著者の公式実装であるFM-GAN(この記事を書いている時点で消えている)はTensorFlowによる実装だったのですが、その内容をできるだけ忠実にChainerで実装してみました。
ようやくちゃんと動いているっぽいところまでできたので、内容について述べます。
実装したコードのベース
src/autoencoder.pyとsrc/textGan_news.pyに基づいています。
大まかな流れ
LSTMの事前訓練
あらかじめ、LSTMがおかしくない出力をする程度に訓練します。VAE-LSTMとして訓練します。
入力のエンコードとサンプリング
エンコーダ側は入力系列のembeddingを一度正規化し、CNNによって特徴ベクトルを生成し、平均(mu)と分散($\sigma^2$)を求めます。下図のような構造です。
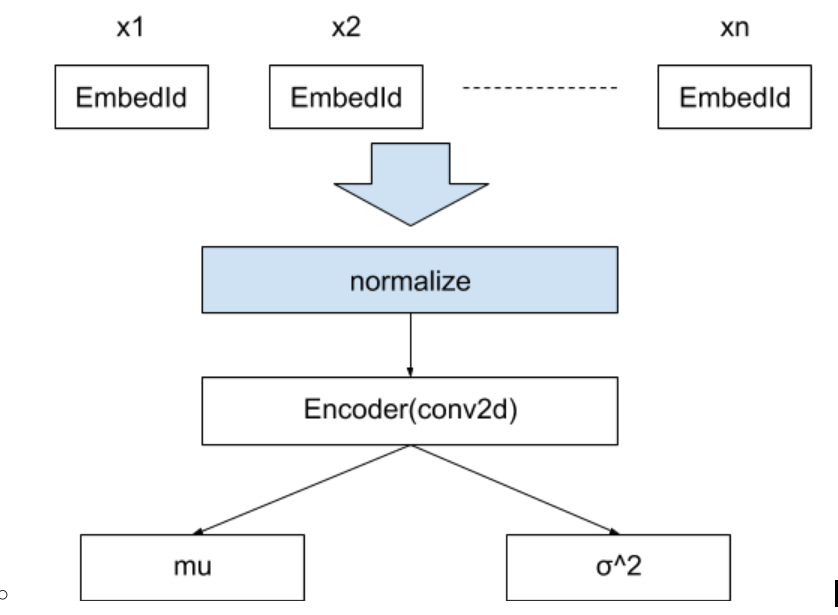
さらに、平均0、分散1のガウス分布からサンプリングを行い、muと$\sigma^2$でスケールを調整し、中間ベクトルHとします。
z \sim \mathcal{N}(0, 1) \\
H = \mu + z \sqrt{ \exp{(\sigma^2)} }
# 実装
x_emb = self.embedding(x)
x_emb = normalizing(x_emb, 1)
x_emb = F.expand_dims(x_emb, 1)
H = self.conv_encoder(x_emb)
H_mean, H_log_sigma_sq = self.vae_classifier(H)
mu = self.xp.zeros((bsize, self.ef_dim), np.float32)
ln_sigma = self.xp.ones((bsize, self.ef_dim), np.float32)
eps = F.gaussian(mu, ln_sigma) # N(0, 1)
H_dec = H_mean + eps * F.sqrt(F.exp(H_log_sigma_sq))
LSTMデコーダ
デコーダ側ではLSTMの初期状態に中間ベクトルHを使います。また、入力系列は先頭にというトークンで始め、各embeddingを正規化したあと線型結合層に通し、Hとconcatした値をLSTMに入力します。
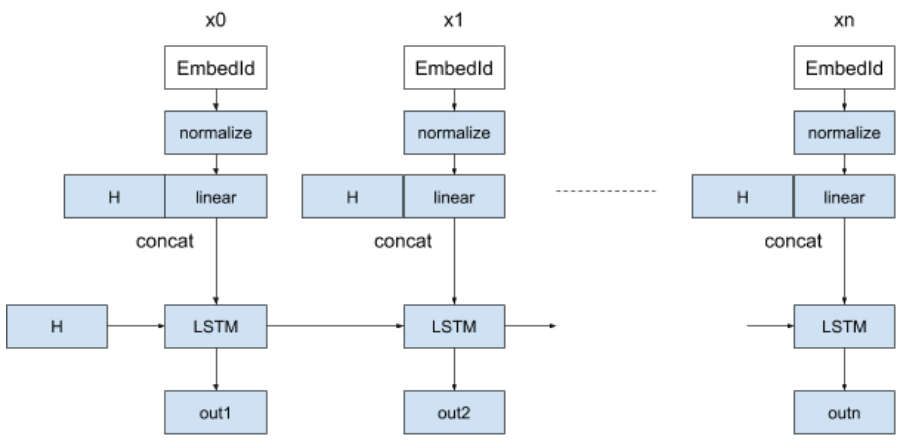
エンコーダの入力とLSTMの出力が同一になるよう訓練をします。
GAN訓練
Generator
VAEで事前訓練したdecoderのLSTM, embedding等の重みを使います。
平均0、分散1の乱数をサンプリングし、それをLSTMの初期状態としてトークンのembeddingから最大長分まで逐次与えていきます。出力は毎回argmaxを取って、最尤なトークンを選択しながら処理します。
embeddingの正規化、線型層、Zとの結合も同じです。
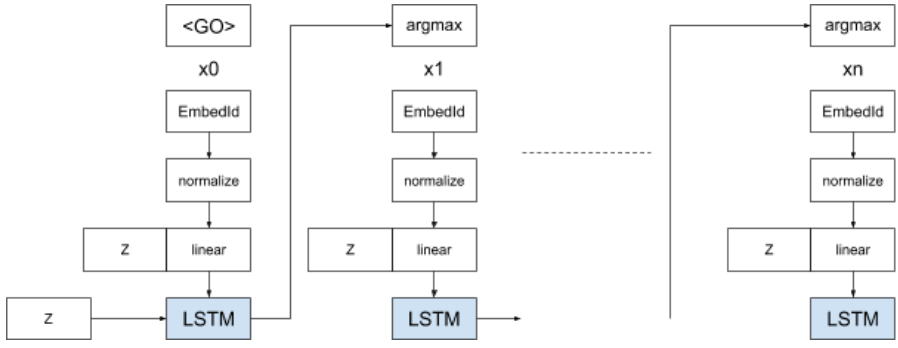
argmaxとは別に、softmaxを取り各時刻の全単語の出現確率(prob)も求めておきます。
z = self.make_hidden(bsize) # F.gaussian
# lstm
x_emb = self.embedding(x)
x_emb = F.expand_dims(x_emb, 1)
x_emb = normalizing(x_emb, 1)
_, syn_sents, logits = self.lstm_decoder(z, x_org, feed_previous=True)
prob = [F.softmax(l * self.L) for l in logits]
prob = F.stack(prob, 1)
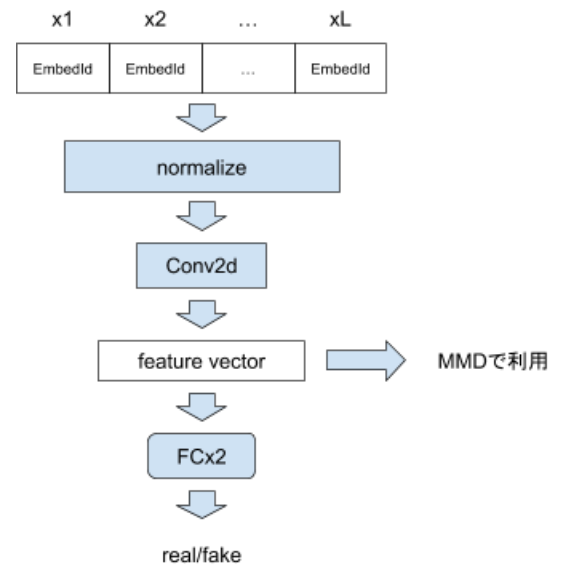
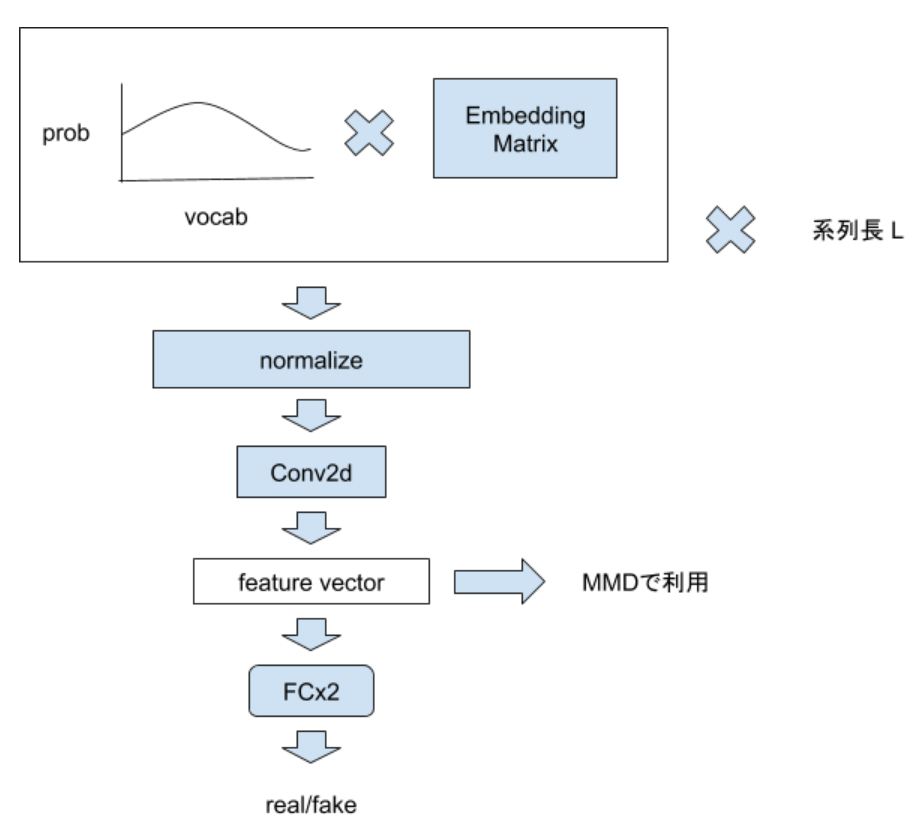
Discriminator
CNNと2層の全層結合です。ただし、入力はreal dataの系列もしくはGeneratorが出力した系列の単語確率分布となります。
後者の場合、全embeddingと確率分布との積を取った結果をCNNに与えます。
CNNの出力(特徴ベクトル)と二値分類の結果、両方を返します。
損失関数
Discriminatorについては通常通りfake/real判定のみを行います。
Generatorについては、real dataとfake dataについての、特徴ベクトル同士をMMD(Maximum mean descripeacy)で比較します。全要素間の差の最大の平均(Maximum Mean)を指標としています。
これにより、2つの特徴ベクトルの分布が一致するように訓練が行われます(Feature Mover's distance, FM-GANの名前の由来)。
実装、訓練上の工夫
LSTMの訓練
十分に訓練し、基本的に文として正しい出力が出る程度に訓練する必要があるようです。
おそらくExposure biasを回避するために、LSTMの系列すべての入力として、サンプリングに基づく値(H)をembeddingと結合して入力しています。
重みの初期値
多くのNN重み初期値は-0.001~+0.001と小さめの値にされています。
学習率
pretrainでは1e-4, GAN訓練では1e-5と小さめにしています。デフォルトで重み減衰などは行っていません。Adamを使っています。
Chainerのデフォルト値0.001ではmode collaspぽい現象が見受けられました。
CNN向けのpadding
あらかじめ入出力系列の最大長を決めておき、それに合わせてCNN向けの入力はオリジナルの入力の前後に<PAD>(embed Id:0)を入れています。
<EOS>は定義していますが、使われていません。