思えば、pythonばかり書いていた
私は、pythonが好きです。何が好きって言われるとよくわからないけど、pythonでのデータ分析ってすごくやりやすいんですよね。numpy,scipy,pandas,seaborn,statsmodels,scikit-learn,chainerと、分析環境としては申し分ないし、特に、__Jupyter__を使うと、トライアンドエラー繰り返しながら、分析結果をリアルタイムに見ながらコーディングやアルゴリズムの実装ができます。__データ分析=python__の構図は私の研究室ではしばらく続きそうです。
だがしかし、C#初心者で、もっと触る機会が欲しい私みたいな人は、機械学習もC#でしたくなることもあるんです。そんなとき、どうすればいいのか
C#で機械学習を試す方法
ざっと浮かんだのが、
- 自力でアルゴリズムを実装
- Azure Machine Learningを利用
- .NETのライブラリを利用
私の足りない頭で浮かんだのはこの程度でした。自力でアルゴリズムを実装するのは、おそらく相当な数学力がいるし時間もそれなりにかかる(勉強にはなるので趣味でやってみたいが)。
__Azure Machine Learning__を使えばクラウド上でモデル構築からcross validationまでできるっぽい。Azure使ってみたい気もするが、基本的に有料?なのでちょっと手がでない...しっかりサービスを発信するってなったら絶対使うと思うけど、個人で少し分析したいって時に使うものなのかなぁ...(誰か詳しい人教えてください)
そうなると、手軽に個人のローカルで試すには、やっぱりライブラリ使えばいいのか!と、そういう結論になってしまう__雑魚パッケージユーザー__←私
で、調べてみるといろいろあるみたい
C#で使える機械学習ライブラリ「Accord.NET」
[C#] Accord.NET を利用したシンプルな画像判定プログラム
Accord.NETによる機械学習 - パーセプトロンの実装
Accord.NETによる線形回帰の実装
Accord.NETというものを使えば手軽にローカルのデータで分析ができそうだ。と、いうことで、上記のサイトを参考に少し実装
今回はSVM、可視化とかはしていない。カーネル関数はlinear,グリッドサーチなどはなし。
まず、サンプルデータとして、Irisデータセットを使用。csvをList形式で落とす。csv読み込みクラスはこんな感じ
using System;
using System.IO;
using System.Linq;
using System.Collections.Generic;
using CsvHelper;
namespace ML
{
public static class LoadData
{
/// <summary>
/// Reads the csv.
/// </summary>
/// <returns>The csv.</returns>
/// <param name="filename">ファイル名</param>
/// <typeparam name="T">CSVのカラム情報.</typeparam>
/// <typeparam name="M">Mapper</typeparam>
public static List<T> LoadCsv<T, M>(string filename) where M : CsvHelper.Configuration.CsvClassMap<T>
{
//絶対ファイルパス
using (var parse = new CsvReader(new StreamReader(filename)))
{
parse.Configuration.HasHeaderRecord = false;
parse.Configuration.RegisterClassMap<M>();
List<T> data = parse.GetRecords<T>().ToList();
return data;
}
}
}
class Iris
{
public double SepalLength { get; set; }
public double SepalWidth { get; set; }
public double PetalLength { get; set; }
public double PetalWidth { get; set; }
public string Species { get; set; }
}
class IrisMap : CsvHelper.Configuration.CsvClassMap<Iris>
{
public IrisMap()
{
Map(x => x.SepalLength).Index(0);
Map(x => x.SepalWidth).Index(1);
Map(x => x.PetalLength).Index(2);
Map(x => x.PetalWidth).Index(3);
Map(x => x.Species).Index(4);
}
}
}
次に、SVM(参考サイトとか公式ドキュメントにもっと詳しい記述が載ってます)
using System;
using System.Text;
using System.IO;
using System.Linq;
using Accord.MachineLearning.VectorMachines;
using Accord.MachineLearning.VectorMachines.Learning;
using Accord.Math;
using Accord.IO;
// http://accord-framework.net/docs/html/N_Accord_MachineLearning_VectorMachines.htm
namespace ML
{
class SVM
{
MulticlassSupportVectorMachine msvm;
double[][] inputs { get; set; }
int[] outputs { get; set; }
public SVM(double[][] inputs, int[] outputs)
{
this.inputs = inputs;
this.outputs = outputs;
}
public SVM() { }
public void learn()
{
var kernel = new Accord.Statistics.Kernels.Linear();
var classes = outputs.GroupBy(x => x).Count();
msvm = new MulticlassSupportVectorMachine(0, kernel, classes);
var teacher = new MulticlassSupportVectorLearning(msvm, inputs, outputs);
teacher.Algorithm = (machine, inputs, outputs, class1, class2) =>
{
var smo = new SequentialMinimalOptimization(machine, inputs, outputs);
smo.UseComplexityHeuristic = true;
return smo;
};
teacher.Run();
}
public int predict(double[] data)
{
var result = msvm.Compute(data);
return result;
}
}
}
最後に軽くテスト。今回は、テストデータと訓練データを4:1に分けて試した。
csvの中身は、3種類のアヤメのデータが50個ずつ入っているので、それぞれ先頭から40個を訓練、最後10個をテストとした。(この、分割の仕方が最高に頭が悪いです。いい実装教えてください。ほんとまじで)
あと、ラベルはIntである必要があるので、文字列を書き換えてます__(ここも最高に頭が悪い実装です。誰か教えてください)__
using System;
using System.Diagnostics;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.IO;
using System.Threading;
using System.Threading.Tasks;
using CsvHelper;
namespace ML
{
class MainClass
{
public static void Main(string[] args)
{
var data = LoadData.LoadCsv<Iris, IrisMap>("iris.csv");
var labelname = data.Select(x => x.Species).Distinct().ToArray();
var feature = (from n in data select new double[] { n.PetalLength, n.PetalWidth, n.SepalLength, n.SepalWidth }).ToArray();
var label = data.Select(x => Array.IndexOf(labelname, x.Species)).ToArray();
var train = feature.Select((x, i) => new { Content = x, Index = i })
.Where(x => x.Index < 40 ||
(x.Index >= 50 && x.Index < 90) ||
(x.Index >= 100 && x.Index < 140))
.Select(x => x.Content)
.ToArray();
var trainl = label.Select((x, i) => new { Content = x, Index = i })
.Where(x => x.Index < 40 ||
(x.Index >= 50 && x.Index < 90) ||
(x.Index >= 100 && x.Index < 140))
.Select(x => x.Content)
.ToArray(); ;
var test = feature.Select((x, i) => new { Content = x, Index = i })
.Where(x => (x.Index >= 40 && x.Index <50) ||
(x.Index >= 90 && x.Index < 100) ||
x.Index >= 140)
.Select(x => x.Content)
.ToArray();
var testl = label.Select((x, i) => new { Content = x, Index = i })
.Where(x => (x.Index >= 40 && x.Index < 50) ||
(x.Index >= 90 && x.Index < 100) ||
x.Index >= 140)
.Select(x => x.Content)
.ToArray();
var svm = new SVM(train, trainl);
svm.learn();
var result = test.Select(x => svm.predict(x)).ToArray();
ClassificationReport(testl, result);
}
/// <summary>
/// Classifications the report.
/// </summary>
/// <param name="truelabel">正解ラベル</param>
/// <param name="predict">予測結果</param>
public static void ClassificationReport(int[] truelabel, int[] predict)
{
Debug.Assert(truelabel.Length != predict.Length);
var labelset = truelabel.Distinct().ToArray();
var tfarray = new bool[truelabel.Length];
double precision;
double recall;
for (int i = 0; i < truelabel.Length; i++)
{
tfarray[i] = truelabel[i] == predict[i];
}
Console.WriteLine("label\tPre\tRec\tF-score");
foreach (var item in labelset)
{
// ラベルがitemのもののindexを正解ラベルからとってくる
var preIndex = truelabel.Select((x, i) => new { Content = x, Index = i })
.Where(x => x.Content == item)
.Select(x => x.Index).ToArray();
var recIndex = predict.Select((x, i) => new { Content = x, Index = i })
.Where(x => x.Content == item)
.Select(x => x.Index).ToArray();
precision = tfarray.Select((x, i) => new { Content = x, Index = i })
.Count(x => 0 <= Array.IndexOf(preIndex, x.Index) && x.Content == true)
/ (double)preIndex.Length;
recall = tfarray.Select((x, i) => new { Content = x, Index = i })
.Count(x => 0 <= Array.IndexOf(recIndex, x.Index) && x.Content == true)
/ (double)recIndex.Length;
Console.WriteLine("{0}\t{1:f2}\t{2:f2}\t{3:f2}", item, precision, recall,
(2 * precision * recall) / (precision + recall));
}
}
}
}
ラベル別のPrecision,Recall,F値は自分で実装。結果はこんな感じ
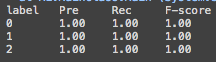
100%とか嘘だろ...
結果はともかく、C#でも機械学習を試せるということが分かったのでいいのかなと思います。
コードはgithubに上げてあるので、こんなクソみたいなコード上げてんじゃねぇ!!と思われた方はぜひアドバイスをお願い致します。もっと上手にC#かけるようになりたいです。
あと、結局研究ではpython使うと思います。