畳み込み層
プーリング層
交差エントロピー
まずエントロピーとは何か
→エントロピー(平均情報量)(1回の試行の結果を伝えるのに要する平均ビット数)
確率P(ω) で起きるできごとに
長さlog(1/P(ω)) (確率Pが起きることの情報を伝えるのに要するビット数)
これらの総和から求められる式がエントロピー(平均情報量)と呼ぶ(以下)
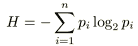
→交差エントロピー
確率にその確率の違うビット数(長さ)をかけたものの総和から求められる式のこと
のちにスクリーンショットで式を貼る
機械学習において分類器を学習するときに、正規の分布Pと分類器の予測分布Qの交差エントロピー H(P,Q)を損失関数とする
これの最小化とはPが固定されている値なのでカルバックライブラー情報量の最小化と同じという意味である
カルバックライブラー情報量とは、ビット長の無駄/価値の誤差のことである。
損失関数
正しいデータと予測するデータの2つの値の差が小さくなるような関数のこと
正しいデータと予測するデータの2つの値の差が小さいということは、その差は違いとなるので差が小さければ小さいほど予測するデータが正しい値に近いということがわかる。
→損失関数の最小を目指して行くのが機械学習の目標と言える。
勾配降下法
ある関数の極小値を算出する手法のこと。
→損失関数(交差エントロピー)に用いる方法で、勾配降下方を用いて損失関数の最小を見つける。
勾配降下法とは、学習データに対する誤差が小さくなる方向に重み(W)を更新し徐々に理想のWへと近づけ行く。
動かす方向は傾きが負となる方向に、傾きに掛け合わせる学習係数により動かす大きさが決まる。
softmax関数
複数ある事象のうち、ある事象が起きる確率を求める関数
Adam
確率的勾配降下法の更新量を調整し学習の収束性能を高めた手法
確率的勾配降下法の傾きの部分を (傾きの平均値)/(傾きの標準偏差) とすることにより、
始めの香辛料は大きく学習が進み、理想の値に近づくほど更新料が減少し学習を収束させられる性質がある。
ReLU
入力が0以下ならば0を出力し入力が0より大きいならば入力と同じ値を出力する非線形関数。
純で計算量が小さく、微分すると活性状態なら1となるので誤差逆伝播法で活性状態の勾配が消えない性質がある事から活性化関数としてよく用いられます。
活性化関数
角層ごとに持つ関数のこと
y(次の層の値) = f( w1x1+w1x2+ ,,,,) + b のf()を指すものが活性化関数となる。
誤差逆伝播
多層のニューラルネットワークにおいて各層の勾配を効率的に求める手法。
出力層から入力層に向かって誤差(ペナルティ)を逆伝播させながら求めて行く
過学習(overfitting)
機械学習の問題では、過学習(overfitting)が問題になることが多くある。 過学習とは、主にパラメータを大量に持ち、表現力が高いこと、訓練データが少ないことによって引き起こされ、訓練データだけに適応し過ぎてしまい、訓練データに含まれない他のデータにはうまく対応できない状態を言う。 機械学習で目指すことは、汎化性能であり、訓練データには含まれないまだ見ぬデータであっても、正しく識別できるモデルが望まれる。複雑で表現力の高いモデルを作ることは可能であるが、その分、過学習を抑制するテクニックが必要となってくる
参考サイト
雑記: 交差エントロピーって何 →交差エントロピーについて
TensorFlowの手書き数字認識チュートリアルからざっくりディープラーニングを勉強してみました
今から参考させてもらおうと思っているサイト
エントロピーからKLダイバージェンスまでの話 →より詳しく交差エントロピーやKLダイバージェンスについて知りたくなったとき
ダイバージェンス関数を数学の立場から概観