity-H
Identity-Hとはなんぞや?と色々探してみましたが、PDFのコード変換表のようです。また、以下のfontboxに含まれるリソースとして定義ファイルがありましたが、これが見つからないようです・・・
色々試してみたのですが、fontbox もしくは pdfboxのjarの中にあるリソースをちゃんと実行バイナリの中に含める、という設定の仕方がよくわかりませんでした・・・
(もちろん、ネイティブビルドしなければ正常にPDF出力は行えます。)
うーん、残念ですが、日本語フォントの取り扱い?はネイティブ化対応できていないようですね。
以下のようなチケットにも PDType1Font のネイティブ対応はできたよ的な内容から、「PDType0Fontはまだだけどね・・・」というニュアンスが勝手に伺えてしまいます。。
ちなみに
docker-composeで"quarkus"を止めて、mvn quarkus:dev で開発サーバーが動きますが、その時は普通に動くんですよ〜。。。
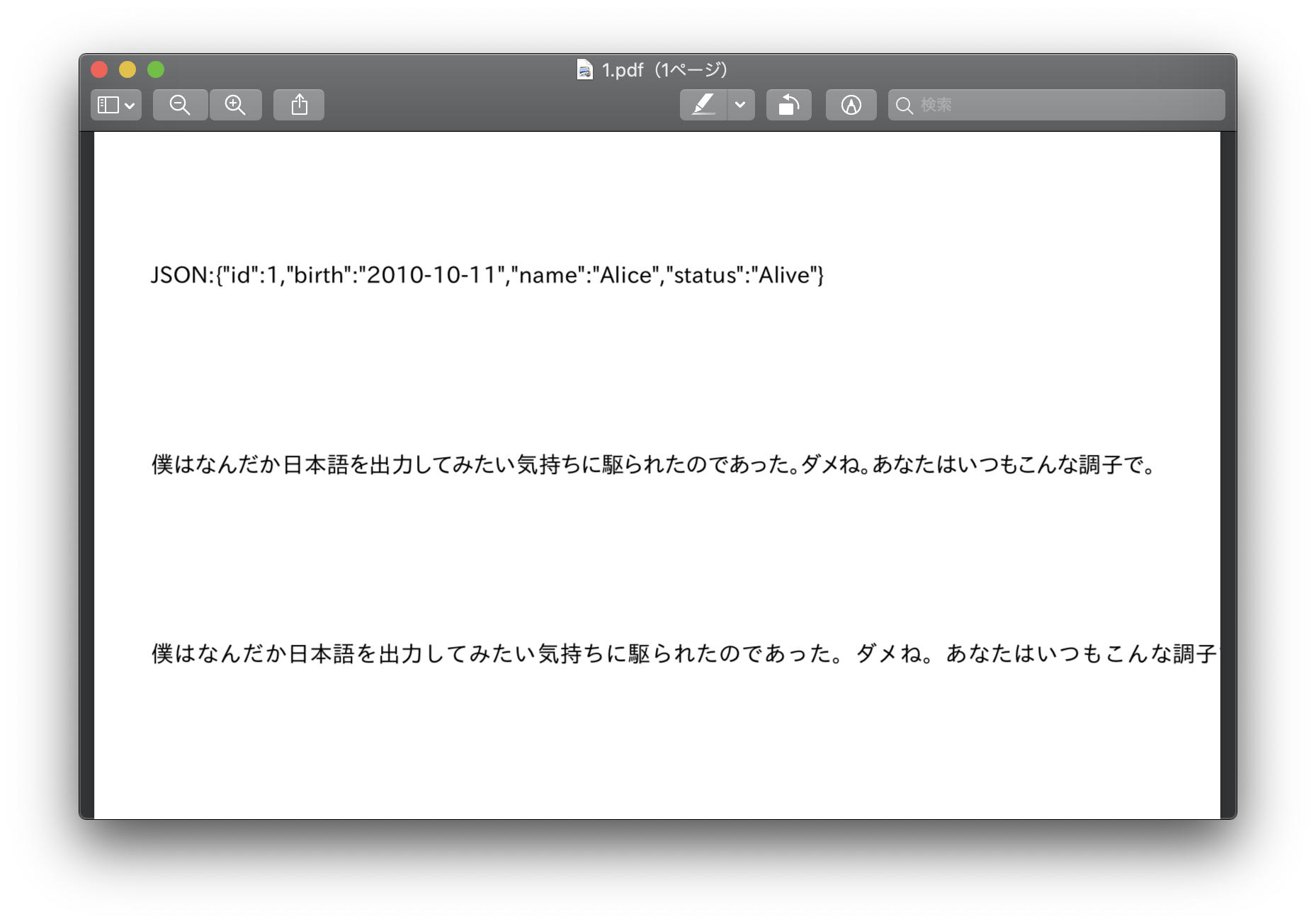
これは普通に OpenJDKで動いてますからね・・・普通のJavaプログラムです。はい。。。
まとめ
ネイティブ化して日本語フォントを埋め込んだPDFを生成してみようという野心的な試みでしたが、やはりフォントの壁は厚かったですね。
Quarkusは1.0のリリースに向けて新規機能の開発は一旦、収束しちゃっているような感じですが・・・近いうちにPDType0Fontのサポートもしてくれるといいなぁ・・・
一応、今回の成果物は以下のリポジトリにあげました。
ということで、今回は以上です!