unseen dataに関して
PyCaretを勉強していると、unseen dataをテストデータと勘違いしそうですが、unseen dataはテストデータではあるのですが詳しく説明すると、
トレーニングデータで予測モデルを作成
トレーニングデータにテストデータを組み合わせて最終予測モデルを作成
最後に、そのモデルにunseen dataを入力して、モデルの精度を確認
という流れになります。
前回のおさらい
たった数行で機械学習体験(前編)。PyCaretを詳しく解説。データセット準備から複数モデルの精度比較まで。の続きになります。
前回はデータセットの準備から、モデルの精度比較まで行いました。
今回の目的
part2では、モデルの作成から、プロット、最終モデルの作成までを行います。
訓練データを使ってモデルを作成
compare_models()の目的は、トレーニングされたモデルを作成する事ではなく、パフォーマンスの高いモデルを評価し、モデルの候補を選定する為にあります。今回は、ランダムフォレストを使ってモデルをトレーニングします。
rf = create_model('rf')
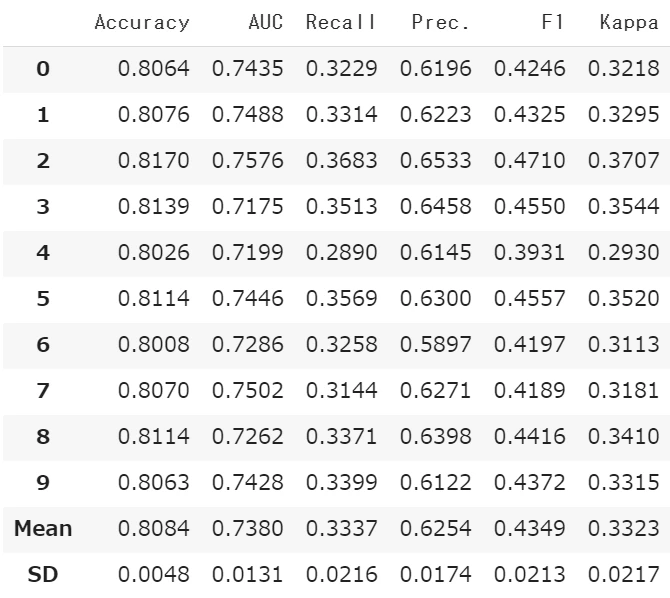
tune_model()は、ハイパーパラメーターのランダムグリッドサーチです。デフォルトでは、精度を最適化するように設定されています。
tuned_rf = tune_model('rf')
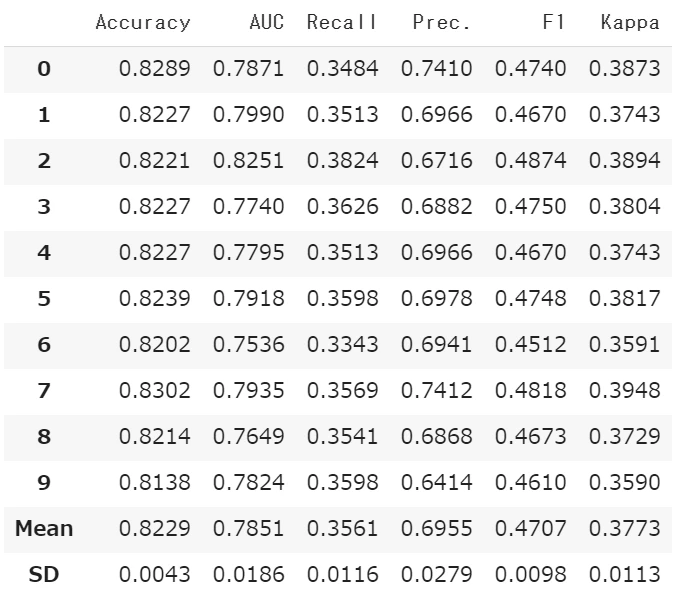
例えば、ランダムフォレストで、AUCの値を高くするモデルを作成したい場合は、以下のようなコードになります。
tuned_rf_auc = tune_model('rf', optimize = 'AUC')
tuned_modelで作成したモデルの方が、1.45%精度が高くなったので、こちらを使っていきます。
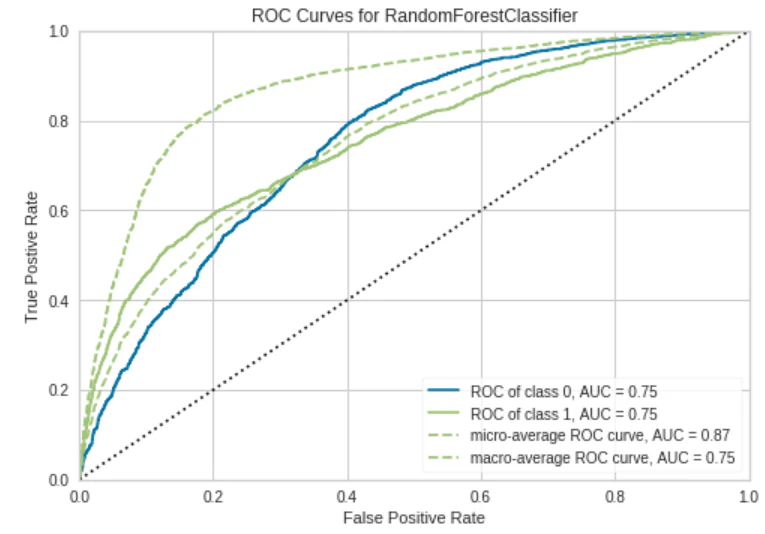
モデルの精度をプロット
AUC Plotを実行
plot_model(tuned_rf, plot = 'auc')
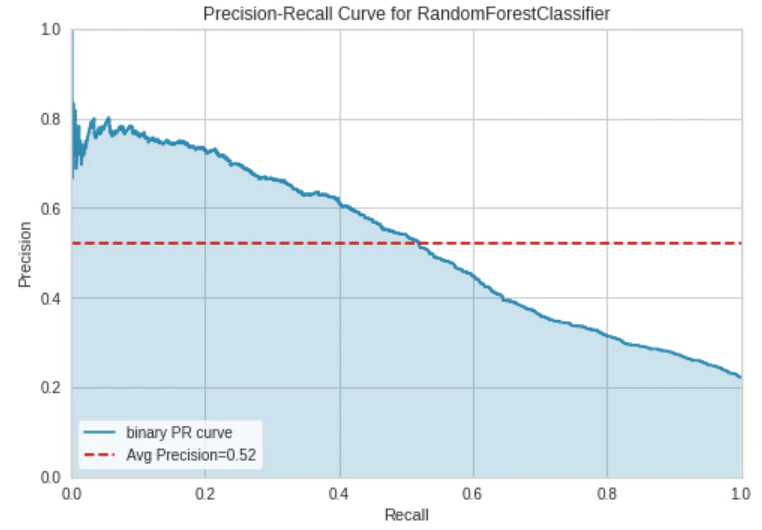
Precision-Recall Curve
plot_model(tuned_rf, plot = 'pr')
Feature Importance Plot
plot_model(tuned_rf, plot='feature')

evaluate_model(tuned_rf)

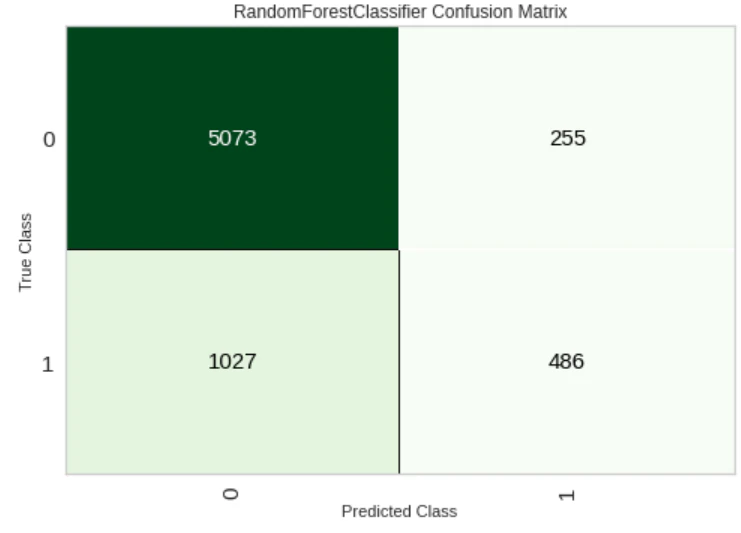
Confusion Matrix
plot_model(tuned_rf, plot = 'confusion_matrix')
訓練データとテストデータを組み合わせて予測モデルの作成へ
最終的に予測モデルを完成させる前に、テストデータを使って、学習モデルが過剰適合していないか確認します。ここで、精度の差が大きくなってしまう場合は、検討が必要になりますが、今回は精度に大きな違いは無いので先に進みます。
predict_model(tuned_rf);

いよいよ最終版の予測モデルが完成します。
ここのモデルには、トレーニングデータとテストデータが組み合わさったモデルが完成されます。
final_rf = finalize_model(tuned_rf)
print(final_rf)
RandomForestClassifier(bootstrap=True, ccp_alpha=0.0, class_weight=None,
criterion='gini', max_depth=10, max_features='auto',
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=2, min_samples_split=10,
min_weight_fraction_leaf=0.0, n_estimators=70,
n_jobs=None, oob_score=False, random_state=123,
verbose=0, warm_start=False)
predict_model(final_rf);

精度やAUCのパフォーマンスが高くなっていますね。これはテストデータが組み合わさり、予測モデルの品質が向上したからです。
unseen dataを用いてモデルの評価
では、最後にunseen data(1200のデータセット)を使って、予測モデルを評価します。
unseen_predictions = predict_model(final_rf, data=data_unseen)
unseen_predictions.head()

データセットに、LabelとScoreが追加されています。
Labelは、モデルが予測したラベルになります。
Scoreは、予測の確率になります。
モデルの保存
予測する新しいデータが増えた場合に、もう一度最初から実行するのは大変です。PyCaretには、save_modelが用意されており、モデルを保存しておく事ができます。
save_model(final_rf,'Final RF Model')
Transformation Pipeline and Model Succesfully Saved
保存したモデルのロード
モデルのロードをするには、以下を実行します。
saved_final_rf = load_model('Final RF Model')
Transformation Pipeline and Model Sucessfully Loaded
先ほどのunseen dataを使います。結果は、先ほどと同じなので省略します。
new_prediction = predict_model(saved_final_rf, data=data_unseen)
new_prediction.head()
さいごに
Level Beginnerチュートリアルの解説の実行をしてみました。
十数行で、ここまでできてしまうのはびっくりです。
機械学習をするハードルが、さらに低くなった気がします。
ご指摘等あれば、コメントいただければと思います。
読んでいただき、ありがとうございました。