前回まででサーバリソース、Nginx、phpfpmの監視がある程度出来ている状態です。
ここでは各種アラートメールを設定していきます。
ルール構築
種類としては以下を用意
- cpu.yml
- disk.yml
- memory.yml
- nginx.yml
- php-fpm.yml
- system.yml(インスタンスダウンやロードアベレージ)
良く見る部分だけでアラート対象としてみました。
アラートメールのサンプル
以下の設定でメール通知を全てチェックしているわけではないです。
そもそも、手探りなので間違いはあると思います。
cpu
- name: cpu_check
rules:
- alert: cpu_used_warn
# CPU 使用率が 80% を超えた時を条件にしています
expr: 100 * (1 - avg(rate(node_cpu{mode='idle'}[5m])) BY (instance)) > 80
for: 5m
labels:
severity: warning
annotations:
summary: "cpu used over 80%"
description: "CPU使用率が80%を超えて5分経過してます"
- alert: cpu_used_err
# CPU 使用率が 90% を超えた時を条件にしています
expr: 100 * (1 - avg(rate(node_cpu{mode='idle'}[5m])) BY (instance)) > 90
for: 5m
labels:
severity: critical
annotations:
summary: "cpu used over 90%"
description: "CPU使用率が90%を超えて5分経過してます"
ちなみにメールは以下のような感じで通知されました。
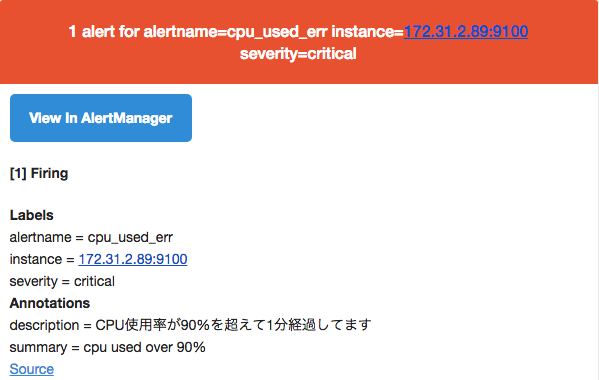
※IP出てますがローカルIPだし、prometheusの確認用なのでいいかなと。
disk
本当は「/」固定ではなくてsumを使って閾値を設けたかったのですがうまくできませんでした。
groups:
- name: disk_check
rules:
- alert: disk_space_warn
expr: node_filesystem_avail{mountpoint='/', device!~'rootfs'} / node_filesystem_size * 100 < 30
for: 5m
labels:
severity: warnings
annotations:
summary: "running out of hard drive space"
description: "ディスクスペースが70%をきってから5分経過してます"
- alert: disk_space_warn
expr: node_filesystem_avail{mountpoint='/', device!~'rootfs'} / node_filesystem_size * 100 < 20
for: 5m
labels:
severity: critical
annotations:
summary: "running out of hard drive space"
description: "ディスクスペースが80%をきってから5分経過してます"
memory
groups:
- name: memory_check
rules:
- alert: memory_warn
expr: 100 * ((node_memory_MemFree + node_memory_Active_file + node_memory_Inactive_file)/node_memory_MemTotal) < 30
for: 5m
labels:
severity: warning
annotations:
summary: "memory is getting low"
description: "メモリ空き容量が30%以下になって5分経過してます"
- alert: memory_critical
expr: 100 * ((node_memory_MemFree + node_memory_Active_file + node_memory_Inactive_file)/node_memory_MemTotal) < 20
for: 5m
labels:
severity: critical
annotations:
summary: "memory is getting low"
description: "メモリ空き容量が20%以下になって5分経過してます"
nginx
アクティブな接続数で閾値を設けて見ました。
値も見たいので{$labels.value}も使ってます。
groups:
- name: nginx_check
rules:
- alert: status
expr: nginx_up == 0
for: 5m
labels:
severity: critical
annotations:
summary: "nginx down"
description: "nginxが停止してから5分が経過してます"
- alert: active_connections_warn
expr: nginx_connections_current{state="active"} > 700
for: 5m
labels:
severity: warning
annotations:
summary: "active connection over 700"
description: "nginxでアクティブなコネクションが700を超えて5分経過してます 値={{ $labels.value }}"
- alert: active_connections_critical
expr: nginx_connections_current{state="active"} > 900
for: 5m
labels:
severity: critical
annotations:
summary: "active connection over 900"
description: "nginxでアクティブなコネクションが900を超えて5分経過してます 値={{ $labels.value }}"
phpfpm
nginxと似たような感じにしました。
groups:
- name: phpfpm_check
rules:
- alert: process_count_warn
expr: phpfpm_active_max_processes > 700
for: 5m
labels:
severity: warning
annotations:
summary: " process over 700"
description: "phpfpmのプロセスが700を超えて5分経過してます 値={{ $labels.value }}"
- alert: process_count_critical
expr: phpfpm_active_max_processes > 900
for: 5m
labels:
severity: critical
annotations:
summary: "process over 900"
description: "phpfpmのプロセスが900を超えて5分経過してます 値={{ $labels.value }}"
system
インスタンスダウンだけですが、「node_load1」等を使ってロードアベレージも対象にしていきたい。
groups:
- name: system_check
rules:
# alert: アラート名
- alert: InstanceDown
# expr: alert push の閾値
expr: up == 0
for: 5m
labels:
severity: critical
annotations:
summary: "Instance down"
description: "停止してから5分が経過してます"
まとめ
冒頭に記載しているとおり、全てチェックしたものではないです。
あくまでサンプルとして確認してて実際に監視ツールとして活用する場合は、
検証して設定を決めていきます。
一通り触ってみた結果、muninから移行してもいいかなと思いました。
grafanaは見てて楽しいですし、アラート制御がやっぱり強いように思えました。
ただ、alertmanagerのwarningとcriticalの集約がうまくできず、
両方通知されてしまうのでそこは確認していきたい。