MySQLのインデックスにはB+Treeと呼ばれる木構造が使用されている。
似たような木構造にB-Treeがあると知り、違いに触れつつ両方の木構造を説明してみる。
インデックスとはなんぞや?、という方は別の記事等を参照してからお読みください。
B-Tree
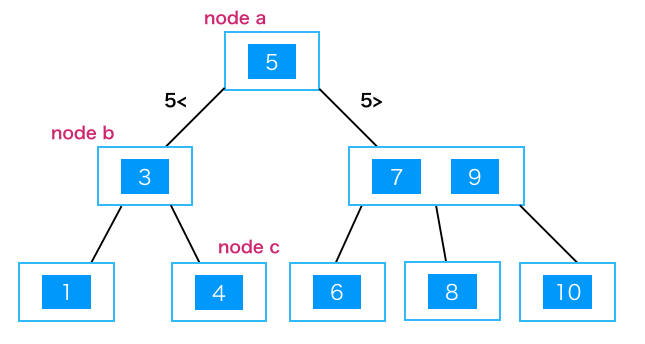
- 各ノードは値を保持し、また2つ以上の子ノードを保持することがある。
- 値を検索する場合はルートノードから順番に大小を比較して検索していく。
- 例えば4を検索したい場合は、node a → node b → node cという順序で検索する。
- メリットは検索回数が少なくてすむ(=計算量が少なくてすむ) ∵基本的に階層の数だけ検索すればいいから。
- 子ノードの数が2に固定されているB-Treeが
二分探索木である。 - MongoDBのインデックスに使われているらしい。
B+Tree
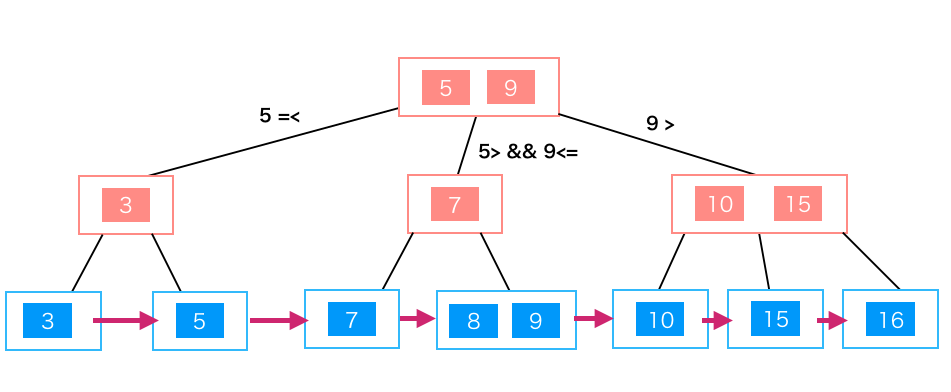
- B-Treeとは異なり各ノードではなくリーフノード(上記の図の青い部分)でデータを持つ(リーフノードがデータを持つのでキー値がノードと被る)
- リーフノードがポインタでつながっている。
それぞれのメリット
- B-Treeはノードもデータを持つので、探索途中でヒットすればレスポンスが早いことがある。
- B+Treeは複数ノードにまたがる範囲検索を効率的に行える。