こんにちは。ABEJAでPlatformのCSを担当している @koba_taka です。
本ブログは ABEJA Advent Calendar 2019 の 16 日目です。
今回は、機械学習のプロセスの中で一番頭を悩ませる、「作成したモデルを継続的に改善するパイプラインを自動化する」プロセスを紹介したいと思います。このプロセスについては、先日、開催されたAWS re:Invent2019のBuilders Sessionでも紹介されていたので、詳細に紹介したいと思います。
機械学習のプロセスについて
機械学習のパイプライン(プロセス)について少し紹介します。
大体の流れとしては図のようにデータ取得から学習、推論、再学習といった流れをプロセスとします。 (ホントは前処理やデータセット作成など細かい作業はありますが、、)

ちなみにABEJA Platformを利用することで、そのプロセスも柔軟に実装できます。(宣伝
各プロセスには決まった作業が存在し、ABEJA PlatformでもSageMakerでもコマンド実行など、オペレーションが基本的には発生します。
今回、この一連のプロセスをAWSを利用して自動化するアプローチをご紹介したいと思います。
自動化におけるプロセスの紹介
今回は主に2つのタスクを1つのプロセスとして紹介します。大きな目的は、**「モデルの性能評価をして改善し続ける」**といったアプローチのため、「モデルのトレーニング」・「モデルの性能評価」の2つのフローを利用して、実現しています。
上の図でいう「⑥学習」から「⑩再学習」の部分です。
自動化に利用するサービス
今回のプロセス自動化に利用するために利用するAWSサービスはStep Functionsを利用します。
Step Functionsの説明については、こちらを参照していただくとわかりやすいのですが、主にワークフローをプログラマブルに実装できるサービスとなります。
また、Step Functionsでは、各フローをStepとしてLambdaで操作できるため、色々なAPIに対してタスクをフロー化することが可能です。
その他の利用サービスとしてSageMakerはもちろんのこと、「入出力データを格納するS3」と「モデルのステートを管理するためDynamoDB」を利用します。
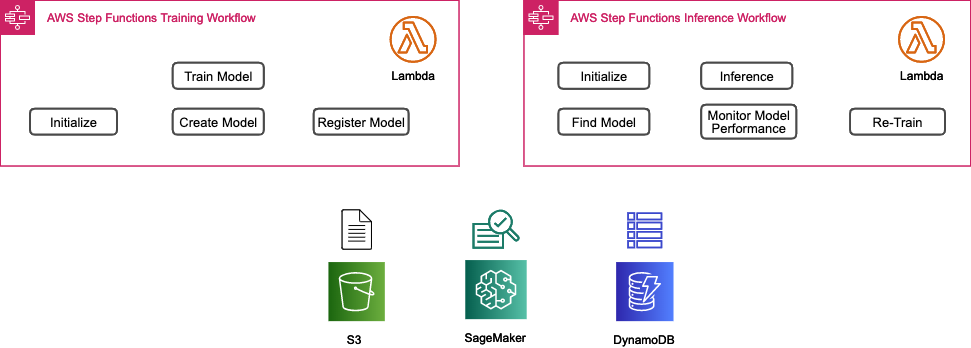
各フローの紹介
今回は大きなタスクとして2つのフローを紹介します。各タスクにおけるStepの詳細もあわせて紹介します。
モデルのトレーニング

Initialize
SageMakerを実行するためのジョブ情報や各種パラメータ等を生成します。具体的には参照するS3バケットの定義などをこのStepで実施しています。
Train Model
「Initialize」のパラメータを元にSageMakerのトレーニングジョブを実行します。このStepでトレーニングを実行するため、アルゴリズムや各種ハイパーパラメータの定義も実施しています。
Create Model
ここでは、トレーニングジョブ結果から、モデルを生成します。S3にモデルを格納するフローとしているため、S3のパス情報などを利用し、モデルの生成と格納を実施しています。
Register Model
最後にモデルのステートを管理するため、DynamoDBにモデルの情報を格納します。

実際のDynamoDBのTableとしては、このような情報を持っており、この情報を利用して、今回の2つのタスクを結びつけてフローを回すように管理しています。今回のケースだと、「SAGEMAKER_MODEL_NAME」がそれに値します。
今回の大きなポイントはこのStepをDynamoDBで実現していることです。このStepを活用することで、様々なユースケースに対し、柔軟性が高いプロセスを作ることができると思います。
また、各Stepでエラーが発生した場合は、Handle ErrorのStepに飛ばし、Failureとして処理を終了します。
モデルの性能評価
ここでは、一度作成されたモデルの情報を利用し、推論評価をSageMakerのバッチ変換機能を利用して実施。評価結果が、閾値より低い場合は、再学習を実施するといったフローが、以下の図になります。
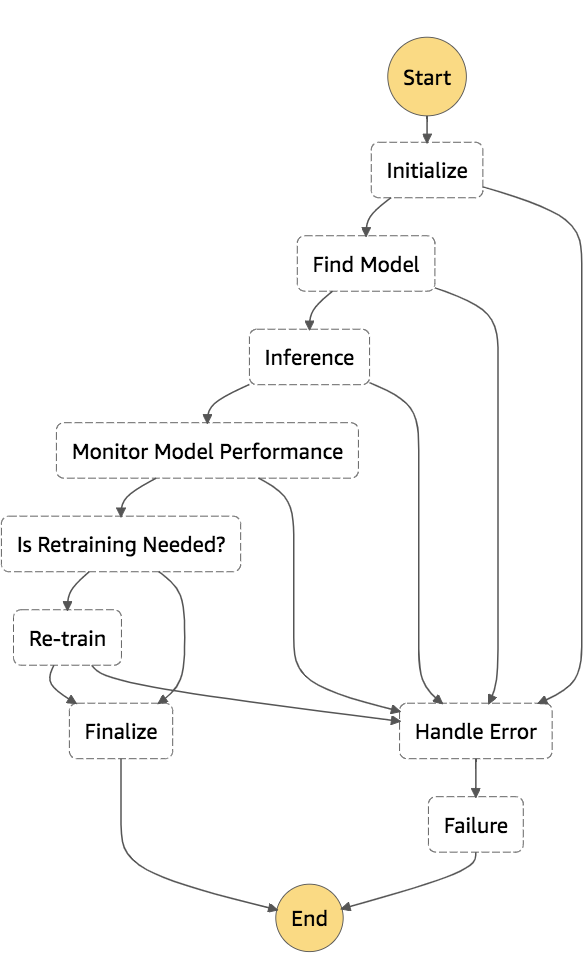
Initialize
モデルの情報や、推論データ入力用・結果格納用のS3のパス情報などの各種パラメータ情報を生成します。
Find Model
「Initialize」のパラメータから、モデルの情報を取得します。
Inference
SageMakerのバッチ変換機能を実行します。バッチ変換機能については、データセット全体の推論をバッチ的に取得する場合に利用する機能となります。詳細についてはこちら。
今回は、Step FunctionsからSageMakerのバッチ変換機能を実行し、このStep内で推論結果を返す挙動となります。ジョブ名やモデル名、入力するデータセットなどの情報を利用し、実行します。バッチ変換に利用するインスタンスタイプ(リソース)などもここで指定します。
Monitor Model Performance
バッチ変換で得られた結果から評価指標を取得します。
Predictionで得られた評価指標とTargetで得られた評価指標を取得し、MonitoringOutputとしてModelPerformance(評価指標)を作成します。

Is Retraining Needed?
MonitoringOutput(評価指標値)があらかじめ決めた閾値よりも悪い場合は「再学習(Re-train)」、閾値よりも良い場合は「Finalize」とし、処理を終了する分岐となります。
Re-train
「モデルのトレーニング」タスクを実行して、再度モデルを作成、精度を上げるようなアクションとなります。
Cloud Formation
今回のフロー実装に利用したCloud FormationのYAMLファイルをこちらに公開してます。今回の環境を一気に作成でき、各パラメータなども確認できると思いますので、ぜひお試しください。
実際にフローを試してみて
今回のフローについては、トレーニングと性能評価のタスクを組み合わせて、評価指標を定義できるテーマであれば、有効なアプローチだなと感じました。また、特にDyanamoDBを利用してステートを管理できることにより、より柔軟な評価フローを実装できると思いますので、色々なパターンのモデルの精度向上に対して効率の良いアプローチが見込めるのではないかなと思います。
今回は、主にAWSを活用したMLプロセスのご紹介でしたが、プロセスについては、プロダクション利用や研究開発などのシーン、テーマやデータなど色々なパターンが有るかと思いますので、是非色々なユースケースをシェアしていけたらなと思います! でわ!