形態素解析ライブラリ Mecabを使って、仕事をする機会があったので、そのメモ書き
サンプルコードはこの人たちの記事の方が役立つので、コピペして使用してください
https://qiita.com/Takayoshi_Makabe/items/18cefa4b4572d12b5aa9
https://qiita.com/SZZZUJg97M/items/dbdc784b92bde56cde3b
この記事では、理論的な背景と実際にどんなケースで使ったかについて書いていきます。
そもそもMeCabとは何か?から行きます。
ざっくりいうと「分かち書き」を実行するライブラリです。
分かち書きとは???
英語だと、単語と単語の間にはスペースが入っていて、文章を単語群に分解することは非常に簡単ですが、日本語は全部がつながっているので、結構大変です。どこで区切るか??例えば
I like a cat
最初から分割されてる!
私は猫が好きです
どこで分割すればいいのか、少なくともコンピュータにはわからない!
日本人であれば、 私は / 猫が / 好きです で分割するのは自明なのですが、コンピュータにはできないのです。それを実現するものがMecab
あ、Mecab以外にも色々ライブラリはありますが、一番使われているのがMeCabってだけです。
なんで単語を分割することが必要なのかという根本的な問いですが、答えは
「まだコンピュータは文章の意味を理解できないから」です
ディープラーニングだなんだと言っても、所詮は統計的な処理の上で動いているわけで、本質的に文章の意味というものを理解しているわけではないのです。そもそも意味とか自我とか意識とかは基本的な原理原則すら解明されてない状態
と、話がそれましたが、要するに文章を統計的な処理対象にするためには、「分かち書き」を行い、単語ベースで処理を行えるようにする必要があります。今回の場合は
文章を単語にバラして、マッチする単語の頻度を計る=文章の類似度を計る
ということです。
OK! 単語ベースにする理由はわかった。じゃあ具体的にどうやって計るのか
ここでちょっとだけ数学が出てきます。ベクトル(行列)です。
私は/猫が/好きです は3つの単語からなっているので、要素が3のベクトルと仮定してみましょう。
(私は, 猫が, 好き)
一方で私は犬が好きの場合は
(私は,犬が,好き)となります。
2つベクトルの類似度を計る方法としてコサイン類似度という手法があります。
これは2つのベクトルがどのくらい、同じ方向を向いているかを計る手法です。これは高校の時に習っていて2つのベクトルの間のコサインの値を出すだけです。
同じ方向を向いていれば1に近く、違う方向であれば0をとります。以下の図を参照
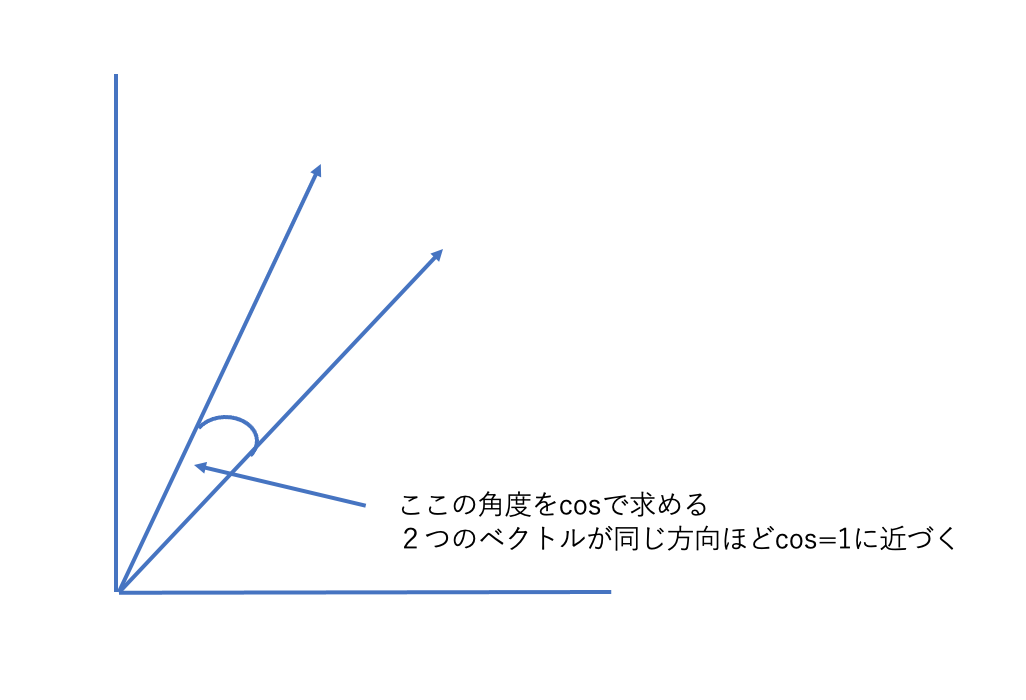
でも、ここで疑問。行列なら中に入るのは数字だけど今考えているのは単語じゃないか!
はい、そうです。なので単語は存在したら1としてしまいます。存在しなければ0
0、1だけになると犬猫の区別がつかないので、犬猫は別の要素として扱います。
そうすると2つの文章は要素が4のベクトルとして表示できます。
\begin{pmatrix}
私は & 犬が & & 好き\\
\end{pmatrix}
\begin{pmatrix}
私は & & 猫が & 好き
\end{pmatrix}
0、1で表すと
\begin{pmatrix}
1 & 1 & 0 & 1\\
\end{pmatrix}
\begin{pmatrix}
1 & 0 & 1 & 1
\end{pmatrix}
あとは計算式に値を放り込むだけです。この結果が1に近いほどベクトルが同じ方向を向いている=文章の類似度が高いという結果になります
\frac{{a_1}{b_1}+\cdots+{a_n}{b_n}}{{\sqrt{a_1^2 + \cdots + a_n^2}}{\sqrt{b_1^2 + \cdots +b_n^2}}}
で、この手法をすると何かいいことがあるの?という話ですが、例えばこんな感じで使用できます。
ユーザ投稿系サイト
ユーザの書き込んだ内容を元に、同じ内容と思われるものを同一カテゴリにまとめる
商品比較サイト
いろいろなECサイトから集めた商品名称のうち、同じ商品と思われるものを同一商品と認識
マッチングアプリ
2つのプロフィール文章のマッチ率から、より高いマッチ率の高い人をレコメンド
ただ、コサイン類似度が万能というわけではなく、単語数に沿って要素(行列の次元)が増えていくので、長い文章の比較をする場合は計算量が膨大になります。また単語数が増えるほどマッチ率が落ちる「次元の呪い」なるものがあるようですが、ハマったことがないので詳しくは知らないです。
また確率的に類似度が高いというだけなので、100%のマッチを求める場合は、人が最終チェックを行ってOK/NGを出すような管理画面が必要になります。
実装する前に、要件とこの辺りの前提条件をよく吟味するといいと思います。