概要
実装の品質を実際に測るため、実験を走らせているものです。
しかし、その実験から出た指標データを上手く集めて、理解できやすい図・テーブルで表せることは手動的に面倒です。
指標をスプレッドシートに挿入する研究者はまだ多いと思われています。
matplotlib・plotly といった色々なデータから図を作るソフトがありますが、
そのソフトを早速に使うことができないし、研究者に大切に扱われる tex フォマットになかなか対応できません。
簡単なコマンドで自動的に実験のデータから tex までの方法は sqlplot です。
sqlplot は tex ファイルの中に特徴な sql コマンドに基づいて自動的に図・テーブルを作ることができます。
この記事で、sqlplot を提案したいと思います。
sqlplot というのは
sqlplot は python 言語で作られた道具です。
実験のデータに基づいて内部メモリー sqlite のデータベースを組み合わせて、tex ファイルの中に書いてある特徴なコマンドで図・テーブルを作ります。
いろいろなコマンドがありますが、 python で作られたお掛けで、自分で新しいコマンドを追加しやすいです。
データのフォマット
実験しながら、ただのテキストファイルで測ったデータを置いて、
sqlplot をそのファイルを読ませることができます。
読みながら、RESULT というキーワードから初める行のみ気になります。
RESULTはキーと値から組み合わせるペア列が従います。
その行のシンタックスはこれです。
RESULT key1=value1 key2=value2 ...
つまり、キーと値のペアーは=で繋いで、各のペアーは空文字で区切ってあります。
例えば: ソートアルゴリズム
簡単な例で sqlplot の使い方を説明したいと思います。
そのために、python で実装されたバブルソートと挿入ソートといった素朴のスートアルゴリズムの速さを測りましょう。
バブルソートと挿入ソートと、どちらも $O(n^2)$ 最悪計算時間で動作しますが、
実際的に、どんなデータサイズでどのアルゴリズムの方が速いという質問の解を以下に解析しましょう。
python コード
まず、バブルソートの実装を作りましょう:
def bubble(arr):
for i in range(len(arr)-1):
for j in range(0, len(arr)-i-1):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
ただし arr はソートしたい数字配列です。
次は挿入ソートです:
def selection(arr):
for i in range(len(arr)):
min_index = i
for j in range(i+1, len(arr)):
if arr[j] < arr[min_index]:
min_index = j
arr[i], arr[min_index] = arr[min_index], arr[i]
実験からデータを作るために、以下の関数を定義しましょう。
その関数は上で定義されたソート関数の中に一つかつその関数のネームを入力に対して取ります。
import time
def measure(fn, fnlabel):
start = time.process_time()
sortedliste = fn(liste)
end = time.process_time()
print("RESULT time={} algo={} size={}".format(end - start, fnlabel, len(liste)))
return sortedliste
この print コマンドは sqlplot が読めるフォマットで時間と入力のサイズを出力します。
残ったコードは main 関数です。
ここで、各のサイズ problemsize に対して、1 から problemsize までの数字を liste というリストに保存して、 liste を混ぜて、 measure を各のソートアルゴリズムに対して呼びます。
import random
for problemsize in [10, 100, 1000, 5000]:
liste = list(range(problemsize))
random.seed(a=0)
random.shuffle(liste)
measure(selection, "selection")
measure(bubble, "bubble")
そのプログラムを作動したら、以下のような入力が出るはずです。
RESULT time=9.489000000001413e-06 algo=selection size=10
RESULT time=7.481999999996158e-06 algo=bubble size=10
RESULT time=0.0002442059999999968 algo=selection size=100
RESULT time=0.0002923949999999939 algo=bubble size=100
RESULT time=0.023890221999999996 algo=selection size=1000
RESULT time=0.028448002999999993 algo=bubble size=1000
RESULT time=0.5738962959999999 algo=selection size=5000
RESULT time=0.7924896020000001 algo=bubble size=5000
基本的な tex コード
ここから、集めたデータに基づいて tex の図を作りましょう。
まずは、データを sort.txt というファイルに保存します。
つぎは、この tex ファイルを置きましょう。
%% IMPORT-DATA sort sort.txt
\documentclass{article}
\usepackage{tikz}
\usepackage{pgfplots}
\begin{document}
\begin{tikzpicture}
\begin{axis}
%% MULTIPLOT(algo) SELECT size AS x, time as y, MULTIPLOT FROM sort
%% GROUP BY algo,x
\end{axis}
\end{tikzpicture}
\end{document}
sqlplot のコマンドは %% から初める行で書くべきです。
最小のコマンドは %% IMPORT-DATA sort sort.txt です。
そのコマンドは、 sort.txt の RESULT 行の基づいて、データベーステーブル sort を作ります。
(以上に述べりましたが、詳しくことに、sqlplot はtex ファイルを読みながら、そのデータベースを内部メモリーで組み合わせますが、tex ファイルを読破した後で、その組み合わせたデータベースを消しします。)
次のコマンドは MULTIPLOT です。
MULTIPLOT は複数の測りたいものをプロットします。
ここで、その複数のものは algo というキーがあるデータです。
各の algoのタプルを集めて、タプルのサイズを $x$ 軸とタプルの時間を $y$ 軸に映します。
sqlplot.py を今作った tex ファイルに応用すると、この出力が出て来ます:
%% IMPORT-DATA sort sort.txt
\documentclass{article}
\usepackage{tikz}
\usepackage{pgfplots}
\begin{document}
\begin{tikzpicture}
\begin{axis}
%% MULTIPLOT(algo) SELECT size AS x, time as y, MULTIPLOT FROM sort
%% GROUP BY algo,x
\pgfplotsset{cycle list shift=1} % 1
\addplot coordinates{(10, 7.236000000000742e-06) (100, 0.0002994150000000008) (1000, 0.028540775999999997) (5000, 0.8158583169999999)};
\addlegendentry{bubble};
\pgfplotsset{cycle list shift=1} % 2
\addplot coordinates{(10, 9.677999999999076e-06) (100, 0.0002550619999999969) (1000, 0.025769473999999997) (5000, 0.5913769769999999)};
\addlegendentry{selection};
\end{axis}
\end{tikzpicture}
\end{document}
このtexファイルをコンパイルすると、以下の図を求めることができます。
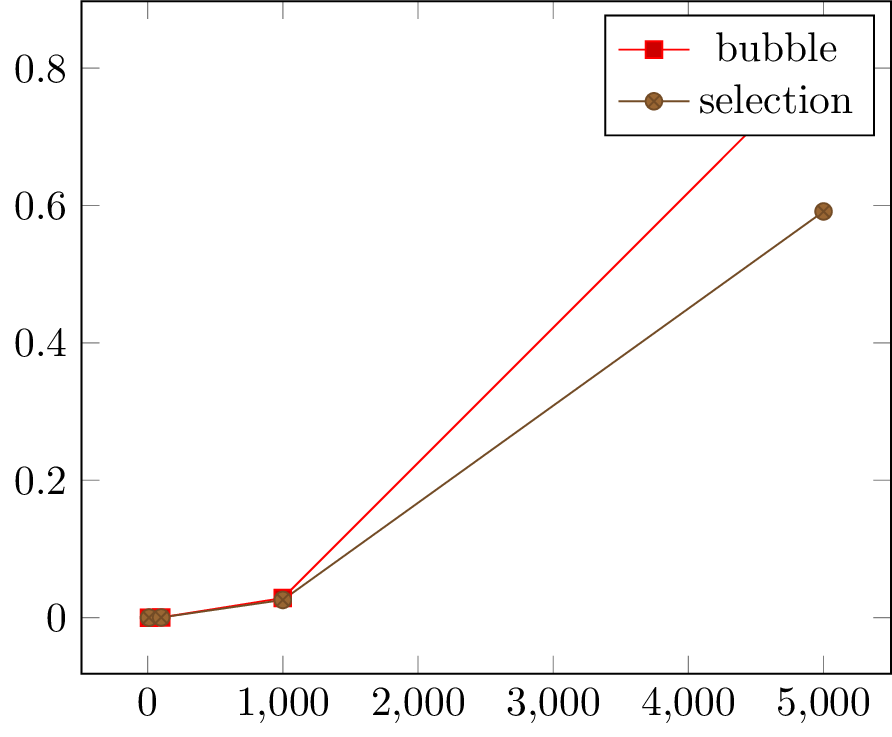
工夫した tex
以上のプロットを見えて、不足なものが見た目に現れます:
- 測った $x$ 値は 10べき乗のスケールで飛ばしましたから、最初の測りは見にくいです。 $x$ 値を対数的なスケールでに変化したいです。
解法を二つ提案します。 - tex の解法は
\begin{axis}[xmode=log]に変化することです。 - sql の解法は
SELECT size AS xをSELECT LOG(2,size) AS xに変換することです。 - 自動的な作ったプロットコマンドを他のファイルに保存できます。
例えば、easysort.texにそのコマンドを保存しましょう:
%% MULTIPLOT(algo) SELECT LOG(2,size) AS x, AVG(time) as y, MULTIPLOT FROM sort
%% GROUP BY algo,x
%% CONFIG file=easysort.tex
\input{easysort.tex}
次の不服なものは、今の実験は時間をただ一回のみ測ったことです。
複数時間の平均数値を sqlplot で計算させることができます。
そのために、 ただ time as y を AVG(time) as y に変化する必要です。
最後に、高々 1000 のサイズに興味があれば、
もっと大きいなサイズについてデータを sort.txt で消さずに、
WHERE size <= 1000 を SQL コマンドに追加しても大丈夫です。
結局、全部の tex ファイルはこの形になりました:
%% IMPORT-DATA sort sort.txt
\documentclass{article}
\usepackage{tikz}
\usepackage{pgfplots}
\begin{document}
\begin{tikzpicture}
\begin{axis}
%% MULTIPLOT(algo) SELECT LOG(2,size) AS x, AVG(LOG(2,time)) as y, MULTIPLOT FROM sort
%% WHERE size <= 1000
%% GROUP BY algo,x
%% CONFIG file=easysort.tex
\input{easysort.tex}
\end{axis}
\end{tikzpicture}
\end{document}
ただし、時間も対数的にプロットされました。
これで、小さいサイズの結果が読みやすくなりました:

作った図によると、
小さいデータなら、バッブルソートは一番速いけど、データが大きくなるとどんどん遅くなります。
これで何かを習うべきなら、
たくさん小さい配列をソートしたいとき、工夫されたソートアルゴリズムより、素朴のバッブルソートのほうが速い可能性があるということです。
故障・debug
sqlplot はおかしく動作するとき、-l DEBUG のパラメタでどの sql コマンドを使ったのを表わすことができます。
リンク
- sqlplot-tools は C++ で書いてある sqlplot の先祖です。
- sqlplot