概要
Amazon Athena を利用する機会があったので、入門した際に学んだことを記載したいと思います。
また、AthenaはTerraformで構築しました。サンプルコードもあります。
試したことは下記の通りです。
- TerraformでAthenaを構築
- JSONのデータにSQLを実行できる設定
- Partition Projectionの設定
- クエリの実行
- Nested JSONにクエリを実行する
- パーティションの指定
想定読者
- Amazon Athenaに入門したい人
- Amazon AthenaをTerraformで構築したい人
ソースコード
Terraformで構築したサンプルコードです。
https://github.com/kobayashi-m42/terraform-aws-athena-sample
Amazon Athenaとは
AthenaはS3にあるデータ(およびさまざまなデータソース)に対して標準SQLを利用して簡単に分析可能とするインタラクティブなクエリサービスです。
AthenaはS3のデータに直接SQLを実行できるサーバレスな分析サービスであるため、インフラ管理が不要であり簡単に導入することができます。
簡単にログの分析などユースケースで利用できるかと思います。
Athenaの構築
S3バケットに保存されたJSON形式のログに対して、Athenaを利用してSQLを実行できる環境を構築します。
ログのサンプルは下記の通りです。
{"level":"info","msg":"message0","name":{"first":"first0","last":"last0"},"time":"2021-01-10T18:08:40+09:00"}
{"level":"info","msg":"message1","name":{"first":"first1","last":"last1"},"time":"2021-01-10T18:08:41+09:00"}
{"level":"info","msg":"message2","name":{"first":"first2","last":"last2"},"time":"2021-01-10T18:08:42+09:00"}
{"level":"info","msg":"message3","name":{"first":"first3","last":"last3"},"time":"2021-01-10T18:08:43+09:00"}
{"level":"info","msg":"message4","name":{"first":"first4","last":"last4"},"time":"2021-01-10T18:08:44+09:00"}
{"level":"info","msg":"message5","name":{"first":"first5","last":"last5"},"time":"2021-01-10T18:08:45+09:00"}
{"level":"info","msg":"message6","name":{"first":"first6","last":"last6"},"time":"2021-01-10T18:08:46+09:00"}
{"level":"info","msg":"message7","name":{"first":"first7","last":"last7"},"time":"2021-01-10T18:08:47+09:00"}
{"level":"info","msg":"message8","name":{"first":"first8","last":"last8"},"time":"2021-01-10T18:08:48+09:00"}
{"level":"info","msg":"message9","name":{"first":"first9","last":"last9"},"time":"2021-01-10T18:08:49+09:00"}
今回は、Partition Projectionも試したいので、下記の構成でS3バケットに保存します。
それぞれ同じファイルを置いています。日付を指定してSQLを実行できるようにすることを想定しています。
s3://<bucket_name>/logs/2020/01/10/sample-log
s3://<bucket_name>/logs/2020/01/11/sample-log
Partition Projection については公式のドキュメントや下記の記事がわかりやすかったので参考にしてください。
[新機能]Amazon Athena ルールベースでパーティションプルーニングを自動化する Partition Projection の徹底解説 | Developers.IO
S3 Bucket
事前にS3バケットを2つ作成します。
- ログを保存するためのS3バケット
- Athenaの実行結果を保存するS3バケット
Athena Workgroup
resource "aws_athena_workgroup" "this" {
name = var.athena_workgroup_name
configuration {
enforce_workgroup_configuration = true
publish_cloudwatch_metrics_enabled = false
result_configuration {
output_location = "s3://${var.athena_result_bucket_name}/athena-result/"
}
}
}
variable "athena_result_bucket_name" {
description = "Athenaの結果を出力するためのS3バケット名"
}
AWSコンソールから確認すると、Workgroupが作成されています。
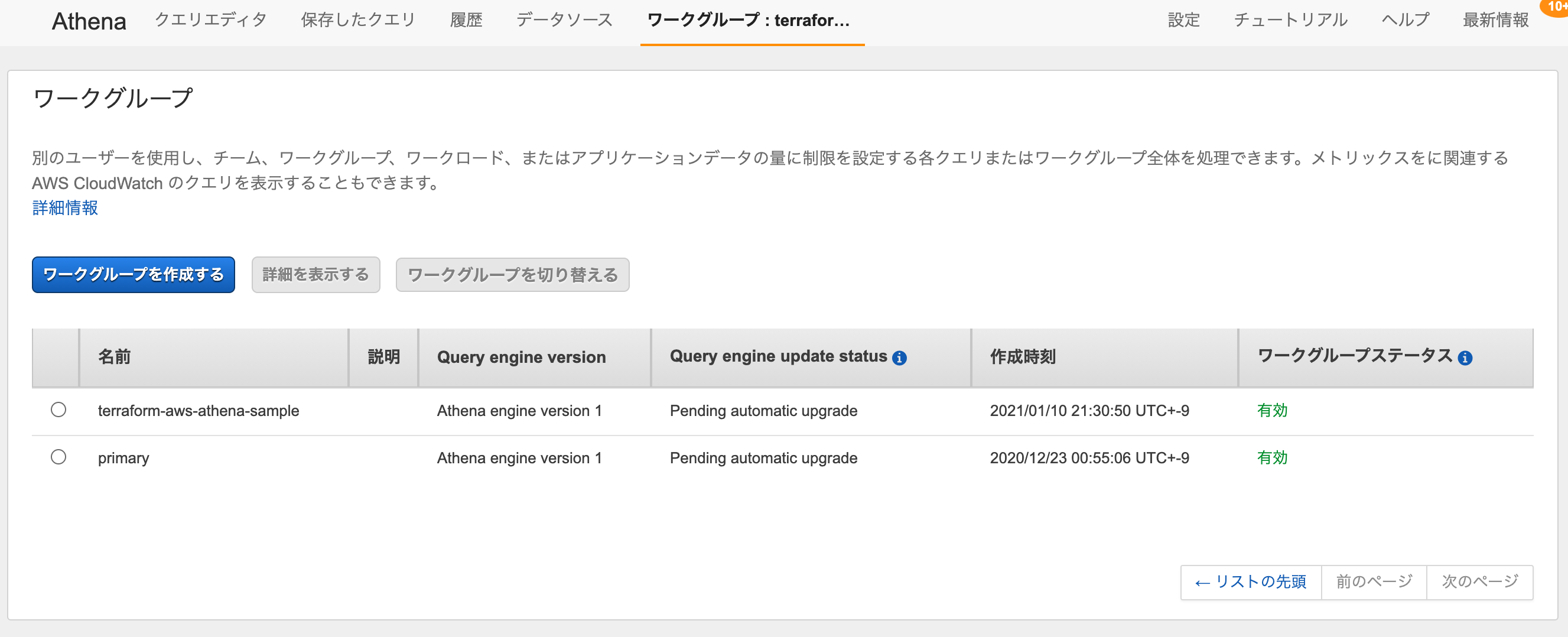
Workgroupを利用するためのIAMポリシーを設定することで、特定のWorkgroupの実行権限のみIAMユーザに付与することも可能です。詳細は、下記のドキュメントを参照してください。
Workgroup Example Policies - Amazon Athena
Athena Database と Athena Named Query
Athennaのデータベースとテーブルを構築します。
Athena Database
resource "aws_athena_database" "this" {
name = var.athena_database_name
bucket = var.log_bucket_name
}
variable "log_bucket_name" {
description = "ログが保存されているS3バケット名"
}
variable "athena_database_name" {
description = "任意のデータベース名"
}
Athena Named Query
// SQLは別のファイルで定義
data "template_file" "create_table_sql" {
template = file("${path.module}/sql/create-table.sql.tpl")
vars = {
athena_database_name = var.athena_database_name
athena_table_name = var.athena_table_name
log_bucket_name = var.log_bucket_name
}
}
resource "aws_athena_named_query" "create_table" {
name = "Create table"
description = "テーブルを作成"
workgroup = var.athena_workgroup_name
database = var.athena_database_name
query = data.template_file.create_table_sql.rendered
}
variable "athena_workgroup_name" {
description = "Athena Workgroup名"
}
variable "athena_database_name" {
description = "任意のデータベース名"
}
variable "athena_table_name" {
description = "任意のテーブル名"
}
CREATE EXTERNAL TABLE IF NOT EXISTS ${athena_database_name}.${athena_table_name} (
`level` string,
`msg` string,
`name` struct<`first`:string, `last`:string>,
`time` string
)
PARTITIONED BY (`orderdate` string)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1'
)
LOCATION 's3://${log_bucket_name}/logs/'
TBLPROPERTIES (
'projection.enabled' = 'true',
'projection.orderdate.type' = 'date',
'projection.orderdate.range' = '2020/01/10,NOW',
'projection.orderdate.format' = 'yyyy/MM/dd',
'projection.orderdate.interval' = '1',
'projection.orderdate.interval.unit' = 'DAYS',
'storage.location.template' = 's3://${log_bucket_name}/logs/$${orderdate}'
);
- Nested JSON形式のログを想定しているため、
name struct<first:string, last:string>のように定義。 -
TBLPROPERTIESでPartition Projectionの設定を追加- S3には
s3://<bucket_name>/logs/yyyy/MM/ddの形式でログが保存される - 年月日(
yyyy/MM/dd)でパーティションを設定する
- S3には
AWSコンソールから確認すると、クエリが作成されています。
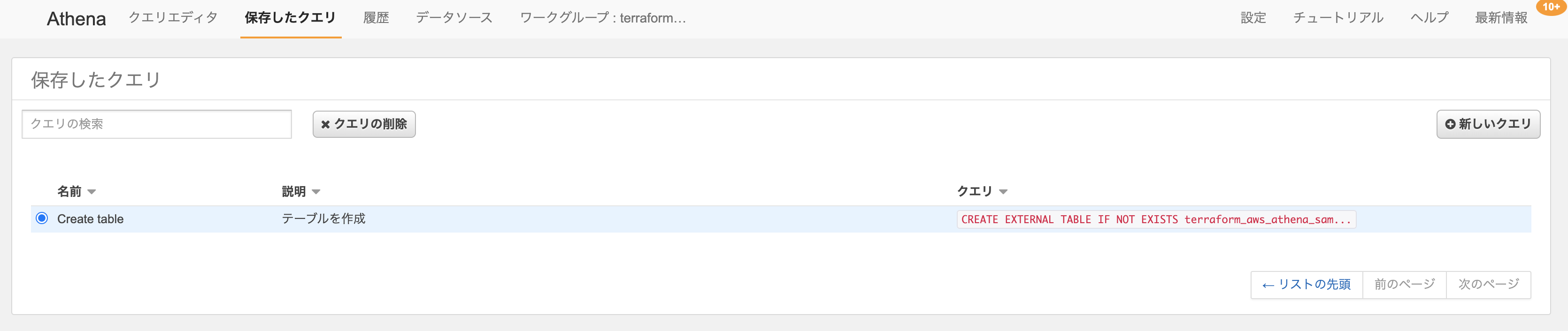
クエリを選択し実行すると、テーブルが作成されます。
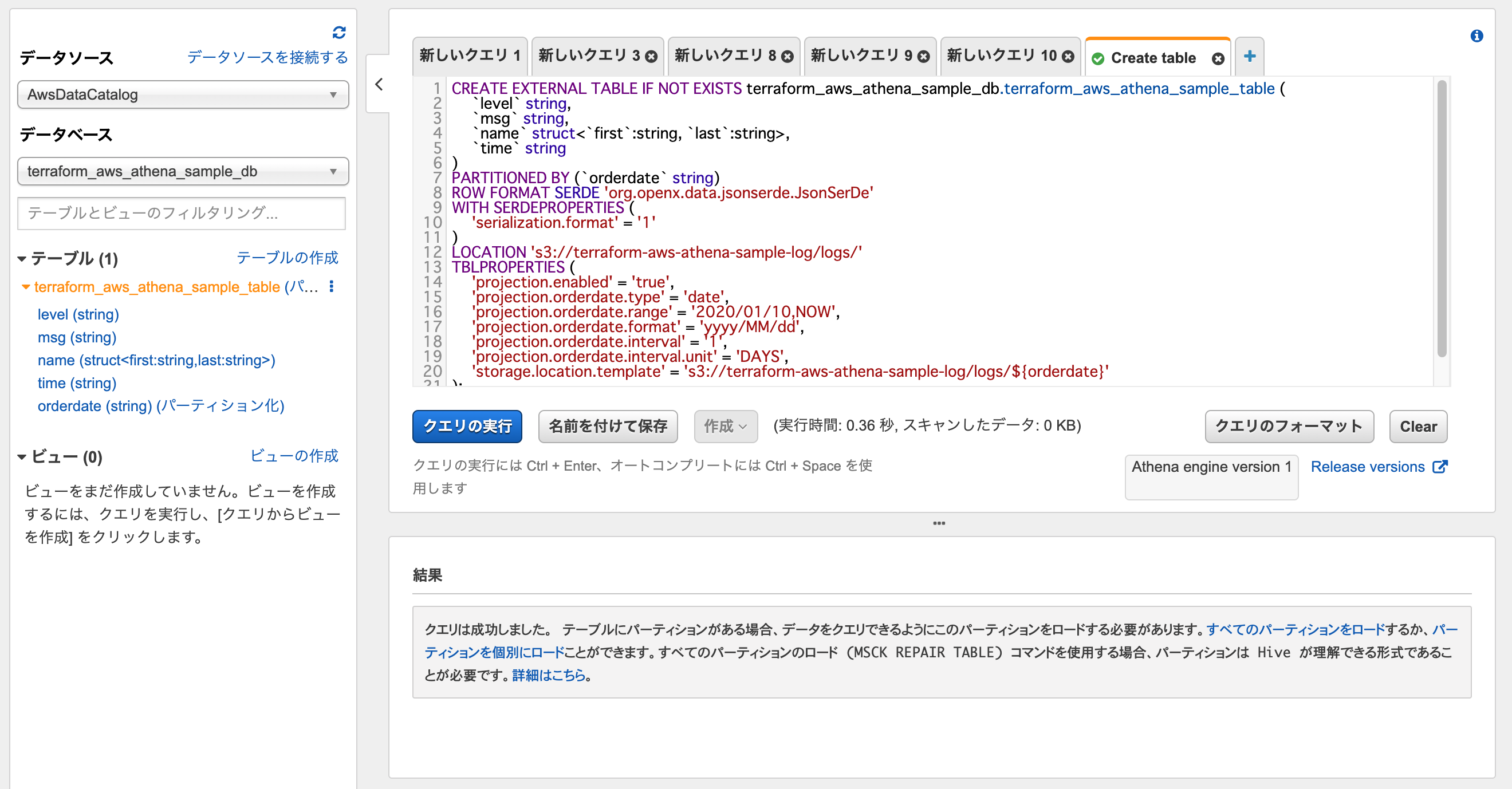
テーブルプレビューを実行すると、クエリの結果が表示されます。
SELECT * FROM "terraform_aws_athena_sample_db"."terraform_aws_athena_sample_table" limit 10;
実行結果

ここで、AWSコンソールからGlueを見てみると、Athenaで構築されたDatabaseとテーブルを確認することができます。
データベース

テーブル

当初、AthenaとGlueの関係性がわからなかったのですが、Black Beltの資料にこのように記載がありました。
Athenaではクエリのために、テーブル定義が必要。デフォルトでは、AWS Glue Data Catalog上のテーブル定義を使用。
AWS Glue Data Catalogは、Apache Hive MetastoreというOSSと互換性のある、メタデータを管理するためのリポジトリ。
AWS Glue Data Catalogにテーブル定義を作成する方法は、次の3つ
・ Athena DDL
・ AWS Glue Catalog API
・ AWS Glue Crawler
参考:20200617 AWS Black Belt Online Seminar Amazon Athena
上記は「Athena DDL」を利用して、テーブル定義を利用した例でした。
ここからは、「AWS Glue Catalog API」の方法(TerraformのGlueのリソースを利用して)でデータベースとテーブルを作成してみます。
Glue Catalog Database と Glue Catalog Table
Glue Catalog Database
resource "aws_glue_catalog_database" "this" {
name = var.glue_catalog_database_name
}
variable "glue_catalog_database_name" {
description = "任意のデータベース名"
}
Glue Catalog Table
resource "aws_glue_catalog_database" "this" {
name = var.glue_catalog_database_name
}
resource "aws_glue_catalog_table" "this" {
database_name = aws_glue_catalog_database.this.name
name = var.glue_catalog_table_name
table_type = "EXTERNAL_TABLE"
parameters = {
"projection.enabled" = "true"
"projection.orderdate.format" = "yyyy/MM/dd"
"projection.orderdate.type" = "date"
"projection.orderdate.interval" = "1"
"projection.orderdate.interval.unit" = "DAYS"
"projection.orderdate.range" = "${var.date_range_start},NOW"
"storage.location.template" = "s3://${var.log_bucket_name}/logs/$${orderdate}"
}
storage_descriptor {
location = "s3://${var.log_bucket_name}/logs"
input_format = "org.apache.hadoop.mapred.TextInputFormat"
output_format = "org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat"
ser_de_info {
serialization_library = "org.openx.data.jsonserde.JsonSerDe"
parameters = {
"serialization.format" = "1"
}
}
columns {
name = "level"
type = "string"
}
columns {
name = "msg"
type = "string"
}
columns {
name = "name"
type = "struct<first:string,last:string>"
}
columns {
name = "time"
type = "string"
}
}
partition_keys {
name = "orderdate"
type = "string"
}
}
variable "glue_catalog_database_name" {
description = "任意のデータベース名"
}
variable "glue_catalog_table_name" {
description = "任意のテーブル名"
}
variable "date_range_start" {}
Terraformを実行すると、Athenaのデータベースとテーブルが作成されていることを確認できました。
AWSコンソールでテーブルのプレビューを実行してみると、Athenaリソースで定義したもの同様の結果が表示されています。
SELECT * FROM "terraform_aws_athena_sample_glue_db"."terraform_aws_athena_sample_glue_teble" limit 10;
実行結果
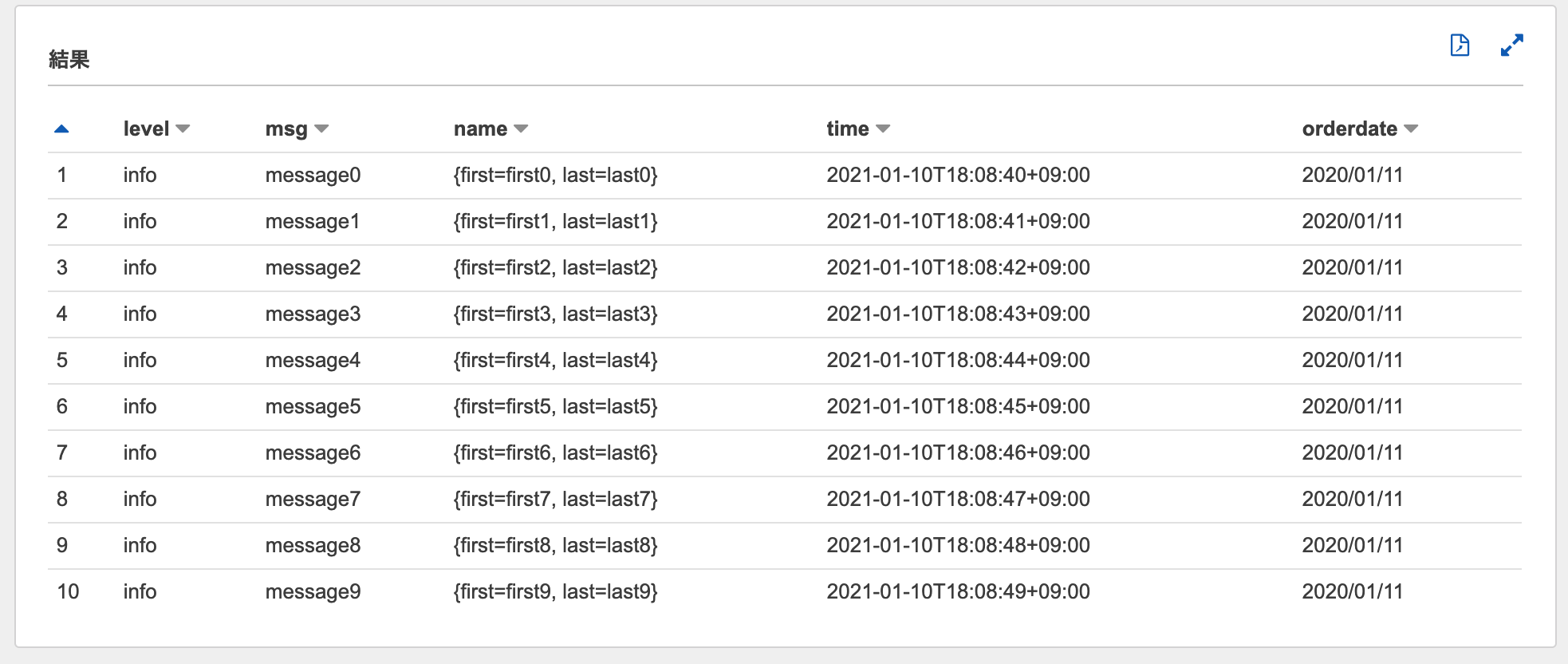
SQLの実行方法
Nested-JSON の例
ログの一部がNested-JSONになっています。要素名nameの下に、firstとlastが入れ子になっています。
{"level":"info","msg":"message0","name":{"first":"first0","last":"last0"},"time":"2021-01-10T18:08:40+09:00"}
name."last"のようにカラムを指定することができます。またfirstやlastのような予約語はダブルクォートで囲む必要があります。
SELECT name."first", name."last" FROM "terraform_aws_athena_sample_db"."terraform_aws_athena_sample_table" limit 1;
"first","last"
"first0","last0"
絞り込むことも可能です。
SELECT *
FROM "terraform_aws_athena_sample_db"."terraform_aws_athena_sample_table"
WHERE name."first" = 'first0' limit 1;
"level","msg","name","time","orderdate"
"info","message0","{first=first0, last=last0}","2021-01-10T18:08:40+09:00","2020/01/11"
パーティションの指定
パーティションを設定しているので、年月日で対象を絞り込むことが可能です。
SELECT *
FROM "terraform_aws_athena_sample_db"."terraform_aws_athena_sample_table"
WHERE msg = 'message0' and orderdate = '2020/01/11';
orderdateを指定しなかった場合、結果は2件になります。
"info","message0","{first=first0, last=last0}","2021-01-10T18:08:40+09:00","2020/01/11"
参考
公式ドキュメント: What is Amazon Athena? - Amazon Athena
[新機能]Amazon Athena ルールベースでパーティションプルーニングを自動化する Partition Projection の徹底解説 | Developers.IO
Amazon Athena Nested-JSONのSESログファイルを検索する | Developers.IO