Dockerfile には HEALTHCHECK という指定ができて、これによりコンテナにヘルスチェック機能をつけることができます。要するにコンテナが正常に起動しているかチェックできるということです。
具体的にはコンテナのステータス(docker ps)欄に下記のいずれかを追加することができます。
-
(health: starting): ヘルスチェック中... -
(healthy): ヘルス判定 -
(unhealthy): ダメ
まあ追加できるだけで、上記の状態遷移とdocker-composeが連動したりなどはしません。 当然depends_onとかにも影響はありません…。(ちゃんと実用例はあるようなので、興味のある人は調べてね)
今回はそのヘルスチェックの動きを理解しようと思います。
準備
いちいちDockerイメージをビルドするのが面倒なので、下記のようなdocker-composeを用意しながら
dockerhc/docker-compose.yml
version: "3.4"
services:
a:
image: ubuntu
command: sleep 100000
healthcheck:
test: ["CMD", "false"]
interval: "1s"
timeout: "1s"
retries: 0
start_period: "100s" # since docker-compose 3.4
以下のコマンドで作り直したりして動作確認しましょう。
$ docker-compose up -d --force-recreate
$ docker inspect dockerhc_a_1 | jq '.[0].State.Health.Log'
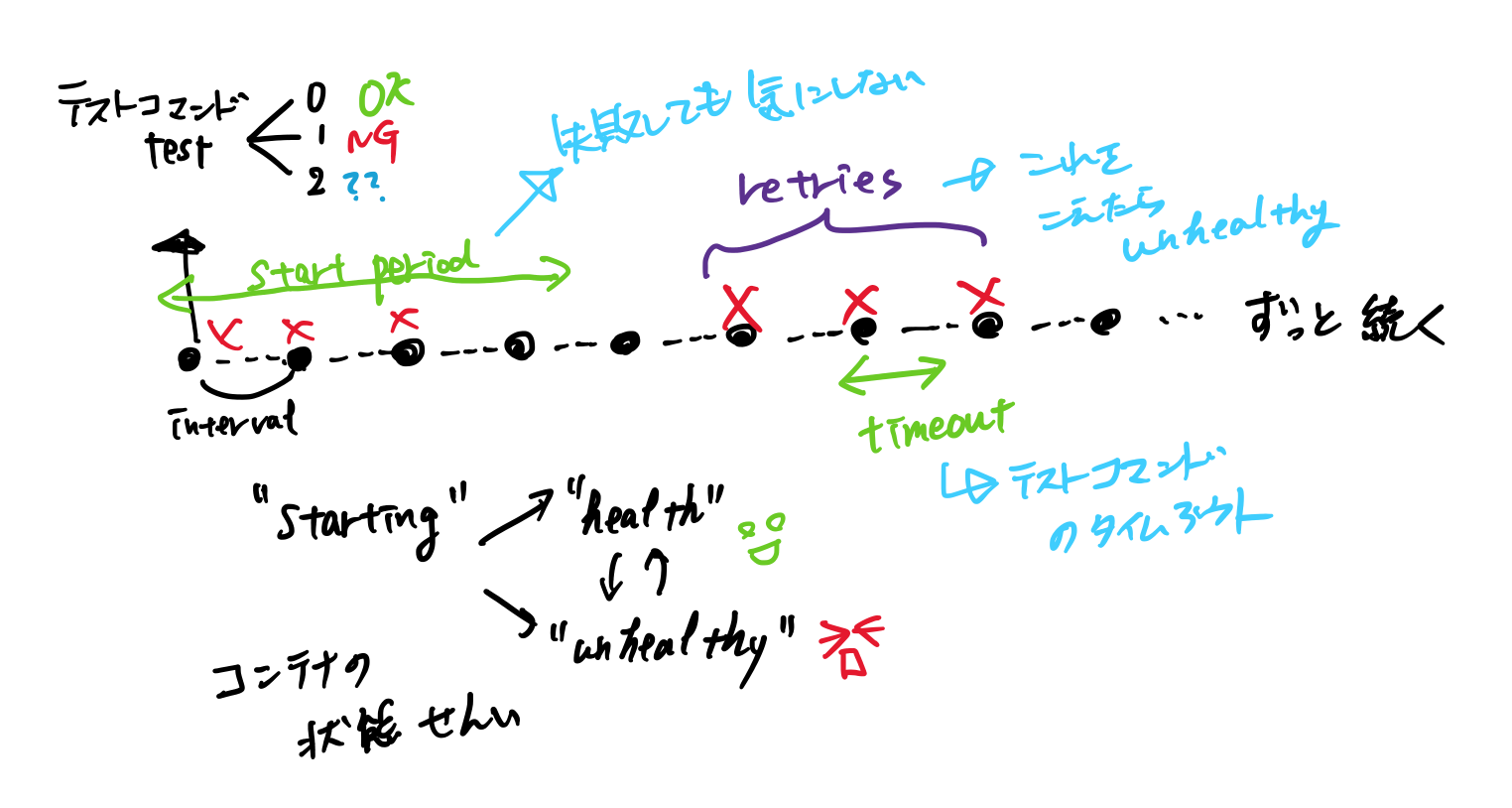
で、結局どういう動きをするのか?
Docker公式マニュアル を読めばちゃんと書いてあるのですが、
- コンテナ起動時から
intervalに指定した時間ごとにヘルスチェックコマンド(testに書いてあるもの)を実行。- exitコードはそれぞれ
0: 成功, 1: 失敗, 2: 予約済を意味する。 - timeout 内にヘルスチェックコマンドが終わらなくても失敗扱い。
- exitコードはそれぞれ
- とりあえず
start_period秒内は失敗しても失敗とカウントしない。- 成功した場合は
healthyに移行。
- 成功した場合は
-
start_periodを脱した後、ヘルスチェック実行時に失敗した場合、unhealthyに移行。- この時、
retriesを指定していた場合は、retries回連続して失敗したらはじめてunhealthy扱い。
- この時、
- その後も状態にかかわらず、ヘルスチェックを実行し続け、それぞれ失敗(
retries回連続しての失敗 )・成功した場合にhealthy/unhealthyに移行。
いったん、 healthy / unhealthy に移行しても、 ヘルスチェック自体は interval に指定した間隔でコンテナが起動している限り永遠に続く ことに留意しましょう。
具体例を通して考える
たとえば、下記のような基準でウェブアプリをヘルスチェックする場合、
- 立ち上がるのに、30秒かかりそう
- 3回ぐらい失敗応答したら許さない
- 応答が5秒以上かかっても許さない
- ヘルスチェックは1分に1度ぐらいに押さえておきたい
下記のように書けばいいでしょう。
docker-compose
healthcheck:
test: ["CMD-SHELL", "curl http://localhost/api/v1/echo || exit 1"] # exitコードは 0 or 1 に揃えておく。
start_period: "30s" # 立ち上がるのに、30秒かかりそう
retries: 3 # 3回ぐらい失敗応答したら許さない
timeout: "5s" # 応答が5秒以上かかっても許さない
interval: "60s" # ヘルスチェックは1分に1度ぐらいに押さえておきたい
# ↑ 当然 Dockerfile に書く時は Dockerfile の文法で同じことを書いてください。
使いどころを考える
素のままの Docker + docker-compose 構成の場合、Dockerコンテナがきちんと立ち上がっているか、人の手でチェックするよりは便利、程度ですかね。
使いどころ、難しいですね。定義されていないDockerイメージがほとんどだと思います。