はじめに
私は普段AWSを用いてシステムの開発を行なっているインフラエンジニアです。
最近機械学習に興味をもち始め、Google Cloud Platform(GCP)で機械学習APIとして提供されていて音声データをテキスト化してくれる**「Cloud Speech-to-Text API」**を使ってみたので、記事にしてみようと思います。
このAPIを使ってみようと思った時にWeb上にあまり参考になる記事が見つからなかったので、今回はかなり丁寧に説明していこうと思います。今後このAPIを使ってみたいと思っている方の参考になれば幸いです。
前提
使用するAPI
Cloud Speech-to-Text APIでは以下の3種類のAPIが用意されています。
- 1分未満の音声ファイルの音声認識
- 1分以上の音声ファイルの音声認識
- ストリーミング入力の音声認識
今回は1番簡単な「1分未満の音声ファイルの音声認識」のAPIを使ってみます。
アカウント
Googleアカウントを持っていてGCPに登録ていることを前提とします。
まだGoogleアカウントを持っていない方は、以下のURLより、あらかじめGoogleアカウントを作成しておいてください。
https://www.google.com/intl/ja/account/about/
GoogleアカウントがGCPに紐づいていない方は以下のURLより、Google Cloud管理コンソールにログインしてください。
https://console.cloud.google.com/
GCPに初めて登録する方は「90日間300ドル分無料トライアル」を受けることができます。
環境
- Google Chrome
※環境によって差異が出ないようにPythonの実行もWeb上で行いますが、ローカルにPythonの実行環境がある方はそちらで実行していただいても問題ありません。
準備
早速Cloud Speech-to-Text APIを実行するための準備をしていきます。
Google Cloudの準備
APIを実行するためにGoogle Cloud側で必要な準備をしていきます。
プロジェクトの作成
Google Cloudのコンソールへログインし、左上の現在のプロジェクト名を選択します。
※プロジェクト名は人によって異なります。

右上の「新しいプロジェクト」をクリックします。

プロジェクト名に「speech-to-text-api-test」と入力し、「作成」ボタンを押します。

コンソールのホームに戻り先ほど作成したプロジェクトになっていることを確認します。
なっていない場合は現在のプロジェクト名をクリックし、先ほど作成したプロジェクトを選択します。
Cloud Speech-to-Text APIを有効にする
コンソールの「APIとサービス」→「ライブラリ」を選択します。

検索窓から「Cloud Speech-to-Text API」を検索し、選択します。
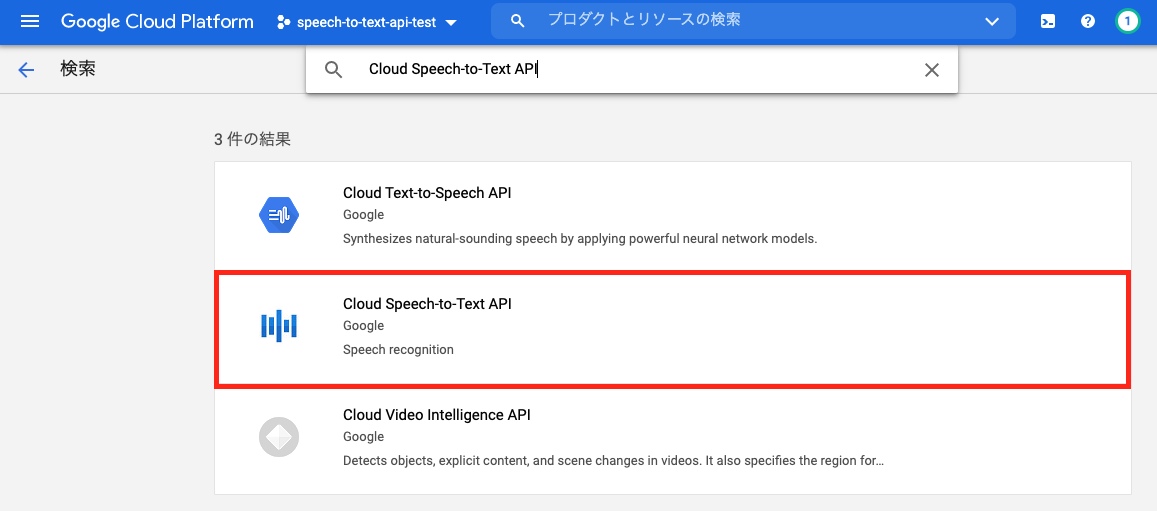
「有効にする」ボタンを押します。

サービスアカウントを作成する
Google CloudのAPIを利用するためには認証が必要なので、認証のためのサービスアカウントを作成します。
コンソールの「APIとサービス」→「認証情報」を選択します。

「+認証情報を作成」→「サービスアカウント」を選択します。
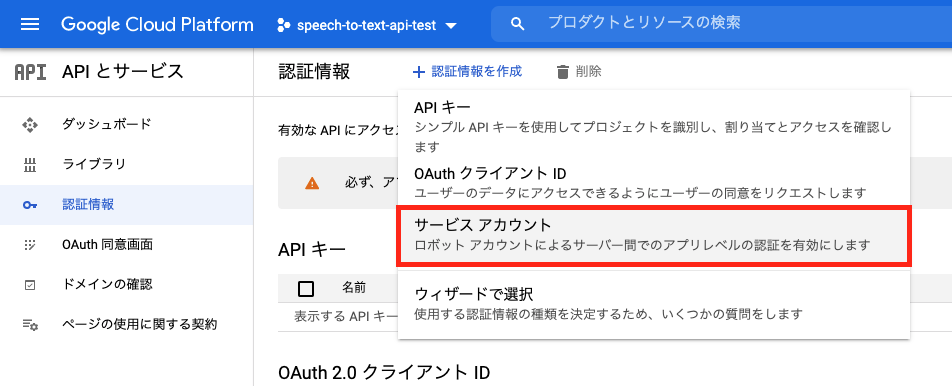
「サービスアカウント名」に「speech-to-text-api-test-account」と入力し、「完了」ボタンを押します。

認証情報の作成が完了すると「サービスアカウント」の下に先ほど作成した「speech-to-text-api-test-account」が追加されます。
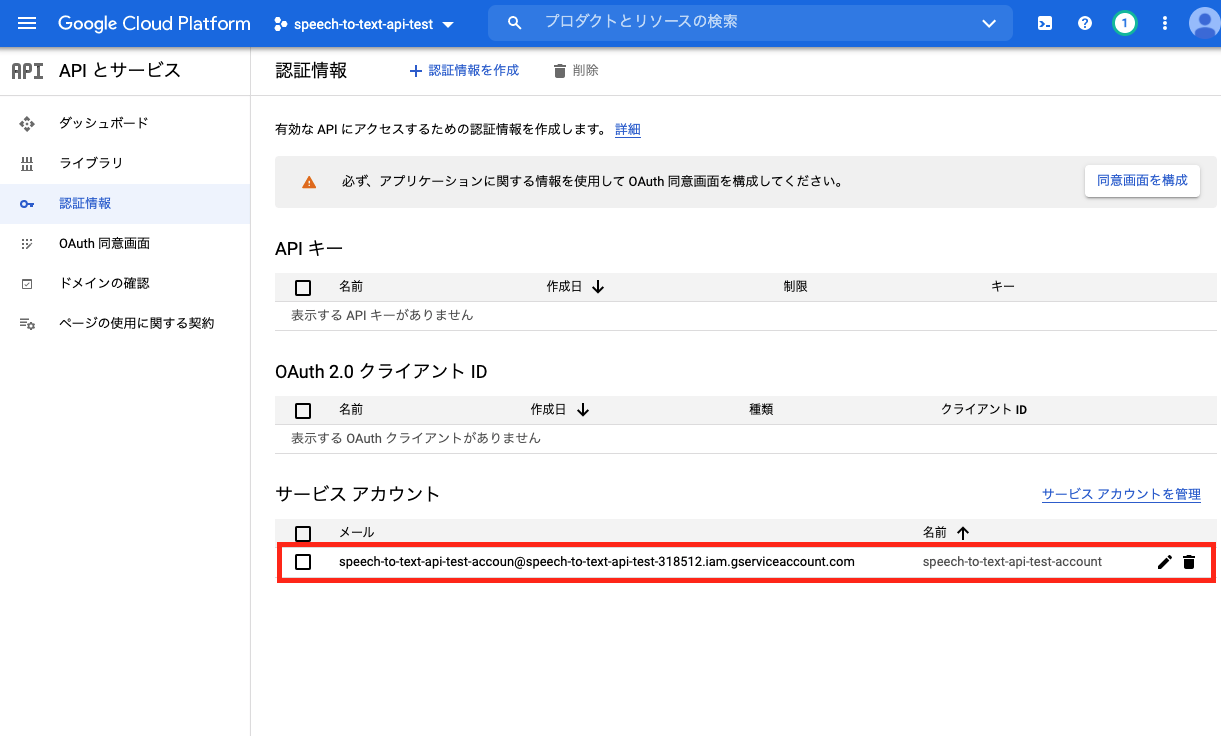
アカウントキーを作成する
作成したサービスアカウントを選択します。
画面下の方の「キー」タブの中から「鍵を追加」→「新しい鍵を作成」を選択します。
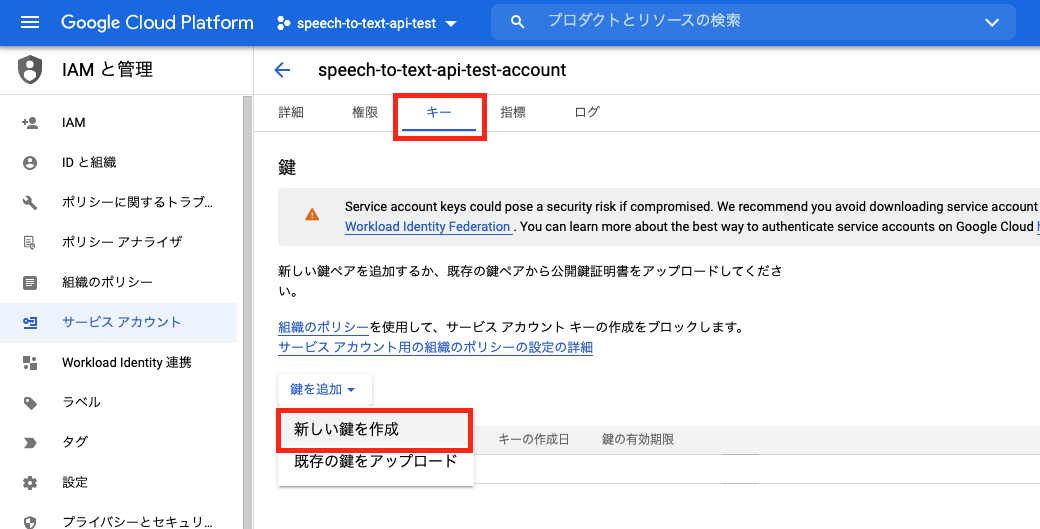
キーのタイプを聞かれるので「JSON」を選択し、「作成」を押します。

作成したJSONは「credentials.json」というをダウンロードし、保存しておきます。
Pythonの実行環境の準備
Pythonの実行環境の準備に入りますが、今回は多くの方にこの手順を再現していただけるように、Web上でアプリケーションを実行可能な「Google Colaboratory」というサービスを用います。
※Google Colaboratoryでは「90分以上操作がない場合」または「実行環境の作成から12時間以上たった場合」に実行環境がリセットされるので注意してください。
Googleドライブの準備
Google Colaboratoryにファイルを連携するためにはGoogleドライブかGoogle Strage(Google Cloudのストレージサービス)にファイルを配置する必要があります。
今回はAPIを使用することが目的なので、より簡単なGoogle Driveを利用する方法を使います。
Google Driveに「speech-to-text-api-test」というフォルダを作り、先ほどダウンロードしたcredentials.jsonをアップロードします。

Google Colaboratoryの準備
以下のページを開き、Googleアカウントでログインしてください。
Google ChromeにGoogleアカウントでログインされている方は自動的にログインされます。
https://colab.research.google.com/
ログインすると下のような画面が表示されるので、「ノートブックを新規作成」を選択します。

新規ノートブックが作成され、Pythonの実行が可能な状態になりました。

PythonのプログラムからCloud Speech-to-Text APIにアクセスするためには「google-cloud-speech」というライブラリが必要です。
以下のコマンドでライブラリをインストールします。
! pip install --upgrade google-cloud-speech
コマンドを入力し「実行」ボタンを押します。

以下のような警告が出るので「RESTART RUNTIME」を押して実行環境を再起動します。

「+コード」を押し、新しいコードを入力できるようにします。

次にGoogle Colaboratoryと先ほどファイルをアップロードしたGoogleドライブを連携する作業をします。
以下のように入力し、「実行」ボタンを押します。
from google.colab import drive
drive.mount{'/content')
表示されたURLにアクセスするとGoogleアカウントの認証を求められます。
自分のアカウントを選択し「ログイン」ボタンを押すとGoogle Colaboratoryを認証するためのコードが発行されます。
コードをコピーし、「Enter your authorization code:」の下の枠に貼り付けEnterキーを押します。

以上の操作でGoogle ColaboratoryとGoogleドライブの連携に成功しました。
次に先ほどアップロードしたアカウントキーを環境変数に設定します。
「+コード」を押し、以下のように入力し「実行」ボタンを押します。
import os
os.environ['GOOGLE_APPLICATION_CREADENTIALS'] = '/content/drive/MyDrive/speech-to-text-api-test/credentials.json'

これでPython実行環境の準備は完了です。
音声ファイルの準備
Windowsの方
以下のサイトからAudacityというソフトをダウンロードしていただき、
以下のサイトを参考にwavファイルを作成してください。
Macの方
Cloud Speech-to-Text APIはMac標準の音声ファイル形式である「m4a」に対応していないので、
「ボイスレメモ」アプリで録音した音声ファイルを、以下のサイトを参考にファイル形式の変換を行ってください。
音声ファイルのアップロード
作成した音声ファイルをGoogleドライブに「voicememo.wav」というファイル名でアップロードします。

APIの実行
「+コード」を押し、以下のように入力します。
from google.cloud import speech
import io
# 音声ファイルの読み込み
with io.open("/content/drive/MyDrive/speech-to-text-api-test/voicememo.wav", "rb") as f:
content = f.read()
# APIパラメータの作成
audio = speech.RecognitionAudio(content = content)
config = speech.RecognitionConfig(
encoding = speech.RecognitionConfig.AudioEncoding.LINEAR16,
sample_rate_hertz = 48000,
language_code = "ja-JP")
# APIの呼び出し
client = speech.SpeechClient()
response = client.recognize(config = config, audio = audio)
# 結果の表示
for result in response.results:
print(result.alternatives[0].transcript)
実行結果
以下のように実行結果が返ってきました。
日本語と英語が混ざった文章でしたが、正確に認識されました。

感想
普段GCPに慣れていないので少し苦労しましたが、実際に使ってみると音声認識の精度も高く、とても便利なAPIでした。
これから他のGCPサービスにも触れていこうと思いました。