はじめに
本投稿は Oracle Database or GoldenGate Advent Calendar 2018 の Day 13 の記事になります。
※昨日は、kurouuuron さんの インスタンス化SCNを使ってお手軽初期移行 の投稿でした。
本投稿では、PythonでStatspackのTOP5待機イベントを見える化について書きます。
Statspackレポート 待機イベントとは
StatspackはOracleの性能分析をするためのツールで、
性能分析を実施するにはtxt形式のレポートを出力します。
Statspackは、DBのエディションが「Standard Edition」 または、「Enterprise Edition」 で [Diagnostics Pack]ライセンスを購入されていない場合にStatspackを設定するDBが多いと思います。
※Statspackの説明は以下のリンクを参照ください
http://www.oracle.com/technetwork/jp/articles/index-349908-ja.html
Statspackレポートを出力してわかることはいろいろあります
・DBでどんな待機イベントが発生しているか
・DBでどんな処理を実行しているか(時間モデル統計)
・ワークロード(redo生成量、秒間SQL実行回数、秒間トランザクション数)
・高負荷SQLの情報
など
DB性能分析、性能劣化の調査を行う場合、
STATSPACKを出力して 一番に確認するのは、「待機イベント」を確認して、DBの状態を確認します。
■Statspackのイメージ

今回やりたいこと
各期間のスナップショットの待機イベントを見える化します。
通常は各Statspackの待機イベントの各項目を抽出して、Excelでグラフで見える化します。
■通常

■今回のPythonスクリプトでやりたいこと
Statspackレポートを抽出することなく、スナップショット指定期間の「待機時間が長い上位5位の待機イベント」の傾向を見えるします。

top5events.pyを実行すると、スナップショット期間の「待機時間が長い上位5位の待機イベント」をグラフ化した画面を表示します。

事前準備
※今回の投稿記事の実行環境は、Windows環境になります。
以下の準備が必要です。
1.Pythonインストール
2.PythonのOracleDB接続設定
1.Pythonインストール
Anacondaこちらからインストール
( https://www.anaconda.com/download/ )
⇒Pythonの最新バージョンは、3ですので、3.xをインストール
2.PythonのOracleDB接続設定
cx_Oracleのインストール、Oracle Clientインストール、Windows環境変数を設定します
詳細手順は以下の投稿で纏めています。
Windows環境のPythonからOracleに接続してみる
Pythonスクリプト (top5events.py)
top5events.pyで実行しているSQLは、
STATSPACKレポート作成でコールしている(spreport.sql からコールされる sprepins.sql)で実行しているSQL文を流用しております。
※Pythonスクリプトは折りたたみしてます
**Pythonスクリプト(top5events.py)はこちら**
import sys
import cx_Oracle
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import datetime
import locale
import matplotlib.gridspec as gridspec
# DB接続処理
def Oracle_Connect(Svr,Port,SVS,USR,PWD):
try:
tns = cx_Oracle.makedsn(Svr, Port, SVS)
conn = cx_Oracle.connect(USR, PWD, tns)
return conn
except Exception as e:
print(e)
# sysstat統計取得(引数にイベント名)
def getSYSSTAT(conn,dbid,inst_id,snap_f,snap_e,ename):
cur = conn.cursor()
tcpu_f = 0
tcpu_e = 0
#ループ1回目は 開始SNAP 2回目は終了SNAP
for i in range(1,3,1):
if i == 1:
snap = snap_f
else:
snap = snap_e
sql=" select value \
from stats$sysstat \
where snap_id = " + str(snap) + " \
and dbid = " + str(dbid) + " \
and instance_number = " + str(inst_id) + " \
and name = '" + str(ename) + "' "
cur.execute(sql)
row = cur.fetchall()
for r in row:
if i == 1:
tcpu_f = int(r[0])
else:
tcpu_e = int(r[0])
return (tcpu_e - tcpu_f)
# 待機イベント情報取得
def getTop5SQL(conn,dbid,inst_id,snap_f,snap_e,tcpu,snaptime):
df = pd.read_sql_query(
" select '" + snaptime + "' as sdate ,event,time \
from (select event, time \
from (select e.event event \
, (e.time_waited_micro - nvl(b.time_waited_micro,0))/1000000 time \
from stats$system_event b \
, stats$system_event e \
where b.snap_id(+) = " + str(snap_f) + " \
and e.snap_id = " + str(snap_e) + " \
and b.dbid(+) = " + str(dbid) + " \
and e.dbid = " + str(dbid) + " \
and b.instance_number(+) = " + str(inst_id) + " \
and e.instance_number = " + str(inst_id) + " \
and b.event(+) = e.event \
and e.total_waits > nvl(b.total_waits,0) \
and e.event not in (select event from stats$idle_event) \
union all \
select 'CPU time' event \
, " + str(tcpu) + "/100 time \
from dual \
where " + str(tcpu) + " > 0 \
) \
order by time desc \
) \
where rownum <= 5 ",conn)
return df
# 待機イベント取得処理
def getTop5data(conn,dbid,inst_id,snap_f,snap_e,snaptime):
#CPU TIMEの取得
tcpu = getSYSSTAT(conn,dbid,inst_id,snap_f,snap_e,'CPU used by this session')
#待機イベントの取得
df = getTop5SQL(conn,dbid,inst_id,snap_f,snap_e,tcpu,snaptime)
return df
def top5event(conn,Snap_from,Snam_End):
try:
#stats$snapshotから Snap_from - Snam_End のsnap_id を取得
cur = conn.cursor()
#DBID取得
sql="SELECT DBID FROM V$DATABASE "
cur.execute(sql)
row = cur.fetchall()
for r in row:
dbid =(r[0])
#Instance Number取得
sql="SELECT INSTANCE_NUMBER FROM V$INSTANCE "
cur.execute(sql)
row = cur.fetchall()
for r in row:
inst_id =(r[0])
#指定された時間で再起動があるかを確認。再起動をはさむ場合エラー
sql="SELECT DISTINCT TO_CHAR(STARTUP_TIME,'yyyy/mm/dd hh24miss') STARTUPTIME FROM STATS$SNAPSHOT WHERE SNAP_TIME BETWEEN TO_DATE('" + str(Snap_from) + "','YYYY/MM/DD HH24MISS') \
AND TO_DATE('" + str(Snam_End) + "','YYYY/MM/DD HH24MISS') AND INSTANCE_NUMBER = " + str(inst_id) + " "
cur.execute(sql)
strow = cur.fetchall()
#DB再起動をはさんでいる場合、エラーとして処理終了
if len(strow) > 1:
print('Include Some StartUp TIME (DB reboot) ')
for r in strow:
startuptime =(r[0])
print('startuptime : ' + startuptime)
print('Confirm SNAPTIME. ')
return
#SNAP_ID取得
sql="SELECT SNAP_ID,TO_CHAR(SNAP_TIME,'yyyy/mm/dd hh24:mi:ss') SNAPTIME FROM STATS$SNAPSHOT WHERE SNAP_TIME BETWEEN TO_DATE('" + str(Snap_from) + "','YYYY/MM/DD HH24MISS') \
AND TO_DATE('" + str(Snam_End) + "','YYYY/MM/DD HH24MISS') AND INSTANCE_NUMBER = " + str(inst_id) + " ORDER BY SNAP_ID"
cur.execute(sql)
rows = cur.fetchall()
#SNAPが2つ以上ない場合はレポート作成できないのでexit
if len(rows) < 2:
print('NO STATSPACK DATA CHECK BEGIN/END SNAPSHOT')
return
#SNAP_IDを配列に格納
snap_f=0
snap_e=0
snaptime =""
#待機イベントdataframe空枠作成
df=pd.DataFrame(columns=['SDATE','EVENT','TIME'])
for r in rows:
if snap_f == 0:
snap_f = r[0]
snaptime= r[1]
else:
snap_e = r[0]
if snap_e > 0:
print("SNAP_TIME : " + str(snaptime) )
#待機イベントデータ取得
dftop5ret = getTop5data(conn,dbid,inst_id,snap_f,snap_e,snaptime)
#dfに追加
df = df.append(dftop5ret)
#SNAP_IDの移動
snap_f = snap_e
snaptime= r[1]
snap_e = 0
#DB切断
conn.close()
#日付形式に変換
#グラフ表示時に日付形式にしないとうまく表示されない
df['SDATE'] = pd.to_datetime(df['SDATE'])
#ピボットグラフ作成
pv=df.pivot_table( values ='TIME',index = ['EVENT'], columns = ['SDATE'],aggfunc = 'sum', fill_value = 0 ,margins=True,margins_name='TOTAL')
pv.sort_values(by='TOTAL',ascending=False,inplace=True)
#行列入れ替え
dftop5=pv[:6].T
#[TOTAL列を削除]
drop_idx = ['TOTAL']
dftop5.drop(drop_idx, inplace=True)
drop_col = ['TOTAL']
dftop5.drop(drop_col, axis=1, inplace=True)
#描画設定
fig = plt.figure(figsize=(12, 6))
plt.subplots_adjust(left = 0.1, right = 0.7)
plt.style.use('ggplot')
ax1 = fig.add_subplot(1,1,1)
dftop5.plot(ax =ax1 ,kind='area')
plt.title("TOP5 Wait Events", fontsize=14)
plt.xlabel("", fontsize=12)
plt.ylabel("Wait Time(second)", fontsize=12)
plt.legend(bbox_to_anchor=(1.02, 1), loc='upper left', borderaxespad=0, fontsize=12)
plt.tick_params(labelsize=12)
ax1.xaxis.set_major_formatter(mdates.DateFormatter('%m/%d %H:%M'))
plt.show()
plt.close()
return
except Exception as e:
print('err')
print(e)
# 入力チェック
def inputcheck(Svr,Port,Svs,USR,PWD,Snap_from,Snam_End):
try:
#サーバ名チェック
if len(Svr) == 0 :
print('NO SERVER NAME or IP ADDRESS')
return 1
#ポート番号チェック
if Port.isdecimal() == False:
print('PORT IS NOT NUMERIC')
return 1
#サービス名チェック
if len(Svs) == 0 :
print('NO SID ')
return 1
#ユーザ名チェック
if len(USR) == 0 :
print('NO USERNAME ')
return 1
#パスワードチェック
if len(PWD) == 0 :
print('NO USER PASSWORD ')
return 1
#スナップ開始日付チェック
try:
newDate=datetime.datetime.strptime(Snap_from,"%Y/%m/%d %H%M%S")
except:
print('BEGIN SNAPTIME IS INCORRECT')
return 1
#スナップ終了日付チェック
try:
newDate=datetime.datetime.strptime(Snam_End,"%Y/%m/%d %H%M%S")
except:
print('END SNAPTIME IS INCORRECT')
return 1
except Exception as e:
print('err')
print(e)
if __name__ == '__main__':
#接続文字列取得
print ('====== ServerName or IP Address =====')
Svr = input('> ')
print ('')
print ('===== PORT Number =====')
inPort = input('> ')
print ('')
print ('===== SID =====')
Svs = input('> ')
print ('')
print ('===== DBUSER =====')
USR = input('> ')
print ('')
print ('===== DBUSER PASSWORD =====')
PWD = input('> ')
print ('')
print ('===== BEGIN SNAPTIME =====')
print ('===== yyyy/mm/dd hh24miss ex) 2018/12/01 000000 =====')
Snap_from = input('> ')
print ('')
print ('===== END SNAPTIME =====')
print ('===== yyyy/mm/dd hh24miss ex) 2018/12/01 120000 =====')
Snam_End = input('> ')
print ('=====')
print ('=====')
print ('=====')
#入力チェック
if inputcheck(Svr,inPort,Svs,USR,PWD,Snap_from,Snam_End) == 1:
print('YOU ENTERED AN INCORRECT. EXIT PROGRAM')
sys.exit()
else:
Port = int(inPort)
print ('===== STSRT STATSPACK MAKE GRAPH =====')
try:
#DB接続
conn = Oracle_Connect(Svr,Port,Svs,USR,PWD)
if isinstance(conn, type(None)) == False :
#待機イベントグラフ処理
top5event(conn,Snap_from,Snam_End)
else:
print('CONNECT ERROR CHECK INPUT')
except Exception as e:
print(e)
finally:
print ('===== END STATSPACK MAKE GRAPH =====')
sys.exit()
SQLでもピボットができますが、今回はsprepins.sqlで実行しているSQLを流用してますので、
Python側のDataframeでピボットしております。
※Dataframeでピボットする考え方は、以下の投稿を参照ください
Python Pandas DataFrameでピボットグラフを作成して棒グラフ表示
Python DataFrame ピボットグラフの上位5位(Top 5)のみ抽出して棒グラフに表示
Pythonスクリプトの実行
Windows環境でPythonスクリプト(.py)の実行方法 でも記載してますが、
本投稿ではコマンドプロンプトからPythonスクリプト実行手順を書いています。
1.コマンドプロンプトを起動
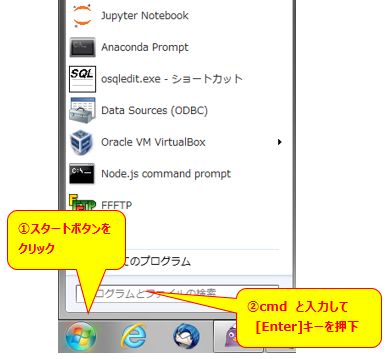
コマンドプロンプト画面が起動
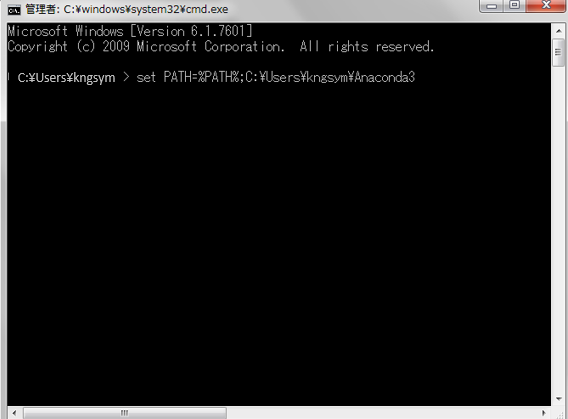
2.環境変数 PATHに Anaconda のインストールしたパスを設定
set PATH=%PATH%;C:\Users\<ユーザ名>\Anaconda3
※Anacondaのインストールパスのデフォルトは
c:\User\ <ユーザ名>\Anaconda3 です
また、事前にコントロールパネルでPATHの設定をしておけば
毎回、環境変数 PATHを設定する必要はありません
3.Pythonスクリプトを実行
python Pythonスクリプト(.py)を指定
Pythonスクリプトは、相対パス or 絶対パスのどちらかを指定
相対パスの場合、コマンドプロンプトのcd でpythonスクリプトの配置しているディレクトリに事前に移動しておく必要があります。
絶対パスの場合、パスから入力する必要があります。
※絶対パスは、以下に説明するpythonスクリプトをドラッグするのみですので簡単に実行できます


[Enter]キーを押下

4.DB接続情報とグラフ作成期間を入力
Pythonスクリプトを実行すると、以下の条件入力を行います。
※各値を入力したら[Enter]キーを押下します
| 実行時に入力する条件 | 説明 |
|---|---|
| ServerName or IP Address | DBサーバ名 or ipアドレスを入力します |
| PORT Number | リスナーのポート番号を入力します |
| SID | SERVICE名でなく SID名を入力します |
| DBUSER | STATS$表にアクセスできるユーザ名を入力します |
| DBUSER PASSWORD | STATS$表にアクセスできるユーザ名のパスワードを入力します |
| BEGIN SNAPTIME | グラフ化する開始スナップショット時間を yyyy/mm/dd hh24miss 形式で入力します 例)2018/12/10 010000 |
| END SNAPTIME | グラフ化する終了スナップショット時間を yyyy/mm/dd hh24miss 形式で入力します 例) 2018/12/10 120000 12時のスナップショットを含める場合、少し余裕をもたせた方がいいかもしれません。2018/12/10 120500 など |
条件を入力して[Enter]

処理実行中の画面

処理がおわると別画面が立ち上がりグラフ表示

グラフ画面はウインドウ右上の[x]ボタンで閉じます
最後に
Top5待機イベント以外の統計値の処理を追加すれば、いろいろな統計値が見える化できます。
(sprepins.sqlを参照して処理を追加するイメージです)

明日は、moritaxp_oiron さんの Oracle Database 18c 「CDBフリート管理」投稿になります。
※こちらを参考ください Oracle Database or GoldenGate Advent Calendar 2018
参考リンク
・Windows環境のPythonからOracleに接続してみる
・Windows環境でPythonスクリプト(.py)の実行方法