スクレイピングとは
ウェブサイトから情報を取得し、その情報を加工して新たな情報を生成すること。
1.指定したwebページの情報を表示
import requests
from bs4 import BeautifulSoup
# Webページを取得して解析する
load_url = "https://www.jurassicworld.jp/books/"
html = requests.get(load_url)
soup = BeautifulSoup(html.content, "html.parser")
# HTML全体を表示する
print(soup)
実行結果


2.タグから情報取得
指定のタグなどの情報を表示するには
- find(文字列)
- find(タグ名)
- find(id="id名")
- find(class_="class名") ※classは予約語のため、class_とかく
aタグのリンクを取得する場合やimgタグのsrcを取得する場合
- find("a").get("href")
- find("img").get("src")
3.特定のクラスの情報を取得
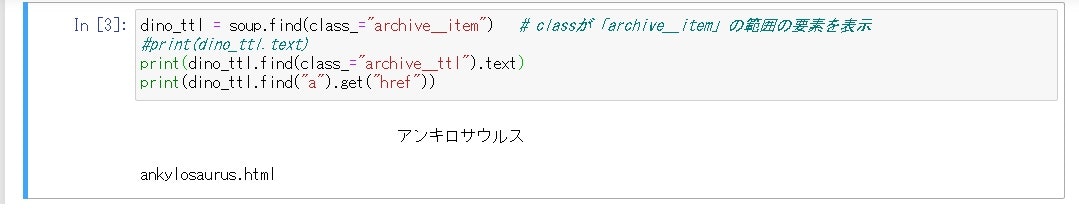
dino_ttl = soup.find(class_="archive__item") # classが「archive__item」の範囲の要素を検索
# dino_ttl内でclass="archive__ttl"の情報を表示
print(dino_ttl.find(class_="archive__ttl").text)
# dino_ttlでaタグ内のリンクを表示
print(dino_ttl.find("a").get("href"))
実行結果
- リンクが相対アドレスになっている
- 条件(classが"archive__ttl")を満たす最初の1つ目のデータしか表示できない
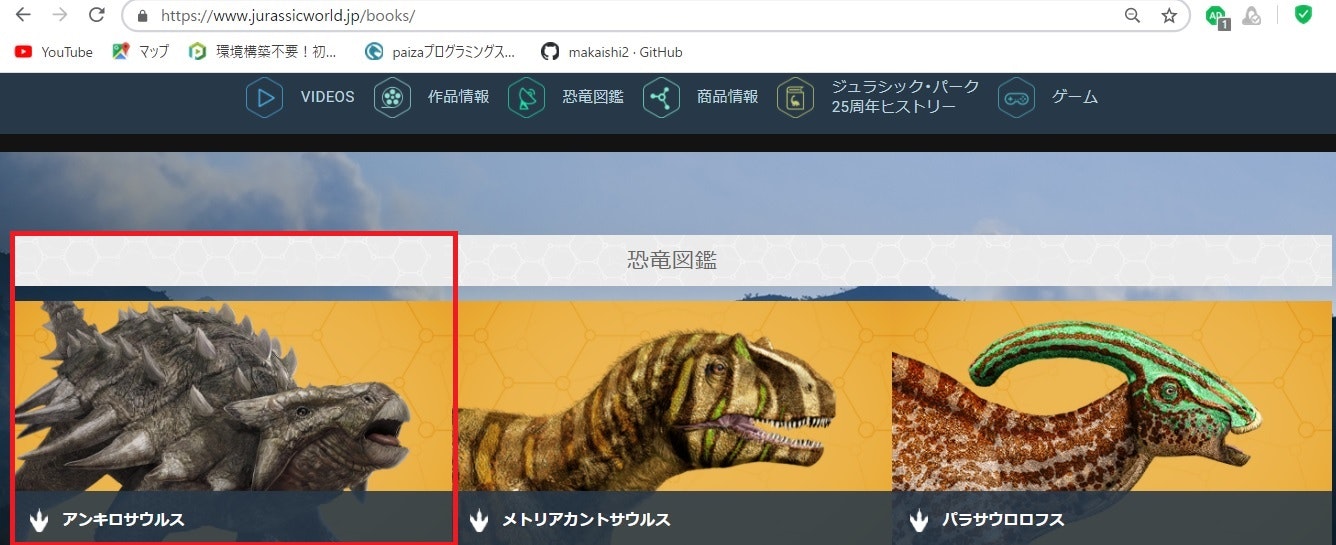
4.取得したいウェブページの構成
①恐竜図鑑

②個々の恐竜をクリックして情報が表示
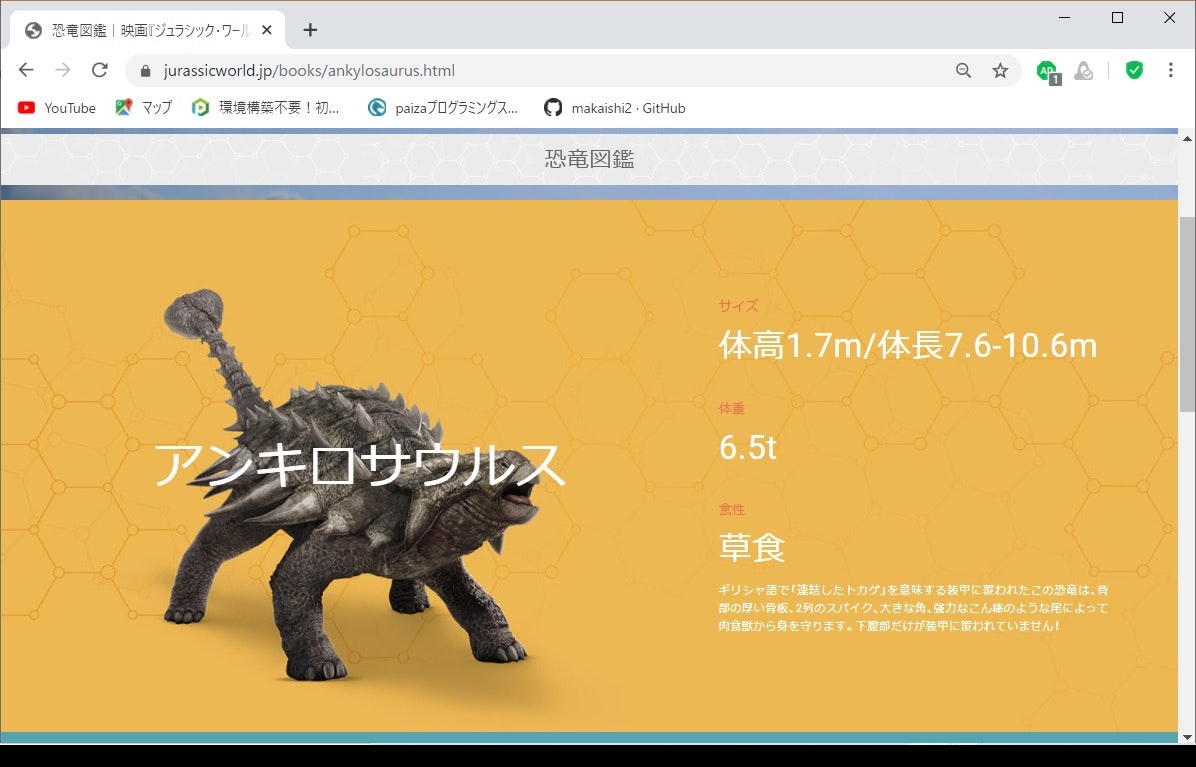
5.恐竜図鑑から、各恐竜の個人情報(サイズ、画像のバス)を抜き出そう
find_all :全てのタグの情報を検索
urllib.parse.urljoin(ベースURL,調べるURL):相対URL(調べるURL)を絶対URLに変換
strip():前後の空白文字を削除
# idがcontentで検索し、その中のすべてのarchive__ttlを検索して表示する
con_ttl = soup.find(id="content") # idが「content」を検索
for element in con_ttl.find_all(class_="archive__item"):
# その中のarchive__ttlの文字列を表示
dino_name=element.find(class_="archive__ttl").text.strip()
print('★'+dino_name+'★')
#恐竜の画像のパス
dino_img=element.find("img").get("src")
#恐竜の画像の絶対パス
dino_img=urllib.parse.urljoin(load_url,dino_img)
print(dino_img)
#archive__item内のリンク先を取得
link_dino=element.find("a").get("href")
#リンクの絶対パスを取得する
link_dinolng=urllib.parse.urljoin(load_url,link_dino)
#個別の恐竜ページに飛ぶ
dino_html = requests.get(link_dinolng)
print(link_dinolng)
soup2 = BeautifulSoup(dino_html.content, "html.parser")
idx0=link_dino.find(".html")
#id=link_dinoから.htmlを除いたものを検索
soup2_uniq=soup2.find(id=link_dino[0:idx0])
#最初のclass=profile__txtにサイズの情報があるのでここを検索
dino_size=soup2_uniq.find(class_="profile__txt").text.strip()
print(dino_size)
実行結果
