はじめに
こんにちは!
AWSにてインフラを構築するとWAFに触る機会も多いかと思います。
WAFのログを分析して、障害時の調査やリクエストの傾向など知りたい時があります..よね??
そこで今回はWAFのログをAthenaを用いて抽出、おまけでLambdaで定期取得できたらなと思います。
SQL(RDB)も少し関わってくるので、多少知識があると良いかもしれません。
Athenaとは
詳しくは公式に書いてある通りなので省略します。
要点は
- Amazon S3 内のデータを標準 SQL を使用して簡単に分析できる(S3のデータをRDBのように使えるということですね)
- クエリを実行するごとに課金される
くらいでシンプルです。少しでもDB触ったことのある人なら苦労せず構築できそうです。
大まかなフロー
- WAFのログ出力用S3バケットを用意する: 今回は省略
- WAFのログ出力をオンにする: 今回は省略
- Athenaにて1.のS3を元にテーブルを作成する
- コンソールでクエリを発行してみる
- LambdaでAthenaに対してクエリを発行する(おまけ)
では早速
3. Athenaにて1.のS3を元にテーブルを作成する
対象がWAFのログならば下記クエリのコピペで十分です。(公式のママ)
CREATE EXTERNAL TABLE `waf_logs`(
`timestamp` bigint,
`formatversion` int,
`webaclid` string,
`terminatingruleid` string,
`terminatingruletype` string,
`action` string,
`terminatingrulematchdetails` array<
struct<
conditiontype:string,
location:string,
matcheddata:array<string>
>
>,
`httpsourcename` string,
`httpsourceid` string,
`rulegrouplist` array<
struct<
rulegroupid:string,
terminatingrule:struct<
ruleid:string,
action:string,
rulematchdetails:string
>,
nonterminatingmatchingrules:array<string>,
excludedrules:string
>
>,
`ratebasedrulelist` array<
struct<
ratebasedruleid:string,
limitkey:string,
maxrateallowed:int
>
>,
`nonterminatingmatchingrules` array<
struct<
ruleid:string,
action:string
>
>,
`requestheadersinserted` string,
`responsecodesent` string,
`httprequest` struct<
clientip:string,
country:string,
headers:array<
struct<
name:string,
value:string
>
>,
uri:string,
args:string,
httpversion:string,
httpmethod:string,
requestid:string
>,
`labels` array<
struct<
name:string
>
>,
`captcharesponse` struct<
responsecode:string,
solvetimestamp:string,
failureReason:string
>
)
PARTITIONED BY (
`region` string,
`date` string)
ROW FORMAT SERDE
'org.openx.data.jsonserde.JsonSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://bucket/AWSLogs/accountID/WAFLogs/region/webACL/'
TBLPROPERTIES(
'projection.enabled' = 'true',
'projection.region.type' = 'enum',
'projection.region.values' = 'us-east-1,us-west-2,eu-central-1,eu-west-1',
'projection.date.type' = 'date',
'projection.date.range' = '2021/01/01,NOW',
'projection.date.format' = 'yyyy/MM/dd',
'projection.date.interval' = '1',
'projection.date.interval.unit' = 'DAYS',
'storage.location.template' = 's3://(bucket)/AWSLogs/accountID/WAFLogs/${region}/webACL/${date}/')
テーブル作成自体はできてしまうのですが、見慣れない予約語がありますね。
簡単に触れてみましょう
- LOCATION
- テーブルの作成元となるS3のパスを指定します。今回の場合は1.で作成したS3ですね。
- TBLPROPERTIES
- テーブルに適用したいプロパティを定義します。
- projection.*やstorage.location.templateなど設定していますね。この辺りはパーティションというテーブル分割のためのプロパティになります。本記事で触れると長くなりそうなので省略します。
- ※projection.region.valuesにS3のリージョンが含まれていることは確認しましょう!
- PARTITIONED BY
- ここも同様に別途まとめたいと思います。
クエリを実行し、SELECTしてみるとテーブルが作成されていることを確認できます。
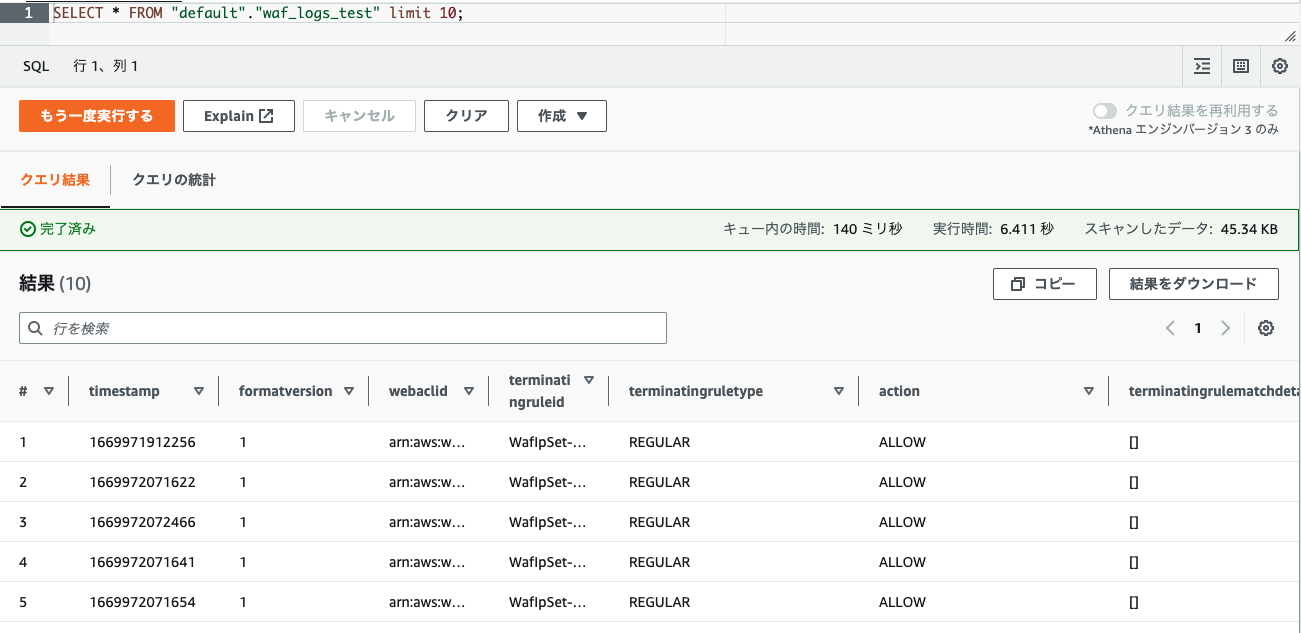
4.コンソールでクエリを発行してみる
テーブルを作成できれば、いつものSQLと同じ感覚でデータ取得できると思います。
ただ一点、WAFログにはhttprequest など中身がJSONのカラムがあります。。
プロパティにはclientIPやuriなど含まれており、抽出の条件に使いたいところです。
もしや文字検索..と思いきや、どうやらstructとして定義?されているようです。

実は先ほどのCREATE文で定義していたのでした。
httprequeststruct<
clientip:string,
country:string,
...
Athenaの場合、構造化定義をしてあるカラムであればhttprequest.clientipのように指定可能になります。
つまり・・
SELECT * FROM "default"."waf_logs_test" where httprequest.clientip='XXX.XXX.XXX.XXX'
といった要領でSQLが書けるわけですね。なんと簡単..
5. LambdaでAthenaに対してクエリを発行する(おまけ)
さて、単発なデータの抽出であればコンソールからクエリを実行すれば十分ですが、実際の運用を考えると定期的に収集しておけると良さそうです。
AthenaのclientSDKは用意されていて、最低限なメソッド(javascript)は下記になります。
- startQueryExecution()
- Athenaに対してクエリを発行します。
- レスポンスとしてQueryExecutionIdを受け取り後述のメソッドで実行状況を取得していきます。
- getQueryExecution()
- QueryExecutionIdをリクエストして、実行状況を取得します。
-
SUCCEEDEDが返却されれば完了です。結果を取りにいきましょう
- getQueryResults()
- QueryExecutionIdをリクエストして、実行結果を取得します。
- レスポンスに実行結果があるのであとはS3に格納したり..!
最後に
Athenaに出会う前はS3からデータ抽出はなんだか億劫だなと思ってましたが、実際にやってみるとほぼSQLの知識だけで構築できて距離がグッと縮まりました!
お次は @akk11_k さんの記事になります!
お楽しみに!