はじめに
この記事は株式会社ナレッジコミュニケーションが運営する Amazon AI by ナレコム Advent Calendar 2020 の 8日目にあたる記事になります。
AWS が開催する re:Invent 2020 で発表された Amazon SageMaker の新機能である Amazon SageMaker Pipelines を実際に触ってみました。
Amazon SageMaker Pipelines
Amazon SageMaker Pipelines はエンドツーエンドの機械学習ワークフローを管理するための CI/CD サービスです。
Python SageMaker SDK を使用して JSON 形式のパイプラインを定義し、SageMaker studio で視覚的に管理することができます。
機械学習のワークフローには、探索的データ分析やアルゴリズム・パラメーターの設定を行って、トレーニングして本番環境にデプロイというステップがあります。パイプラインの定義部分はコーディングが必要ですが、一度作ってしまえば SageMaker studio 上で実行履歴なども確認できるため、パイプライン開発が爆速になること間違いなしです。
今回はパイプラインの定義の部分を解説していきます。
また本記事では UCI の アワビの年齢データセットを使って SageMaker Pipelines を実際に使ってみます。
こちらの github を参考にしてパイプラインを定義し、生成した JSON ファイルを SageMaker Studio 上で読み込んでいきます。
パイプラインの定義
SageMaker Pipelines では JSON 形式の有効巡回グラフ(DAG)として定義します。定義するには SageMaker Python SDK を使用します。
定義する内容としては
- フィーチャーエンジニアリングステップ(AbaloneProcess)
- トレーニングステップ(AbaloneTrain)
- モデル評価ステップ(AbaloneEval)
- バッチ変換用モデル作成ステップ(AbaloneCreateModel)
- バッチ変換モデル実行ステップ(AbaloneTransform)
- モデルパッケージ作成ステップ(AbaloneRegisterModel)
- モデル検証条件定義ステップ(AbaloneMSECond)
をそれぞれ定義していきます。
完成する DAG は次のようになります。(最終的に SageMaker Studio 上で見れるものです)
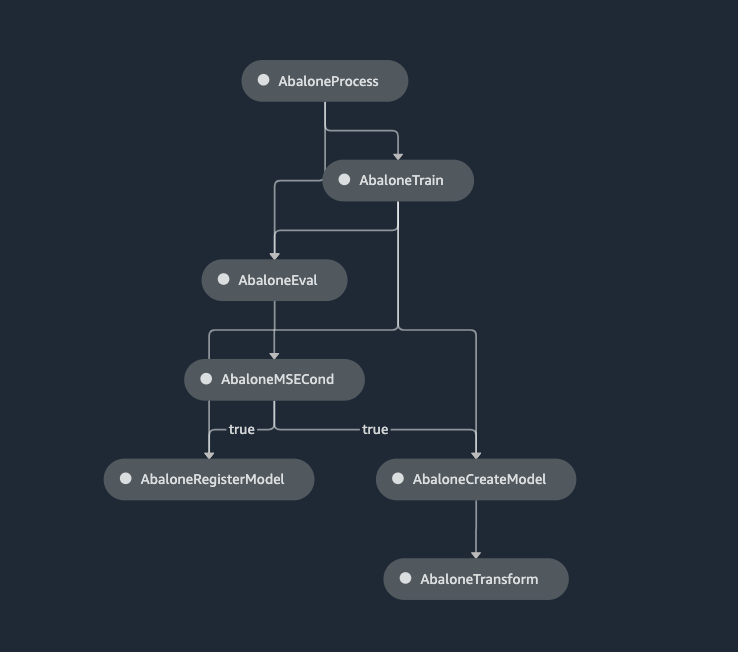
今回は SageMaker ノートブックインスタンスを使ってパイプライン定義を作っていきます。
セットアップとデータの準備
まず環境のセットアップを行います。SageMaker セッションを作成します。
import boto3
import sagemaker
# SageMaker セッションの作成
region = boto3.Session().region_name
sagemaker_session = sagemaker.session.Session()
role = sagemaker.get_execution_role()
default_bucket = sagemaker_session.default_bucket()
model_package_group_name = f"AbaloneModelPackageGroupName"
デフォルトのバケットにデータをアップロードします。
# ディレクトリ作成
!mkdir -p data
# パス指定
local_path = "data/abalone-dataset.csv"
# アワビデータのダウンロード
s3 = boto3.resource("s3")
s3.Bucket(f"sagemaker-servicecatalog-seedcode-{region}").download_file(
"dataset/abalone-dataset.csv",
local_path
)
# データを自分のバケットにアップロード
base_uri = f"s3://{default_bucket}/abalone"
input_data_uri = sagemaker.s3.S3Uploader.upload(
local_path=local_path,
desired_s3_uri=base_uri,
)
print(input_data_uri)
次にモデル作成後のバッチ変換用のデータをアップロードします。
# パス指定
local_path = "data/abalone-dataset-batch"
# バッチ用アワビデータのダウンロード
s3 = boto3.resource("s3")
s3.Bucket(f"sagemaker-servicecatalog-seedcode-{region}").download_file(
"dataset/abalone-dataset-batch",
local_path
)
# データを自分のバケットにアップロード
base_uri = f"s3://{default_bucket}/abalone"
batch_data_uri = sagemaker.s3.S3Uploader.upload(
local_path=local_path,
desired_s3_uri=base_uri,
)
print(batch_data_uri)
ここまででパイプラインに流していくためのデータの準備が完了しました。ここからは実際にパイプラインの中身を作っていきます。
パイプラインパラメータの定義
パイプラインパラメータを定義します。これによってパイプライン定義を変更せずにカスタムパイプラインの実行とスケジュール実行ができるようになります。
from sagemaker.workflow.parameters import (
ParameterInteger, # python の int 型
ParameterString, # python の str 型
)
# 処理ジョブのインスタンス数
processing_instance_count = ParameterInteger(
name="ProcessingInstanceCount",
default_value=1
)
# 処理ジョブの ml.* インスタンスタイプ
processing_instance_type = ParameterString(
name="ProcessingInstanceType",
default_value="ml.m5.xlarge"
)
# トレーニングジョブの ml.*
training_instance_type = ParameterString(
name="TrainingInstanceType",
default_value="ml.m5.xlarge"
)
# 学習したモデルを CI/CD 目的のために登録する承認ステータス
model_approval_status = ParameterString(
name="ModelApprovalStatus",
default_value="PendingManualApproval"
)
# 入力データの S3 バケット URI
input_data = ParameterString(
name="InputData",
default_value=input_data_uri,
)
# バッチデータの S3 バケット URI
batch_data = ParameterString(
name="BatchData",
default_value=batch_data_uri,
)
フィーチャーエンジニアリングステップ(AbaloneProcess)
パイプラインの最初の処理を定義していきます。こちらの処理の内容となる preprocessing.py というファイルを作成します。
流れとしては読み込んだデータに対して
- 連続値のカラム(「性別」カラム以外)に対する欠損値の処理、スケーリング処理
- 離散値のカラム(「性別」カラム)に対する欠損値の処理、エンコーディング処理
をそれぞれ行い、データをシャッフルして
- トレーニング用データ
- 検証用データ
- テスト用データ
にそれぞれ分割し、出力します。
# ディレクトリ作成
!mkdir -p abalone
ファイルを作成して処理内容を書いていきます。
%%writefile abalone/preprocessing.py
import argparse
import os
import requests
import tempfile
import numpy as np
import pandas as pd
from sklearn.compose import ColumnTransformer
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler, OneHotEncoder
# csv ファイルのカラム指定
feature_columns_names = [
"sex",
"length",
"diameter",
"height",
"whole_weight",
"shucked_weight",
"viscera_weight",
"shell_weight",
]
label_column = "rings"
# 説明変数のデータ型
feature_columns_dtype = {
"sex": str,
"length": np.float64,
"diameter": np.float64,
"height": np.float64,
"whole_weight": np.float64,
"shucked_weight": np.float64,
"viscera_weight": np.float64,
"shell_weight": np.float64
}
# 目的変数のデータ型
label_column_dtype = {"rings": np.float64}
# データ型更新用(説明変数、目的変数連結用)関数
def merge_two_dicts(x, y):
z = x.copy()
z.update(y)
return z
# 直接呼び出し時に実行
if __name__ == "__main__":
base_dir = "/opt/ml/processing"
# csv ファイルの読み込み
df = pd.read_csv(
f"{base_dir}/input/abalone-dataset.csv",
header=None,
names=feature_columns_names + [label_column],
dtype=merge_two_dicts(feature_columns_dtype, label_column_dtype)
)
# 連続値カラムに対する前処理
numeric_features = list(feature_columns_names)
numeric_features.remove("sex")
numeric_transformer = Pipeline(
steps=[
("imputer", SimpleImputer(strategy="median")),
("scaler", StandardScaler())
]
)
# 離散値カラムに対する前処理
categorical_features = ["sex"]
categorical_transformer = Pipeline(
steps=[
("imputer", SimpleImputer(strategy="constant", fill_value="missing")),
("onehot", OneHotEncoder(handle_unknown="ignore"))
]
)
# 前処理をまとめる
preprocess = ColumnTransformer(
transformers=[
("num", numeric_transformer, numeric_features),
("cat", categorical_transformer, categorical_features)
]
)
# ラベル用カラム(目的変数)を落として前処理を実行
y = df.pop("rings")
X_pre = preprocess.fit_transform(df)
y_pre = y.to_numpy().reshape(len(y), 1)
# 処理したデータの連結
X = np.concatenate((y_pre, X_pre), axis=1)
# シャッフルして分割
np.random.shuffle(X)
train, validation, test = np.split(X, [int(.7*len(X)), int(.85*len(X))])
# データフレームの出力
pd.DataFrame(train).to_csv(f"{base_dir}/train/train.csv", header=False, index=False)
pd.DataFrame(validation).to_csv(f"{base_dir}/validation/validation.csv", header=False, index=False)
pd.DataFrame(test).to_csv(f"{base_dir}/test/test.csv", header=False, index=False)
各ステップはそれぞれステップ定義用のインスタンスに内容を渡して定義します。フィーチャーエンジニアリングのステップは SKLearnProcessor インスタンスに記述して、ProcessingStep に渡します。(ProcessingStep インスタンスはこの後で作ります)
from sagemaker.sklearn.processing import SKLearnProcessor
# フレームワークバージョンも指定できます
framework_version = "0.23-1"
# SKLearnProcessor インスタンスの作成
sklearn_processor = SKLearnProcessor(
framework_version=framework_version,
instance_type=processing_instance_type,
instance_count=processing_instance_count,
base_job_name="sklearn-abalone-process",
role=role,
)
フィーチャーエンジニアリング用の ProcessingStep インスタンスを作成し、インプットデータやアウトプットデータや先ほど作成した前処理のコードなどを指定して、ステップを定義します。
from sagemaker.processing import ProcessingInput, ProcessingOutput
from sagemaker.workflow.steps import ProcessingStep
# フィーチャーエンジニアリングステップの定義
step_process = ProcessingStep(
name="AbaloneProcess",
processor=sklearn_processor,
inputs=[
ProcessingInput(source=input_data, destination="/opt/ml/processing/input"),
],
outputs=[
ProcessingOutput(output_name="train", source="/opt/ml/processing/train"),
ProcessingOutput(output_name="validation", source="/opt/ml/processing/validation"),
ProcessingOutput(output_name="test", source="/opt/ml/processing/test")
],
code="abalone/preprocessing.py",
)
トレーニングステップ(AbaloneTrain)
XGBoost でモデルトレーニングを行うステップを作成していきます。
from sagemaker.estimator import Estimator
# モデルパスとイメージ URI の指定
model_path = f"s3://{default_bucket}/AbaloneTrain"
image_uri = sagemaker.image_uris.retrieve(
framework="xgboost",
region=region,
version="1.0-1",
py_version="py3",
instance_type=training_instance_type,
)
# XGBoost コンテナの呼びだし
xgb_train = Estimator(
image_uri=image_uri,
instance_type=training_instance_type,
instance_count=1,
output_path=model_path,
role=role,
)
# ハイパーパラメータの設定
xgb_train.set_hyperparameters(
objective="reg:linear",
num_round=50,
max_depth=5,
eta=0.2,
gamma=4,
min_child_weight=6,
subsample=0.7,
silent=0
)
処理内容を TrainingStep インスタンスに渡してトレーニングステップ(AbaloneTrain)を定義します。
from sagemaker.inputs import TrainingInput
from sagemaker.workflow.steps import TrainingStep
# トレーニングステップの定義
step_train = TrainingStep(
name="AbaloneTrain",
estimator=xgb_train,
inputs={
"train": TrainingInput(
s3_data=step_process.properties.ProcessingOutputConfig.Outputs[
"train"
].S3Output.S3Uri,
content_type="text/csv"
),
"validation": TrainingInput(
s3_data=step_process.properties.ProcessingOutputConfig.Outputs[
"validation"
].S3Output.S3Uri,
content_type="text/csv"
)
},
)
モデル評価ステップ(AbaloneEval)
モデル評価ステップを作成するためにモデル評価処理を記述する evaluation.py ファイルを作成します。XGBoost を使って
- モデルのロード
- テストデータの読み込み
- テストデータに対する予測の発行
- 評価指標(適合率・再現率・F1スコアなど)レポートの作成
- 評価レポートの保存
を行います。
%%writefile abalone/evaluation.py
import json
import pathlib
import pickle
import tarfile
import joblib
import numpy as np
import pandas as pd
import xgboost
from sklearn.metrics import mean_squared_error
# 直接読み込み時に実行
if __name__ == "__main__":
# モデルパス指定
model_path = f"/opt/ml/processing/model/model.tar.gz"
# tar ファイルの展開
with tarfile.open(model_path) as tar:
tar.extractall(path=".")
# モデルのロード
model = pickle.load(open("xgboost-model", "rb"))
# テストデータのデータフレーム作成
test_path = "/opt/ml/processing/test/test.csv"
df = pd.read_csv(test_path, header=None)
# DMatrix に整形
y_test = df.iloc[:, 0].to_numpy()
df.drop(df.columns[0], axis=1, inplace=True)
X_test = xgboost.DMatrix(df.values)
# テスト実行
predictions = model.predict(X_test)
# メトリクスの定義
mse = mean_squared_error(y_test, predictions)
std = np.std(y_test - predictions)
report_dict = {
"regression_metrics": {
"mse": {
"value": mse,
"standard_deviation": std
},
},
}
# アウトプット用ディレクトリの作成
output_dir = "/opt/ml/processing/evaluation"
pathlib.Path(output_dir).mkdir(parents=True, exist_ok=True)
# 評価レポートのファイルの作成
evaluation_path = f"{output_dir}/evaluation.json"
with open(evaluation_path, "w") as f:
f.write(json.dumps(report_dict))
ScriptProcessor インスタンスを作成します。(後で ProcessingStep に渡します)
from sagemaker.processing import ScriptProcessor
# ScriptProcessor インスタンスの作成
script_eval = ScriptProcessor(
image_uri=image_uri,
command=["python3"],
instance_type=processing_instance_type,
instance_count=1,
base_job_name="script-abalone-eval",
role=role,
)
処理内容を ProcessingStep に渡してモデル評価ステップを定義します。処理ステップの内容をレポートに格納できるようにもしておきます。
from sagemaker.workflow.properties import PropertyFile
# 処理ステップの内容をレポートに格納するための設定
evaluation_report = PropertyFile(
name="EvaluationReport",
output_name="evaluation",
path="evaluation.json"
)
# モデル評価ステップの定義
step_eval = ProcessingStep(
name="AbaloneEval",
processor=script_eval,
inputs=[
ProcessingInput(
source=step_train.properties.ModelArtifacts.S3ModelArtifacts,
destination="/opt/ml/processing/model"
),
ProcessingInput(
source=step_process.properties.ProcessingOutputConfig.Outputs[
"test"
].S3Output.S3Uri,
destination="/opt/ml/processing/test"
)
],
outputs=[
ProcessingOutput(output_name="evaluation", source="/opt/ml/processing/evaluation"),
],
code="abalone/evaluation.py",
property_files=[evaluation_report],
)
バッチ変換用モデル作成ステップ(AbaloneCreateModel)
バッチ変換を行うためのモデルを作成するステップを定義します。 S3ModelArtifacts から SageMaker モデルを作成します。
from sagemaker.model import Model
# SageMaker モデルの作成
model = Model(
image_uri=image_uri,
model_data=step_train.properties.ModelArtifacts.S3ModelArtifacts,
sagemaker_session=sagemaker_session,
role=role,
)
モデル入力を定義して、作成した SageMaker モデルとともに CreateModelStep に渡してバッチ変換用モデル作成ステップ(AbaloneCreateModel)を定義します。
from sagemaker.inputs import CreateModelInput
from sagemaker.workflow.steps import CreateModelStep
# モデル入力の定義
inputs = CreateModelInput(
instance_type="ml.m5.large",
accelerator_type="ml.eia1.medium",
)
# バッチ変換用モデル作成ステップの定義
step_create_model = CreateModelStep(
name="AbaloneCreateModel",
model=model,
inputs=inputs,
)
バッチ変換モデル実行ステップ(AbaloneTransform)
モデルのトレーニング後にバッチ用データに対する変換処理を実行するステップを定義します。適切なコンピューティングインスタンス、インスタンスカウント及びアウトプット先の S3 バケットを指定して Transformer インスタンスを作成します。
from sagemaker.transformer import Transformer
# Transformer インスタンスの定義
transformer = Transformer(
model_name=step_create_model.properties.ModelName,
instance_type="ml.m5.xlarge",
instance_count=1,
output_path=f"s3://{default_bucket}/AbaloneTransform"
)
TransformStep インスタンスに先ほど作成した Transformer インスタンスとバッチデータの S3 バケットの URI を渡してバッチ変換モデル実行ステップ(AbaloneTransform)を定義します。
from sagemaker.inputs import TransformInput
from sagemaker.workflow.steps import TransformStep
# バッチ変換モデル実行ステップ(AbaloneTransform)
step_transform = TransformStep(
name="AbaloneTransform",
transformer=transformer,
inputs=TransformInput(data=batch_data)
)
モデルパッケージ作成ステップ(AbaloneRegisterModel)
トレーニングステップで指定された Estimator インスタンスを使用して RegisterModel インスタンスを作成します。パイプラインで RegisterModel を実行した結果をモデルパッケージといいます。モデルパッケージには推論に必要な全ての要素をパッケージ化した再利用可能なモデルアーティファクトの抽象化されたもの、というイメージです。
ちなみに model_package_group というのはモデルパッケージの集合体で、パイプラインの実行ごとに新しいバージョンとモデルパッケージがこのグループに追加されていきます。
from sagemaker.model_metrics import MetricsSource, ModelMetrics
from sagemaker.workflow.step_collections import RegisterModel
# モデルのメトリクスの読み込み
model_metrics = ModelMetrics(
model_statistics=MetricsSource(
s3_uri="{}/evaluation.json".format(
step_eval.arguments["ProcessingOutputConfig"]["Outputs"][0]["S3Output"]["S3Uri"]
),
content_type="application/json"
)
)
# RegisterModel の定義
step_register = RegisterModel(
name="AbaloneRegisterModel",
estimator=xgb_train,
model_data=step_train.properties.ModelArtifacts.S3ModelArtifacts,
content_types=["text/csv"],
response_types=["text/csv"],
inference_instances=["ml.t2.medium", "ml.m5.xlarge"],
transform_instances=["ml.m5.xlarge"],
model_package_group_name=model_package_group_name,
approval_status=model_approval_status,
model_metrics=model_metrics,
)
モデル検証条件定義ステップ(AbaloneMSECond)
SageMaker Pipelines では条件ステップを定義して、モデルの評価指標がある閾値を超えたときにモデル登録する、という動きも組み込むことができます。
from sagemaker.workflow.conditions import ConditionLessThanOrEqualTo
from sagemaker.workflow.condition_step import (
ConditionStep,
JsonGet,
)
# モデル評価ステップの出力に対する条件定義と mse の読み込み
cond_lte = ConditionLessThanOrEqualTo(
left=JsonGet(
step=step_eval,
property_file=evaluation_report,
json_path="regression_metrics.mse.value",
),
right=6.0
)
# 条件通過した際の処理
step_cond = ConditionStep(
name="AbaloneMSECond",
conditions=[cond_lte],
if_steps=[step_register, step_create_model, step_transform],
else_steps=[],
)
パイプラインの作成
これまでに作成した全てのステップを結合します。
from sagemaker.workflow.pipeline import Pipeline
# AbalonePipeline パイプラインの作成
pipeline_name = f"AbalonePipeline"
pipeline = Pipeline(
name=pipeline_name,
parameters=[
processing_instance_type,
processing_instance_count,
training_instance_type,
model_approval_status,
input_data,
batch_data,
],
steps=[step_process, step_train, step_eval, step_cond],
)
おわりに
次回は定義したパイプラインを SageMaker Studio 上に表示したり実行履歴のトラッキングをしていきたいと思います!