はじめに
この記事では、OpenAIの埋め込みモデルの基礎を解説し、実際にコードを使って類似度計算や応用例を試してみます。
埋め込み(embedding)とは?
「埋め込み (embedding)」 とは、単語や文章などの特徴をベクトル(数値)に変換する手法で、文脈によってはベクトルそのものを指す場合もあります。
以下の図は、「埋め込み」によって表現される単語同士の意味的な特徴をイメージしたものです。
各単語の 特徴は ベクトルとして表現されます。例えば、 'Queen' と 'King' の意味的な関係性は 'Woman' と 'Man' の関係性に似ていることを 三次元空間で示しています。
コードを表示
%matplotlib widget
import ipympl
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
plt.close()
words = {"King":[3, 3, 5],
"Queen":[4, 3, 5],
"Man":[1.5, 0, 4],
"Woman": [2, 0 ,4]}
colors = ["red", "blue", "green", "purple"]
# 3Dグラフの作成
fig = plt.figure(figsize=(6,6))
ax = fig.add_subplot(111, projection='3d')
for i, (word, coordinate) in enumerate(words.items()):
x, y, z = coordinate
ax.scatter(x, y, z, color=colors[i], marker='o', label=f"Point ({x},{y},{z})")
ax.quiver(0, 0, 0, x, y, z, color=colors[i], label=f"Arrow (0,0,0) to ({x},{y},{z})", arrow_length_ratio=0.1)
ax.text(x, y, z, f"{word}", color=colors[i])
ax.text(x, y, z, f"{word}({x},{y},{z})", color=colors[i])
ax.set_xlabel('X')
ax.set_ylabel('Y')
ax.set_zlabel('Z')
ax.set_xticks([])
ax.set_yticks([])
ax.set_zticks([])
ax.set_xlim([0, 5.])
ax.set_ylim([0, 5.])
ax.set_zlim([0, 5.])
#ax.grid(False)
# グラフの表示
plt.show()
「埋め込み」は通常、高次元空間で表現されますが、ここでは直感的な理解のために低次元空間で考えます。
「埋め込み」によって単語や文章間の特徴を ベクトル(数値) として扱えるので、意味的な関係性(類似度)を コサイン類似度 で 計算することができます。
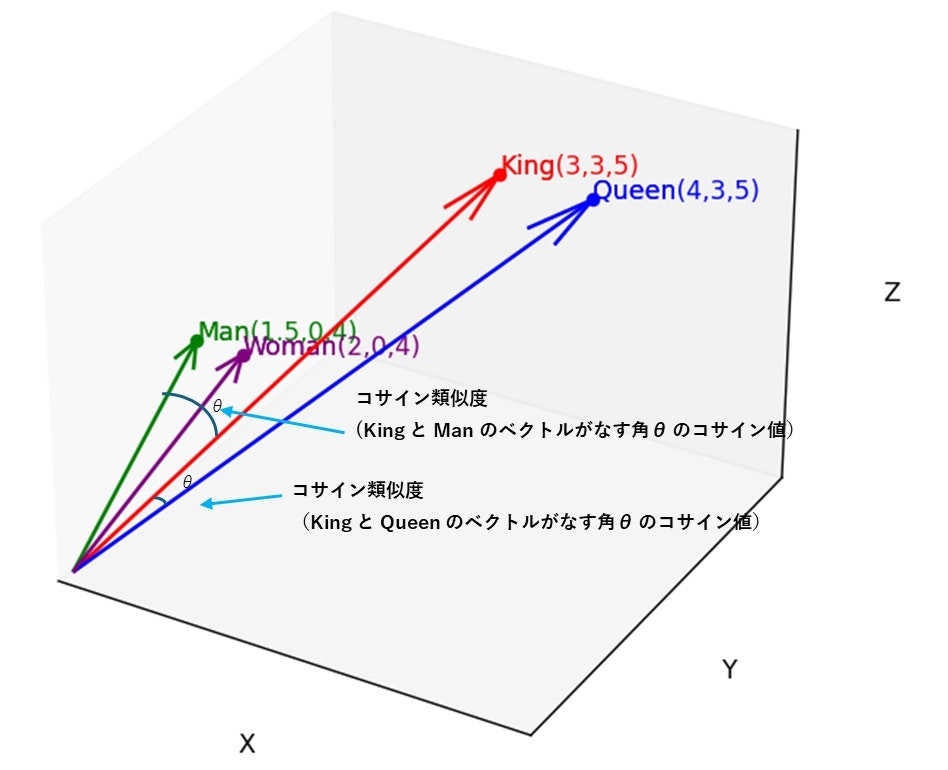
- 'Queen(女王)' と 'King(王)' の類似度は、'Woman(女)' と 'Man(男)' の類似度と同程度になります。
- また、'Queen(女王)' と 'Woman(女)' 、'King(王)' と 'Man(男)' の 関係に着目した場合には、その類似度(位置関係)も同程度であることを示します。
このように、「埋め込みモデル」は、文章や単語の「意味的な関係性」を空間内で学習し、その特徴を高次元ベクトル(数値)として返します。
「埋め込み」(手法)は自然言語処理だけでなく、画像や音声、その他のデータの特徴量でも 利用されます。
埋め込みモデルを使ってみる
ここでは、「似ている」文章と、「似てない」文章について、どれくらいの類似度を示すのかを比較します。
比較は text-embedding-3-small, text-embedding-3-large, text-embedding-ada-002 それぞれのモデルで行います。
import os
import openai
from openai import AzureOpenAI
import numpy as np
# Azure OpenAI を使う場合
client = AzureOpenAI(
api_key = os.getenv("AZURE_OPENAI_API_KEY"),
api_version = "2023-05-15",
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT")
)
# OpenAIを使う場合
# from openai import OpenAI
# client = OpenAI()
# コサイン類似度
def cosine_similarity(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# 埋め込み取得
def get_embedding(text: str, model=embedding_model):
return client.embeddings.create(input = [text], model=model).data[0].embedding
# コサイン類似度を計算する関数
def compare_texts(text1, text2, model):
embedding1 = np.array(get_embedding(text1, model=model))
embedding2 = np.array(get_embedding(text2, model=model))
similarity = cosine_similarity(embedding1, embedding2)
print(f"{model} ({len(embedding1)}次元) 類似度: {similarity:.2f}")
「似ている」文章の類似度
まず 似ている文章間の類似度を確認します。
text1 = "彼は毎朝早くジョギングをする"
text2 = "毎朝、彼は早起きしてランニングをしている"
for model in ["text-embedding-3-small", "text-embedding-3-large", "text-embedding-ada-002"]:
compare_texts(text1, text2, model)
2つの文章の類似度は 予想通り高い値を示します。そしてその値は モデルによって異なる ことが分かります。
text-embedding-3-small (1536次元) 類似度: 0.77
text-embedding-3-large (3072次元) 類似度: 0.86
text-embedding-ada-002 (1536次元) 類似度: 0.94
「似てない」文章の類似度
次に 似ていない文章で確認します。
text1 = "彼は毎朝早くジョギングをする"
text2 = "このレストランのモーニングは本当においしい"
for model in ["text-embedding-3-small", "text-embedding-3-large", "text-embedding-ada-002"]:
compare_texts(text1, text2, model)
text-embedding-3-small, text-embedding-3-large では、低い類似度が示されました。
一方で text-embedding-ada-002 は 「似ていない」場合でも 0.80 で、他のモデルと比較して 高い値を示しました。
text-embedding-3-small (1536次元) 類似度: 0.221722
text-embedding-3-large (3072次元) 類似度: 0.341737
text-embedding-ada-002 (1536次元) 類似度: 0.805570
類似度を判定する際は、どの程度の類似度が出力されるのか、予め確認しておくことが必要です。
埋め込みモデルから取得される ベクトルは 高次元 (1536, 3072 次元)です。次元圧縮すれば可視化はできますが、 無理に 1536次元 を理解しようとする必要はありません。「1536 の軸があって、高次元空間にマッピングされているんだな」 くらいの "なんとなく"の イメージがあればOKだと思います。
類似度の閾値
上の例でみたように、「埋め込み」よる 類似度は、使用モデルによって値が異なる ので、「似ている場合」、「似ていない場合」でどの程度の類似度を示すのかを知っておくことはとても重要です。
結果のサマリ
| model | 似てる場合 | 似てない場合 |
|---|---|---|
text-embedding-3-small |
0.77 | 0.22 |
text-embedding-3-large |
0.87 | 0.34 |
text-embedding-ada-002 |
0.93 | 0.81 |
私は、例えば「似ていない」結果を 予め結果から除外したい場合には、 次のような 閾値を採用しています
-
text-embedding-3-small: 類似度0.4以上で「似ている」判定 -
text-embedding-ada-002: 類似度0.84以上で「似ている」判定
注 : 最終的には実データによる結果や目的によって閾値を調整します:
(厳密に結果を取得したい場合は閾値を高く、曖昧なものも含めたい場合は、閾値を低く)
多言語でもOK
今回使用しているモデルでは、英語と日本語でも 類似度を測ることができます。(おそらく他の言語でも)
text1 = "彼は毎朝早くジョギングをする"
text2 = "He goes jogging early every morning"
for model in ["text-embedding-3-small", "text-embedding-3-large", "text-embedding-ada-002"]:
compare_texts(text1, text2, model)
text-embedding-3-small (1536次元) 類似度: 0.70
text-embedding-3-large (3072次元) 類似度: 0.74
text-embedding-ada-002 (1536次元) 類似度: 0.88
埋め込み(ベクトル)の 足し算
埋め込みの足し算が有効なのかを確認します。
「朝、早い、走る」 というフレーズのベクトル と、それぞれの 単語のベクトルを 足し合わせたベクトル (「朝」+ 「早い」 + 「走る」) の類似度を見てみます。
for model in ["text-embedding-3-small", "text-embedding-3-large", "text-embedding-ada-002"]:
embedding1 = np.array(get_embedding("朝、早い、走る", model=model))
embedding2 = np.array(get_embedding("朝", model=model))
embedding3 = np.array(get_embedding("早い", model=model))
embedding4 = np.array(get_embedding("走る", model=model))
# 「朝」+ 「早い」 + 「走る」
embedding_sum = embedding2 + embedding3 + embedding4
# 「朝、早い、走る」 と 朝」+ 「早い」 + 「走る」 の類似度
similarity = cosine_similarity(embedding1, embedding_sum)
print(f"{model}({len(embedding1)}次元) 類似度: {similarity:.2f}")
高い類似度を示しました。埋め込み(ベクトル)の足し算は 有効であることが確認できました。
text-embedding-3-small(1536次元) 類似度: 0.84
text-embedding-3-large(3072次元) 類似度: 0.82
text-embedding-ada-002(1536次元) 類似度: 0.95
注: 「足し算」「引き算」は 必ずしもすべての文脈で同様の結果が得られるわけでありません。実際に使う場合は、期待する結果が得られるかどうかの確認に時間をが必要となります。
足し算, 引き算 による 新しい特徴の生成
「彼は毎朝早くジョギングをする」 - [彼は毎朝」 + 「週末だけ」 = 「週末だけジョギングをする」
「彼は毎朝早くジョギングをする」 から 「彼は毎朝」 の特徴を取り除いて、 「週末だけ」 を足すと、「週末だけジョギングをする」 になるでしょうか。
for model in ["text-embedding-3-small", "text-embedding-3-large", "text-embedding-ada-002"]:
# 元の文
embedding1 = np.array(get_embedding("彼は毎朝早くジョギングをする", model=model))
# 削除したい文脈
embedding2 = np.array(get_embedding("彼は毎朝", model=model))
# 新しい文脈
embedding3 = np.array(get_embedding("週末だけ", model=model))
# 元の文から 削除したい文脈をマイナスして、新しい文脈を追加
new_embedding = embedding1 - embedding2 + embedding3
# 新しく生成した特徴と 「週末だけジョギングをする」の特徴と比較
target_embedding = np.array(get_embedding("週末だけジョギングをする", model=model))
similarity = cosine_similarity(new_embedding, target_embedding)
print(f"{model}({len(embedding1)}次元) 類似度: {similarity:.2f}")
新しく生成した特徴と 「週末だけジョギングをする」 の特徴と比べると、想定どおり高い類似度が示されました。
text-embedding-3-small (1536次元) 類似度: 0.84
text-embedding-3-large (3072次元) 類似度: 0.80
text-embedding-ada-002 (1536次元) 類似度: 0.94
まとめ
「埋め込み」とは?
本記事では、OpenAIの埋め込みモデルについて、基本的な概念から具体的なコード例までを解説しました。以下にポイントを整理します。
- 「埋め込み」は、単語や文章の特徴を ベクトル(数値)で表現する手法
- ベクトル化により、データ間の類似度を数学的に計算できる
類似度計算
- 文章の意味的な近さを コサイン類似度で 数値化できる
- モデルによって類似度の出力が異なるため、閾値の選択が重要
埋め込み表現の演算
- 埋め込み表現(ベクトル) の 足し算・引き算ができる
- 埋め込み表現(ベクトル) の 計算によって、新しい意味の文脈の生成が可能
埋め込み(ベクトル)の利点
- 多言語対応
- 数値データとして処理できるため、柔軟な操作が可能
- 「学習なし」で、汎用的に使用できる
実践編
以上を踏まえての「実践編」です。よろしければ こちらの記事もご参照ください。