排序在自然语言处理中是一个基本问题。我记得谷歌T5的论文里就有对比过填空(BERT)和顺序修复,两者训练通用模型的效果,当时我好像看到顺序修复效果是比填空好的,所以才一直忘不掉。
如今重新提起排序是因为这是老师给我提供的一个候选研究方向。
最近谷歌的openAI CLIP给人极大的冲击。我认为模型效果如此之好的根本原因是loss函数真正贴合了人类想要模型做的事情——理解图片&自然语言。最为Loss函数受苦的机器学习领域是强化学习——恰恰是openAI专攻的领域。我甚至怀疑openAI是不是用某种强化学习设置来探索了最优的loss函数,然后把这个结果给拿出来发表,而把本质的东西(发现这个loss定义的方法)藏了起来。
总而言之。我们作NLP的,仍然在为探索NLU(自然语言理解)最优的loss苦苦挣扎。而排序Loss,正是其中的一员。
排序Loss(以同一个句子中的单词排序为例)得以生效,是基于这样一个常识: 唯有理解了句意,我们才能够将句中词语正确排序。想想英语考试中的短语排序吧,那就是最好的例子。
单词排序可以用于训练句子embedding,句子排序可以用于训练段落embedding。
Deep Attentive Sentence Ordering Network
今天看了这篇2018年的ACL论文。比起老师几年前的论文当然是好上很多,但是老实说,没有什么新意。
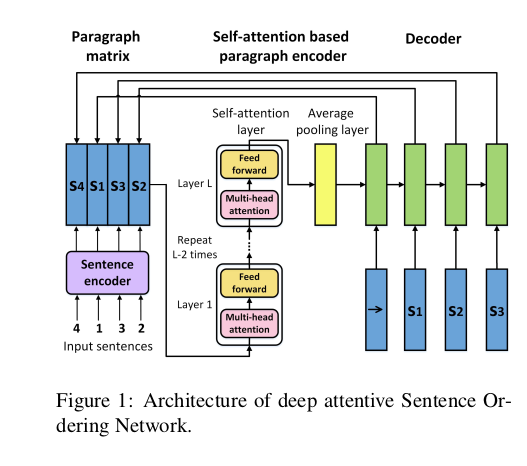
观察模型结构,我们可以看到他比起prtNet的唯一不同是,中间用了多层selfattention。我们知道自注意层是自带multi-head的,这可以成为性能差异的要因之一。然后,他们选择排除一切position embedding之类的机制来抹消错误位置对模型产生的恶性影响。
这就是全部了。虽然模型结构比起老师之前论文里的SVM要好上很多,研究主题毫无新意,你知道我这样一个只读过不超过50篇论文的人,接手这样一个研究时,首先想到的就是这样的改进。
接下来的研究方向
虽然我作为云玩家可以指点江山,可是一轮到做研究就菜的像条狗,至今已经失败了三个研究:
- prtNet用于主题分割,就是segbot的那个想法,虽然segbot的手动记忆方案显得更加tricky
- 唬人的沙漏模型用于主题分割
- 日语段落分割先行研究的追实验
接下来我的想法是做日语的句子&段落排序。如果你问我为什么选择日语,原因是我不敢再眼高手低。我至今一篇论文都还没有发过。虽然我有上ACL的壮志,却已经遭到了屡屡挫折。
至于方法,我是打算先在训练集上训练个句子级别的VAE——多头自注意作为encoder,LSTM作为decoder,每次输出一个单词——用来做句子embedding,顺便可以开拓一下日语VAE的领域,然后将decoder去掉,接上MLP作为分类器作为段落划分,又或者接上LSTM作为顺序器用于排序。Decoder可以多种多样,但是VAE作为encoder是矢志不移,因为我已经被句子同构深深吸引了,而这在日语领域似乎还是一片处女地。
而至于VAE怎么训练就是另一个问题了,我可以用类似BERT的填空,也可以用排序,都是可以的。