今までReduxでのアプリケーションの開発やシンプルなFluxのコードの素振りはしてきました。
なんとなくアーキテクチャについての考え方や仕組みをコード上では確認できました。
**がしかし!!**もっと根本からどういった思想で何が美味しいのかを調べたいと思いました。そんな思いをまとめた記事になります。
MV*の何がだめだったのか
MVCやMVVMなどいろんな概念があります。
MVCとMVVMの違いは図のような感じです。
MVC
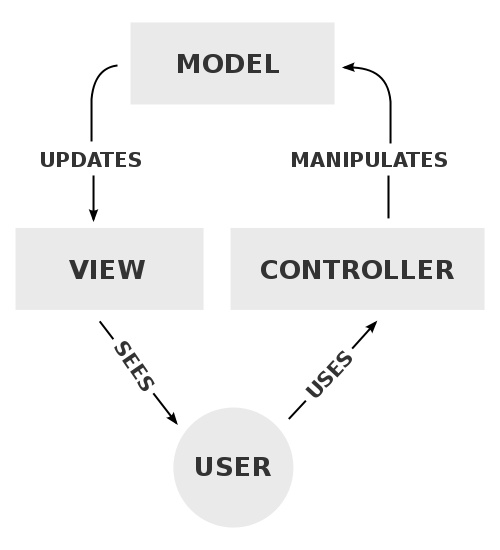
MVVM

一方方向なのか双方向かの違いだけですが、個人的には仲間だと思っているのでここではMVVMを中心に見ていきます。
ViewModelではViewから受け取ったデータをModelが受け取れる形に加工してModelに送ります。
それまでjQueryとAjaxを利用して作成されてきたアプリケーションはModel(ロジック)層とView層に分離させる必要がありました。
ViewとModel(ロジック)の密結合状態はメンテナンスのしにくいコードを生み出しました。
手軽な処理は行えますが、多くの開発者で多くのコードを書くことに向かなかったのです。
MV*フレームワークはViewとModel(ロジック)の分離に成功し、Modelクラスを持つことに成功しました。
Modelのクラスを持つことでデータの制約ができチームでの開発を容易にさせました。つまりModelがアプリケーションの基礎となり、無秩序なコードを生むことを制限させました。
データの複雑性の高まり
さてこの時点でMVVMの問題はありませんでした。しかし機能が多くなるほど少し難しい点が出てきます。
MVVMのJSフレームワークといえばKnockout.jsです(偏見にまみれてます)。
ということでKnockout.jsのTodoMVCを例に見ていきましょう。
TodoMVCは以下のような状態です。

TodoMVCに以下の画像のように処理済みのタブを付け加えると仮定してみましょう。

ViewModelは一つでもいいんですが、後々に肥大化するのが嫌なので分けて考えます。
さてイメージは以下のようになります。

例えばTodoを処理すると反映させるべきViewModelは2つになります。1
ViewModelが増えれば増えるほど、どのViewModelがどのデータに依存しているのかをしっかり把握する必要が出てきます。
加えてAjaxの通信で他の誰かがTodoリストを更新するなど考え始めるとデータの流れは容易に複雑になります。
ModelのデータとViewModelのもつデータは整合性が取れてるでしょうか? ユーザーアクションからのデータの更新だけのフローしか考えられていなかったのではないでしょうか?ViewModelの依存関係は把握できてるでしょうか?
データの変更に対してこのアプリケーションは予測可能な結果をもたらすでしょうか。。。
そしてFlux
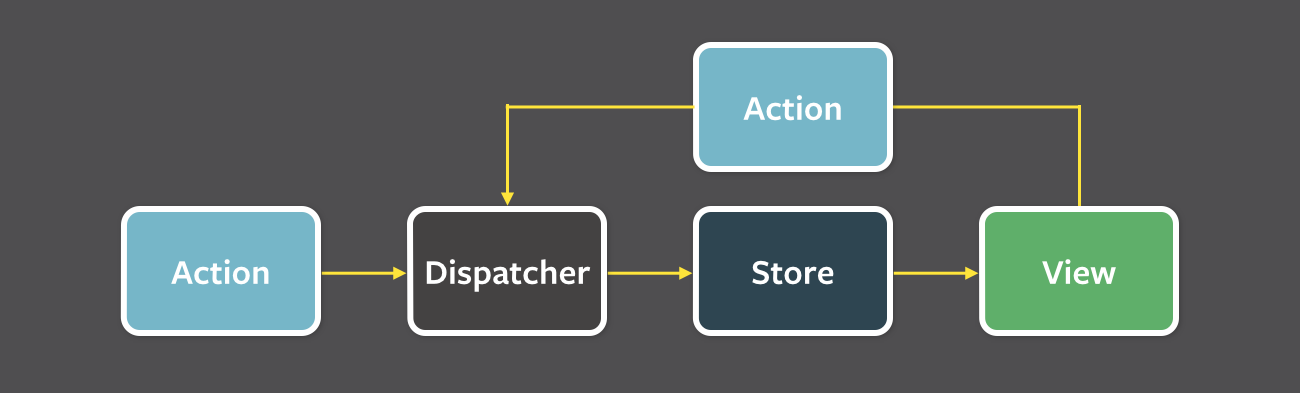
- Stores: アプリケーション全体のデータとビジネスロジック(必ずActionによってデータを更新する)
- View: React等のコンポーネント
- Actions: View等から発火されて作られるイベント
- Dispatcher: 全てのアクションを受けてStoreにイベントを発火する
あとはここら辺を見てもらえたら
https://github.com/facebook/flux/tree/master/examples/flux-concepts
Fluxの良いところ
全てのデータのオペレーションがDispatcherに集約されている点です。
Store側ではDispatcherから送られてくるActionに対してデータを処理する関数を登録してあります。
すなわちActionによるStoreの変更はあらかじめ決められているために、Actionの発行の後のアプリケーションの状態が予測可能になります。
Fluxであればどう解決するのか
FluxではViewModelが増える代わりにActionとStoreが増えます。

Storeが増えますが、Storeは他のストアの更新が終了するまでViewに通知はされません。またStoreは他のStoreに階層構造的に依存します。
すなわちStoreは他のStoreの依存を気にすることなく純粋に対応するデータの更新だけを考えればいいのです。
またアプリ全体で見てもデータについて考えることはStoreの更新だけです。Storeの更新は副作用がないようにデータを更新するので同じデータなのにこちらが古くて新しいという状況も基本的になくなります。
新たにViewやAction等のコードを用意しなければなりませんが、複雑で予測不可能な状態は起こりにくくなったことがわかると思います。
FluxとReduxの違い
Singleton Store: 状態の管理
View: React等のコンポーネント
Actions: View等から発火されて作られるイベント
Reducers: f(state, actions) => newState な副作用のない関数
一番の違いはDispatcherがないことです。あとはStoreがシングルトンになってたりします。
DispatcherがなくなってStoreのデータ更新部分がfunctionになったことでコードの削減と関数の再利用性を上げています。
もっと色々あるらしいんですが、気になる人はこちらをご参照ください。
http://stackoverflow.com/questions/32461229/why-use-redux-over-facebook-flux
以降FluxはReduxも含めた文脈で記述します。
ではMV*は死んだのか
MV*のフレームワークだって設計次第でスケールできるのです。依存関係やデータの状態はフレームワーク任せにするのではなく、依存関係を明らかにしながら実装していけばそう簡単にはぐちゃぐちゃなコードにはならないと思います。
ただViewをまたぐデータを扱う場合に何も考えないなら強い規約で縛られるFluxの方が楽だよねという話ではあります。
あとこれもつけ加えておかないといけませんが 上記の図の通りMVCに関しては一方方向のデータフローです
ちなみにMVCのJSフレームワークといえばBackbone.js(個人の見解です)ですが、BackboneのViewはModelをlistenして結果のみをレンダリングするので一方方向のデータフローが実現できています。
またFluxはいいことづくめのように見えますが、実は決まり文句のコードが多く少しの機能を実装するのに多くのコードが必要となり少し冗長なように思えます。
また新たに入る開発者は大量に定義される既存のActionを理解しておく必要があり手間です。
結局はMVCの焼き直しなのか
Dispatcherは単純にイベントを裁くものと化しているのでControllerの役割よりもっと何もしないイメージです。
個人的には一方方向のデータフローは同じだけどViewにEvent(Action)の発行元だけ持たせてアプリケーション全体をEventドリブンにしたってイメージです。
さらにStoreを直接触れない(setterがない)こと。状態を保持する箇所を全てStoreに集約したおかげで、Store以外は同じ入力に対して常に同じ結果を返すようになりアプリケーション全体の見通しが良くなったメリットも見逃せない点です。
またMVCでもMVVMと同じように複数のViewにまたがるようなデータは前述と同じような問題?が生じます。
つまり焼き直しではあるけどより良いものを目指したMVCフレームワークとも言えるかもしれません。
結論
FluxはMVとは全く違う概念ではなく、今までの概念の延長線上に存在するということです。
では全く便利でないかというとそうではなく、前述の通り複数のViewをまたぐデータを受け渡したり参照するときにModelの依存関係を考えることなく変更したいデータを変更することができます。
Fluxがいついかなる時も有用ということはなくMVも死んでいない。作成するアプリケーション、チームによって何が良いフレームワークとなるのかは異なると考えるべきです。
Fluxの説明のページでもFacebookはMVCを否定はしていません。ただ自分たちのアプリケーションに合わないということを説明しています。
https://facebook.github.io/flux/docs/in-depth-overview.html#content
-
本当はKnockout.jsはViewModelは一つで子を複数持つイメージ ↩