概要
画像投稿サイトPixabayから収集した2000枚程度の猫の画像を、機械学習ライブラリのChainerCVを使って分類してみました。
pixabayはCC0(public domain)Pixabay Licenseというかなり緩いライセンスで画像、動画を収集、公開しているサイトです。検索語に「猫」を指定して集めた画像の中には、実際には猫以外の画像も若干混じっています。
最終的には人力で分類する必要があると思いますが、まずは下処理のために既存の学習済み分類モデルを使ってファイルを分けよう、というのがこの記事で目指しているところです。
ChainerCV
VGGNetの訓練済みモデルは広く配布されており、それを応用した手法も複数存在しています。それを利用した画像分類のツールキットを探していたところ、ChainerCV: a Library for Computer Vision in Deep Learningにたどり着きました。
オブジェクト検出、セマンティックセグメンテーションをサポートしています。
これを利用してファイルを分類するコードを書きました。サンプルの内容をベースにしています。
コード
# !/usr/nogpu/bin/python
# -*- coding: utf-8 -*-
import argparse
import chainer
from chainercv.datasets import voc_detection_label_names
from chainercv.links import SSD300
from chainercv import utils
import os
def main():
chainer.config.train = False
parser = argparse.ArgumentParser()
parser.add_argument('--gpu', type=int, default=-1)
parser.add_argument('--pretrained_model', default='voc0712')
parser.add_argument('src_dir')
parser.add_argument('dst_dir')
args = parser.parse_args()
model = SSD300(
n_fg_class=len(voc_detection_label_names),
pretrained_model=args.pretrained_model)
if args.gpu >= 0:
model.to_gpu(args.gpu)
chainer.cuda.get_device(args.gpu).use()
file_lists = []
for f in os.listdir(args.src_dir):
if not f.startswith("."):
file_lists.append(f)
if not os.path.exists(args.dst_dir):
os.mkdir(args.dst_dir)
cat_id = voc_detection_label_names.index('cat') # 猫に相当するindexの取得
def has_cat(labels):
for l in labels:
if type(l) == int:
if l == cat_id:
return True
for ll in l: # labelsが配列の配列を返すことがある
if ll == cat_id:
return True
return False
print("target file: %d files" % len(file_lists))
count = 0
for f in file_lists:
fname = os.path.join(args.src_dir, f)
img = utils.read_image(fname, color=True)
bboxes, labels, scores = model.predict([img])
if has_cat(labels):
dst_fname = os.path.join(args.dst_dir, f)
os.rename(fname, dst_fname)
count += 1
print("%d: move from %s to %s" % (count, fname, dst_fname))
print("%d files moved." % count)
if __name__ == '__main__':
main()
解説
ChainerCVが対応している手法はいろいろありますが、Faster-RCNNとSingle Shot Multibox Detector(Wei Liu, et al. "SSD: Single shot multibox detector" ECCV 2016.)の2つで試してみたところ、SSDの方が高速だったのでそちらを使ってコードを作成しました。
SSD300クラスインスタンスを生成する時に、事前学習モデルを自動的にダウンロードしてくれます。今回はChainerCV付属のデモデフォルトと同じ"voc0712"を選択しました。このダウンロード処理は初回実行時にのみ行われ、$HOME/.chainer/dataset/pfnet/chainercv/models/ssd300_voc0712_2017_06_06.npzというファイル名で保存されます。
このモデルでは20種類の分類に対応しています。The PASCAL Visual Object Classes Challenge 2012 (VOC2012)に対応したモデルです。
$ python
>>> from chainercv.datasets import voc_detection_label_names
>>> voc_detection_label_names
('aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor')
精度
ざっと見た感じは悪くないようです。処理対象ファイルの中には猫以外のネコ科の動物(ライオン、ヒョウなど)も含まれているのですが、それらはVOC2012の対象外であるため、比較的特徴の近いと思われるcat, dogに分類されることが多いようです。
猫に分類された結果のうち、明らかに猫でないものを選別しました。結果を以下に示します。
| 画像ファイル | 猫に分類されたもの | 猫以外に分類 |
|---|---|---|
| 猫が写っている | 1635 | 70 |
| 猫が写っていない | 7 | 337 |
- 総画像数: 2049枚
- false-negative 7枚
- false-positive 70枚
- precision: 0.9957
- recall: 0.9589
精度は十分高いように見えますが、対象の大半は猫画像であることを考えると一般的に分類精度を評価するであろう環境(適度に各ラベルに相当する画像が同程度ある)と比較するのは若干フェアではないかもしれません。
誤判定事例
いくつか失敗したケースを見てゆきます。
どう見ても猫なのに犬判定
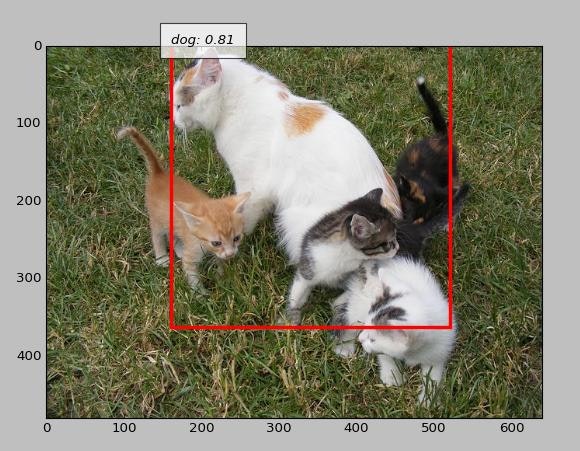
前景のオブジェクが邪魔をしている?

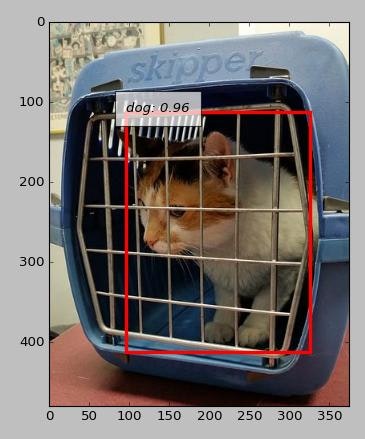
背景の判定の方に引きずられている?
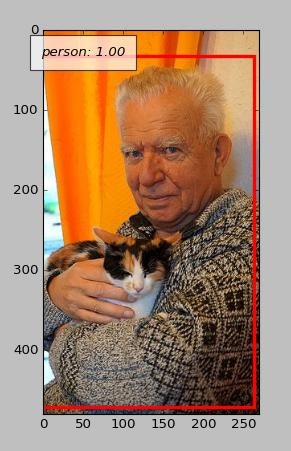
コントラストが良くない
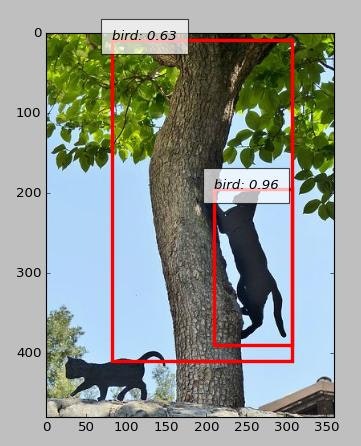
ただの毛糸

像やぬいぐるみ

分類は正しいけど弾いて欲しかったケース
写っているものは猫(あるいはそう見えてもしかたのないもの)で、猫も猫に分類されたケースの事例として、以下のようなものがありました。
- 猫の前足のアップ
- 顔のアップ
- 目の周りだけ
- 口の周りだけ
- しっぽだけ
- ぬいぐるみ
- 写真の加工画像
- 写実的な絵
- そこそこデフォルメされた画像
- 網戸越し
- ピントのあっていない画像
- モノクロ画像
挙動としてはある意味正しいものもあるのでこういったものは手で分類するしかなさそうです。
再現用リポジトリ
自分が画像収集に用いたURLリストをgithubで公開しています。この情報を元に画像データを用意すればこの記事で行ったことを再現可能です。
今後
認識された領域も得られるので、ある程度の割合以下の画像については弾くなどの処理ができるといいかなと思っています。
この結果をpix2pixに利用する予定です(その前段階の記事)。
Pixabayのライセンス変更について追記
正確な日付はわかっていないのですが、PixabayはCC0でのライセンスをやめ、いくつかの制限を追加しました。
Wayback Machineで確認した限りでは、2017/7頃に制限を追加したようです。
機械学習の訓練用データとしてはほぼ問題のないライセンスですが、CC0でなくなったという点に注意してください。