 はじめに
はじめに
この記事では、GAS をつかって、Gmail 本文から英単語を抽出し、ANKI 用の単語帳デッキを作成するという 誰得? なレシピをご紹介いたします。
なおこちらは、私も所属しているコミュニティ 「ノンプログラマーのためのスキルアップ研究会」 のブログリレー企画 ノンプロ研 Advent Calendar 2019 の 3 日目 の記事として投稿しております。軽い気持ちで、「GAS 書いて投稿するか~」って余裕ぶっこいてたら、あれ? これむずくね? ってなって締め切り当日、いま泣きながら書いてます。
 ANKI ってなんぞや
ANKI ってなんぞや
ANKI とは、分散学習で効率的に学習をおこなうことができるフラッシュカード ツールです。問題文と解答をペアにした暗記カードの問題集を自作し、PC・スマートフォン上で利用することができます。くわしくは、以下のサイトなどがおすすめです。
はじめてのAnki – まず使ってみる | the right stuff
Ankiで超効率勉強 | Qiita
Ankiを始める/紹介する時に必要な情報を集めたページ | えいらく
 なんでこれをつくろうとおもったのか
なんでこれをつくろうとおもったのか
個人的な話ですが、私の担当している業務のお客さまが海外企業でして、日々の連絡はメール・チャットでの英語がメインという背景があります。とはいっても、恥ずかしながら私を含め、チーム メンバーの英語スキルはほとんどありません。基本的には、Google 翻訳をつかって、コミュニケーションを取ってるような状況です。あとは、ちょろっと自分が読めるので、みんなから聞かれて翻訳してあげるとか、そんな感じです。これ、絶対よくないですよね。
そこで「最低限、メールぐらいは原文のまま読めるぐらいの英語スキルはメンバー全員身に付けなきゃあかんよな」 → 「でもどうやってみんなに学習してもらおうかな」 → 「そういえば、最近 ANKI つかってみたら効率よく、英語読めるようになってきたぞ」 → 「よっしゃ、これで実務に超特化した単語帳デッキつくってみんなに共有したろ!」 という流れです。
 レシピ
レシピ
ステップ
ざっくり、こんな流れでつくっていこうとおもいます。ゴールですが、「海外の担当者 (ジョンとします) から送られてくる英語のメールを原文で読めるようになること」なので、デッキに登録する単語は、過去ジョンから送られてきたメールの中で使われていた英単語のみ に絞ります。
- ジョンからのメールの中には、不要なものもあるので、まず Gmail のフィルタリングをかけます
- デッキ作成用の Google スプレッドシートを作成します
- GAS をつかって対象のメールから本文のみを抜き出します
- 抜き出したメール本文から、正規表現で英単語のリストをつくります
- すでに登録されている英単語であるかチェックします
- スクレイピングで英単語を和訳します
- デッキ用シートに英単語を登録します
- スプレッドシートを CSV 形式でダウンロードして、ANKI にインポートします
1. Gmail フィルタリング
GAS 内でも Gmail のフィルタリングをかけられますが、条件が複雑だと大変になるので、ここは
- Gmail 側でジョンからのメール (From: john@hogehoge.com) を検索する
- ヒットしたメールをすべて選択して、ラベル (ラベル名: Target) をつける
- 除外したいメールを、件名検索などして、"2." で貼ったラベルをはがす
という感じで、取得したいメールにだけラベルをつけて、それを取得するというハックでいきます (@etau 先生、ありがとうございました)。
2. Google スプレッドシート
以下のスプレッドシートを作成します。
-
Google スプレッドシートを新規作成します
-
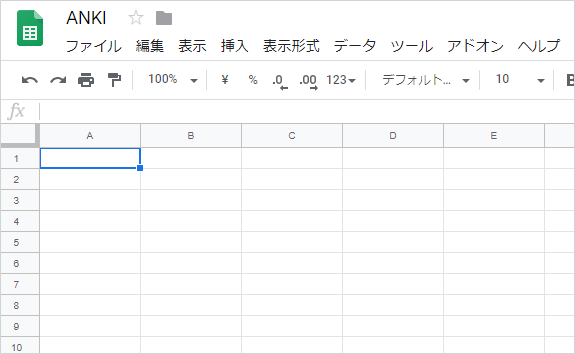
以下 5 枚のシートをつくっておきます

-
各シートの役割はこんな感じです
D - Word Deck: メールの本文を入力するシート
O - Word Deck1: 「D - Word Deck」から英単語のみを抜いて加工するシート
O - Word Deck2: 「O - Word Deck1」で加工後の英単語を、スクレイピングで自動和訳するシート
V - Word Deck: Anki に読み込ませるためのシート (CSV 変換用)
Exclusion Word: 英単語ではない除外ワード (名前など) を設定するシート
3. 対象のメールから本文を抜き出す
GAS をつかって、[1. Gmail フィルタリング](## 1. Gmail フィルタリング) でラベリングした "Target" のメールを対象に、その本文をシート「D - Word Deck」に読み込みます。
function importGmail() {
var ss = SpreadsheetApp.openById('id');
var query = 'label:Target';
var threads = GmailApp.search(query, 0, 10); // 1 度の実行で最大 500 まで
var messages = GmailApp.getMessagesForThreads(threads);
var messagesArray = [];
for(var i = 0; i < messages.length; i++){
messagesArray.push([messages[i][0].getPlainBody()]);
}
var dWordDeckSh = ss.getSheetByName('D - Word Deck');
dWordDeckSh.getRange(dWordDeckSh.getLastRow() + 1, 1, messagesArray.length, messagesArray[0].length).setValues(messagesArray);
}
4. 正規表現で英単語のリストをつくる
正規表現で「2 文字以上かつ、末尾が ' ' または "." 」条件で、メール本文から英単語を抽出します。このとき、スプレッドシートの QUERY 関数をつかって、重複単語を 1 つにまとめ、その重複回数 (出現回数) も表示しています。
-
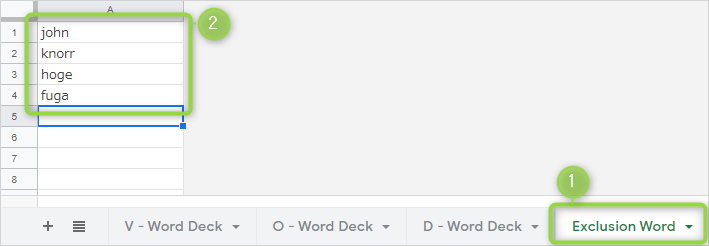
シート「Exclusion Word」に除外したい文字 (名前など) をあらかじめセットしておきます。
-
以下のコードをかきます
extractWordfunction extractWord() { /* 基本シートと値の読み込み */ // シート「D - Word Deck」の読み込み var ss = SpreadsheetApp.openById('id'); var dWordDeckSh = ss.getSheetByName('D - Word Deck'); var dWordDeckValues = dWordDeckSh.getDataRange().getValues(); // シート「O - Word Deck1」の読み込み var oWordDeck1Sh = ss.getSheetByName('O - Word Deck1'); // シート「Exclusion Word」の読み込み var exclusionWordSh = ss.getSheetByName('Exclusion Word'); var exclusionWordValues = exclusionWordSh.getDataRange().getValues(); /* 正規表現による英単語の抽出 */ for(var i = 0; i < dWordDeckValues.length; i++){ var wordArray = dWordDeckValues[i][0].match(/[a-zA-Z]{2,}(?=\s|\.)/gm); // 2 文字以上かつ、末尾が ' ' または "." で終わる (1 文字設定だとゴミを拾うため) wordArray = wordArray.map(function(value){ // ワードをすべて小文字に変換してから二次元配列化する return [value.toLowerCase()]; }); } /* wordArray 内に除外ワードが含まれている場合は削除する */ var wordArrayOneDim = Array.prototype.concat.apply([], wordArray); // 1 次元配列に変換 var exclusionWordValuesOneDim = Array.prototype.concat.apply([], exclusionWordValues); // 1 次元配列に変換 wordArrayOneDim = wordArrayOneDim.filter(function(value) { // 重複を削除する return exclusionWordValuesOneDim.indexOf(value) == -1; }); var wordTempArray = []; wordTempArray = wordArrayOneDim.map(function(value){ // 重複を省いた wordArrayOneDim を新しい二次元配列に格納する return [value]; }); /* シート「O - Word Deck1」の A 列末尾に英単語を追加する */ var oWordDeck1AValues = oWordDeck1Sh.getRange('A:A').getValues(); var oWordDeck1ValuesALength = oWordDeck1AValues.filter(String).length; // A 列の行数を取得 (.getLastRow を使用すると空白行まで取得してしまうため) oWordDeck1Sh.getRange(oWordDeck1ValuesALength + 1, 1, wordTempArray.length, 1).setValues(wordTempArray); // A 列の末尾に英単語を貼り付ける } -
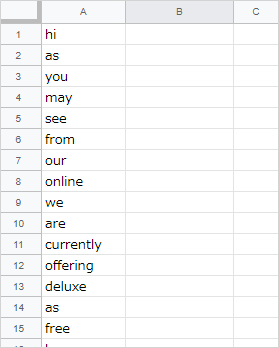
これを実行すると、シート「O - Word Deck1」に英単語がきれいにならびます
-
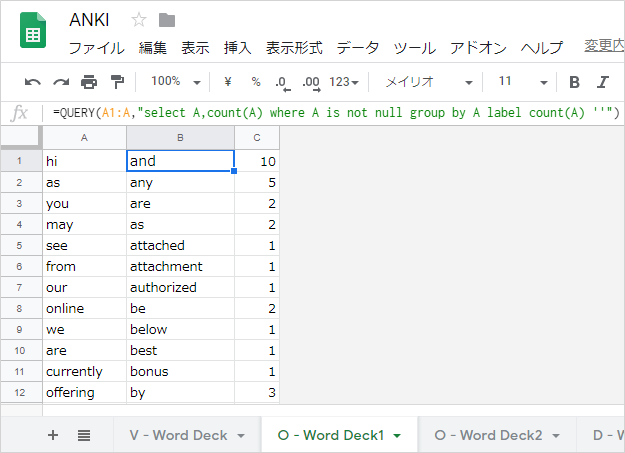
同じシートの B1 シートに QUERY 関数
=QUERY(A1:A,"select A,count(A) where A is not null group by A label count(A) ''")をかきます。すると A 列の重複している単語を B 列では 1 つにまとめ、C 列にはその重複回数 (出現回数) を表示することができます
5. すでに登録されている英単語であるかチェックします
ここでは、さきほど登録した「O - Word Deck1」の英単語が、すでに完成デッキ「V - Word Deck」に登録済みであるかを調べます。実行結果は、以下のようになります。
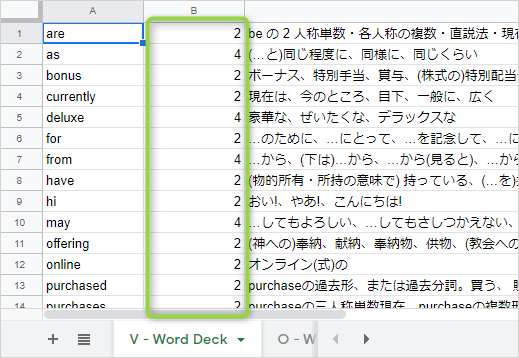
登録がある場合:
「V - Word Deck」側の英単語に対して出現回数を加算し、新規登録しません
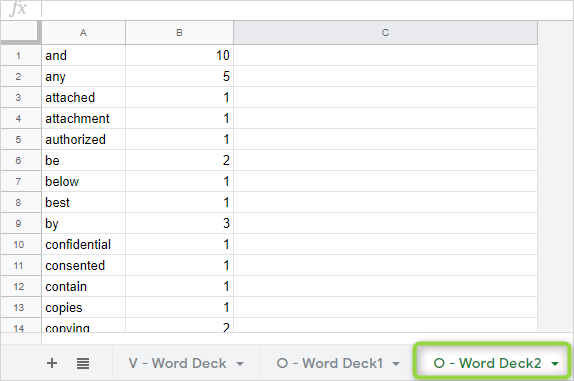
登録がない場合:
新規登録対象の英単語として「O - Word Deck2」に移します
function checkDuplication(){
/* 基本シートと値の読み込み */
// シート「O - Word Deck1」の読み込み
var ss = SpreadsheetApp.openById('id');
var oWordDeck1Sh = ss.getSheetByName('O - Word Deck1');
// シート「O - Word Deck2」の読み込み
var oWordDeck2Sh = ss.getSheetByName('O - Word Deck2');
oWordDeck2Sh.getDataRange().clear(); // 初期化
// シート「V - Word Deck」の読み込み
var vWordDeckSh = ss.getSheetByName('V - Word Deck');
/* 重複している英単語の出現回数を加算する処理 */
// 1. O - Word Deck1 の B 列の 1 次元配列を用意する (貼り付け元)
var oWordDeck1BValues = oWordDeck1Sh.getRange('B:B').getValues();
var oWordDeck1ShBArrayOneDim = Array.prototype.concat.apply([], oWordDeck1BValues); // B 列を 1 次元配列に変換
var oWordDeck1ValuesBLength = oWordDeck1BValues.filter(String).length; // B 列において値が入っている最終行
oWordDeck1ShBArrayOneDim.length = oWordDeck1ValuesBLength; // B 列の値が入っている行数まで切り詰める (空白削除)
// V - Word Deck の A 列の 1 次元配列を用意する (貼り付け先)
var vWordDeckShAValues = vWordDeckSh.getRange('A:A').getValues();
var vWordDeckShAArrayOneDim = Array.prototype.concat.apply([], vWordDeckShAValues);
// 3. O - Word Deck1 の B 列のなかで、V - Word Deck の A 列と重複があるインデックス番号 (行数) を取得して arrayA にいれる
var arrayA = [];
for(var i = 0; i < oWordDeck1ShBArrayOneDim.length; i++){
if(vWordDeckShAArrayOneDim.indexOf(oWordDeck1ShBArrayOneDim[i]) !== -1) arrayA.push(i);
}
// 4. 配列 arrayA の番号をもとに、O - Word Deck1 の C 列にある出現回数の値を新しい配列 popTimeArray にいれる
var oWordDeck1ShCValues = oWordDeck1Sh.getRange('C:C').getValues();
var popTimeArray = [];
for(var i = 0; i < arrayA.length; i++){
popTimeArray.push(oWordDeck1ShCValues[arrayA[i]][0])
}
// 5. V - Word Deck の A 列のなかで、O - Word Deck1 の B 列と重複があるインデックス番号 (行数) を取得して arrayB にいれる
var arrayB = [];
for(var i = 0; i < vWordDeckShAArrayOneDim.length; i++){
if(oWordDeck1ShBArrayOneDim.indexOf(vWordDeckShAArrayOneDim[i]) !== -1) arrayB.push(i);
}
// 6. V - Word Deck の B 列の 1 次元配列を用意する
var vWordDeckBValues = vWordDeckSh.getRange('B:B').getValues();
var vWordDeckShBArrayOneDim = Array.prototype.concat.apply([], vWordDeckBValues);
// 7. vWordDeckShBArrayOneDim に対して、配列 arrayB に記録した行数部分だけに、配列 popTimeArray に格納した出現回数の値を加算する
for( var i = 0; i < arrayB.length; i++){
vWordDeckShBArrayOneDim[arrayB[i]] += popTimeArray[i];
}
// 8. vWordDeckShBArrayOneDim を二次元にして、V - Word Deck の B 列に貼り付ける
var vWordDeckShBArray = [];
vWordDeckShBArray = vWordDeckShBArrayOneDim.map(function(value){
return [value];
});
vWordDeckSh.getRange(1, 2, vWordDeckShBArray.length, 1).setValues(vWordDeckShBArray);
/* 重複していない新規の英単語を O - Word Deck1 から O - Word Deck2 に移す */
var oWordDeck1BCValues = oWordDeck1Sh.getRange(1, 2, oWordDeck1ValuesBLength, 2).getValues(); // B, C列 (英単語 + 出現回数) を配列化
// 重複削除処理
for(var i = 0; i < arrayA.length; i++){ // oWordDeck1BCValues 配列より不要な行を削除する
oWordDeck1BCValues.splice(arrayA[i] - i, 1);
}
oWordDeck2Sh.getRange(1, 1, oWordDeck1BCValues.length, 2).setValues(oWordDeck1BCValues);
}
6. スクレイピングで英単語を和訳します
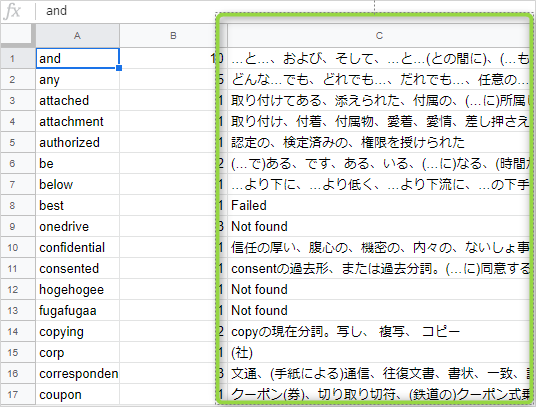
辞書サイトをスクレイピングして、英単語を和訳します。辞書サイトの Weblio さんを使用させてもらいます。以下のコードを実行すると、シート「O - Word Deck2」の C 列に対して、和訳が入ります。
和訳の結果、何らかの理由で取得に失敗した場合は "Failed", 該当する単語が辞書上にない場合は "Not found" を返しています。"Not found" の場合は、シート「Exclusion Word」の除外リストに登録し、次回実行時には登録対象としません。
function doScraping(){
/* 基本シートと値の読み込み */
// シート「O - Word Deck2」の読み込み
var ss = SpreadsheetApp.openById('id');
var oWordDeck2Sh = ss.getSheetByName('O - Word Deck2');
// シート「Exclusion Word」の読み込み
var exclusionWordSh = ss.getSheetByName('Exclusion Word');
/* スクレイピング処理 */
var startTime = new Date().getTime();
var japaneseArray = []; // 日本語訳を格納
var oWordDeck2BValues = oWordDeck2Sh.getRange('A:A').getValues(); // B 列 (英単語) のみ配列化
var oWordDeck2ValuesBLength = oWordDeck2BValues.filter(String).length;
for(var i = 0; i < oWordDeck2ValuesBLength; i++){ // B 列の英単語登録数だけ for を回す
var url = 'https://ejje.weblio.jp/content/' + oWordDeck2BValues[i];
try{
var response = UrlFetchApp.fetch(url).getContentText();
var regex = /<td class="content-explanation ej">.+<\/td>/; // 「主な意味」の取得
var result = response.match(regex);
if(result !== null){ // 検索結果の判定
var regex = /(<td class="content-explanation ej">|<\/td>)/g
result = result[0].replace(regex, ''); // result の前後の html タグを削除する
japaneseArray[i] = [result];
} else {
japaneseArray[i] = ['Not found'];
exclusionWordSh.getRange(exclusionWordSh.getLastRow() + 1, 1, 1, 1).setValue(oWordDeck2BValues[i]); // 検索がヒットしなかったワードはシート「Exclusion Word」 (除外リスト) へ
}
} catch (e) {
japaneseArray[i] = ['Failed'];
Logger.log(url);
}
var endTime = new Date().getTime();
if(endTime - startTime > 60000) break; // スクレイピングの実行時間が 60 秒を超える場合は中断して、それまでに取得した情報を配列へ
}
oWordDeck2Sh.getRange(1, 3, japaneseArray.length, 1).setValues(japaneseArray); // シート「O - Word Deck2」の C 列に日本語訳を貼り付ける
}
7. デッキ用シートに英単語を登録
シート「V - Word Deck」に対して、和訳の結果が "Failed" または "Not found" ではないユニークな単語を登録します。
function generateDeck(){
/* 基本シートと値の読み込み */
// シート「O - Word Deck2」の読み込み
var ss = SpreadsheetApp.openById('id');
var oWordDeck2Sh = ss.getSheetByName('O - Word Deck2');
// シート「V - Word Deck」の読み込み
var vWordDeckSh = ss.getSheetByName('V - Word Deck');
/* D 列が Failed または Not found のインデックス番号を deleteIndexArray に追加する */
var oWordDeck2DValues = oWordDeck2Sh.getRange('C:C').getValues();
var oWordDeck2DArrayOneDim = Array.prototype.concat.apply([], oWordDeck2DValues); // D 列を 1 次元配列に変換
var deleteIndexArray = [];
for(var i = 0; i < oWordDeck2DArrayOneDim.length; i++){
if (/Failed|Not found/.test(oWordDeck2DArrayOneDim[i])) deleteIndexArray.push(i);
}
/* シート「O - Word Deck2」の中で、不要な行を削除し、シート「V - Word Deck」に貼り付ける */
var oWordDeck2Values = oWordDeck2Sh.getDataRange().getValues(); // シート「O - Word Deck2」全体を配列化
for(var i = 0; i < deleteIndexArray.length; i++){ // oWordDeck2Values 配列より不要な行を削除する
oWordDeck2Values.splice(deleteIndexArray[i] - i, 1);
}
vWordDeckSh.getRange(vWordDeckSh.getLastRow() + 1, 1, oWordDeck2Values.length, 3).setValues(oWordDeck2Values);
}
8. ANKI にインポート
最後に、GAS でつくった英単語デッキを ANKI にインポートします。
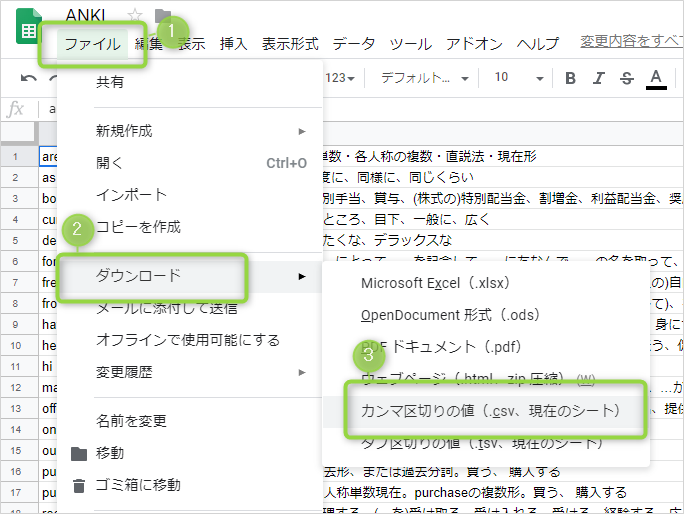
-
シート「V - Word Deck」を csv 形式としてダウンロードします
-
ANKI を立ち上げて、読み込み先のデッキを開きます
-
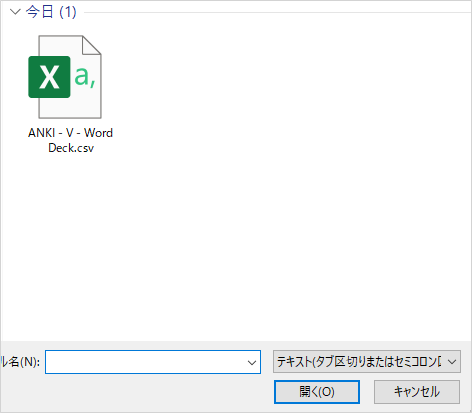
ダウンロードした csv ファイルを読み込みます
-
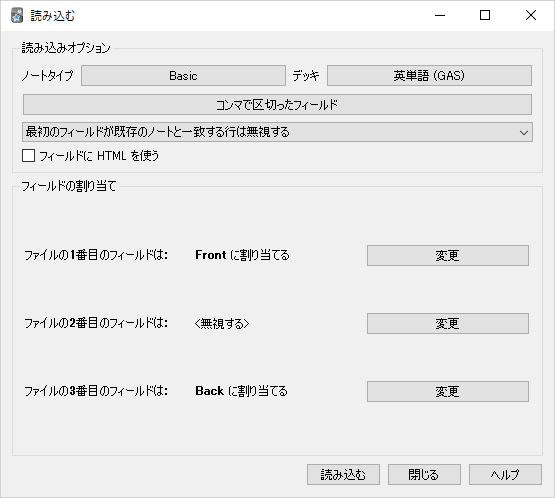
1 列目 (英語) をカードの表面、3 列目 (日本語) をカードの裏面になるようフィールド セットします
-
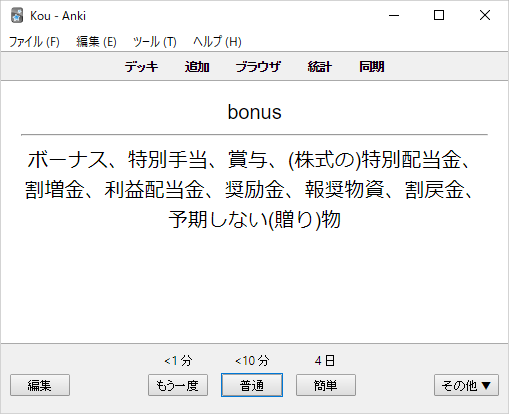
完成 🎉🎉🎉
 おわり
おわり
最近、GAS をさわっていなかったので、このような機会をいただき、アドベント カレンダーに誘ってくれたノンプロ研の方々に感謝です 🙏
大慌てで作ったので、動作テストがほとんどできておりません……。おかしなところが見つかり次第、修正していきます。
また英単語の出現頻度をとっているのに、まったく活用できていなかったり、英語のセンテンスも抜いたほうがよいのに単語止まりと、課題はいろいろあります。
しかし今回、正規表現・スクレイピング・配列操作、あと GAS じゃないんですが QUERY 関数はよくわかっていなかったので、とても勉強になりました。このアプリケーション自体は汎用性ないと思うんですが、ところどころ GAS で使えるエッセンスはあると思うので、なにかの参考になれば嬉しいです!
はーーーー まにあってよかったーーー 安堵 & 安堵