Python初心者がある程度のPythonの基礎を勉強した後、pandasやseabornといったライブラリを使用してデータ分析(っぽい) 実装を試してみたものです。
この記事は、Python はじめてのデータ分析の続編になります。
おさらい
前回はPythonのライブラリpandasとseabornの基本的な機能を使いながら、簡単なグラフを表示してみました。
今回はもう少し違うグラフを表示しデータを分析してみたいと思います。
Step3. いろいろなグラフを試してみる
前回、Bostonのデータを読み込み、折れ線グラフを表示して価格を比較してみる、ということを行いました。その際に、seabornのfactorplotを使いましたが、seabornで表示できるグラフは他にも色々あります。
ここではいくつかの前回とは異なる切り口で別のグラフを表示してみたいと思います。
kdeplotで産地別の価格を比較する
kdeplotではカーネル密度推定(有限の標本点から全体の分布を推定する手法)によるグラフが描けます。
x軸に価格をとり、産地ごとにグラフを表示して価格の比較を行ってみたいと思います。
※カーネル密度推定について詳しくは下記など他サイトをご参照ください。
カーネル密度推定
まずはライブラリのインポートとデータの読み込みから。
価格はPackageの種類によってだいぶ変わるようなので、ここでは'36 inch bins'に絞って比較したいと思います。
import pandas as pd
import seaborn as sns
%matplotlib inline
boston_df = pd.read_csv('a-year-of-pumpkin-prices/boston_9-24-2016_9-30-2017.csv', low_memory=False)
boston_df = boston_df.where(boston_df['Package'] == '36 inch bins')
グラフを表示してみます。
sns.kdeplotでも表示できますが、産地ごとの複数のグラフを表示したい場合はFacetGridを使うと良さそうです。
グラフ表示のコードは以下。
graph = sns.FacetGrid(boston_df, hue='Origin', aspect=3)
graph.map(sns.kdeplot, 'Mostly High', shade=True)
graph.set(xlim=(50, 400), ylim=(0, 0.13))
graph.add_legend()
FacetGridでhue='Origin'と指定するとOrigin(産地)ごとに複数のグラフが表示できます。
x軸、y軸の幅を調整し、legend(凡例)を表示して見えやすくします。
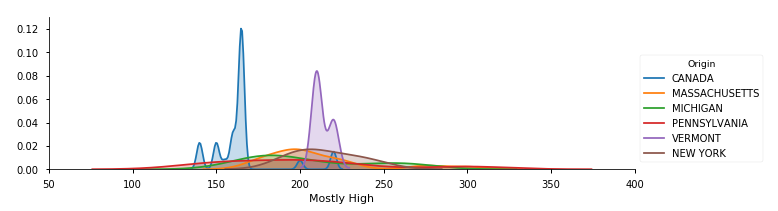
それっぽいグラフができました。
分布を見てみるとCANADA産が価格が低め、VERMONT産が価格が高めと言えそうです。
その他はだいたい同じくらいでしょうか。
lmplotで産地別に価格の分布を表示する
kdeplotも価格比較には良さそうでしたが、さらにデータの相関関係を見るのに良さそうなグラフはないのか…と思い、試してみたのがlmplotです。
lmplotでは散布図を表示したり、回帰分析のためのグラフが描けます。
※散布図、回帰分析について詳しくは下記など他サイトをご参照ください。
散布図
回帰分析
データの読み込みでは同じくBostonのものを使用しますが、複数の条件のグラフを同時に表示することができるのでPackageは'36 inch bins'と'24 inch bins'の2つを出して見たいと思います。
boston_df = pd.read_csv('a-year-of-pumpkin-prices/boston_9-24-2016_9-30-2017.csv')
boston_df = boston_df.where((boston_df['Package'] == '36 inch bins') | (boston_df['Package'] == '24 inch bins'))
続いてグラフの表示。
grid = sns.lmplot(x='Mostly High', y='Mostly Low', col='Package', hue='Origin', data=boston_df)
col='Package'と指定すると、横並びでPackage別にグラフを表示してくれます。
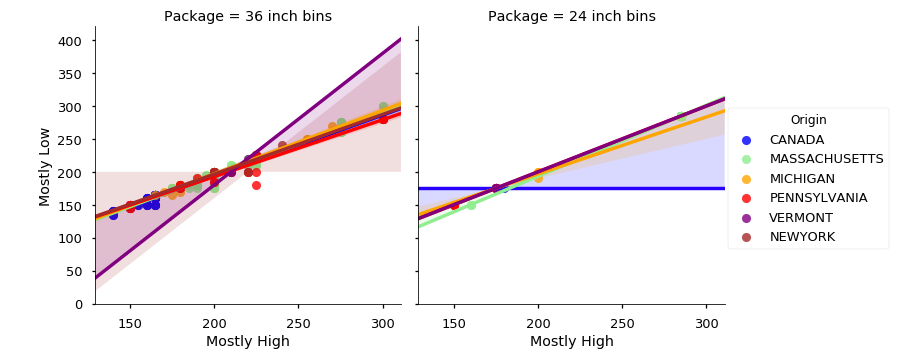
なんだかカラフルなグラフが表示されました。
コードはたった1行ですが、Origin別に色分けされて表示されています。
ただ、x軸、y軸にそれぞれMostly LowとMostly Highの価格をとって見ましたが、これらの相関関係は単純なので、回帰直線も似たり寄ったりになっています。
かえってグラフが見にくくなってしまったので回帰直線は非表示にしてみます。
fit_reg=Falseを追加します。
grid = sns.lmplot(x='Mostly High', y='Mostly Low', col='Package', hue='Origin', fit_reg=False, data=boston_df)
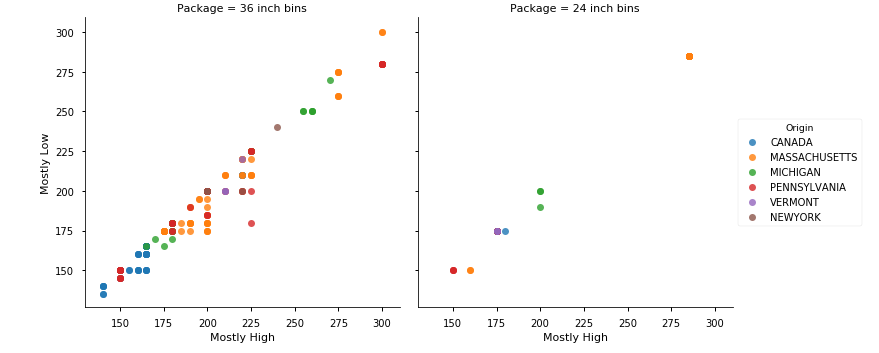
Originが沢山あるとちょっと見にくいかもしれませんが…
それぞれの産地の価格の分布がわかります。
Step4. 複数のグラフを並べて表示する
いい感じのグラフができてきたので、最後にさらにグラフを並べて比較ができるようにしてみたいと思います。
lmplotで横並びでグラフを表示するのにcolオプションを使用しましたが、さらにrowオプションを使用すると条件を増やすことができます。
ということで、Bostonのデータだけでなく他の都市のデータもマージして都市別かつPackage別に価格の分布を見てみたいと思います。
データは以下のように読み込みます。
2つ目の都市はChicagoにしました。
2つの都市のデータはpd.concatで結合して一つのデータにします。
boston_df = pd.read_csv('a-year-of-pumpkin-prices/boston_9-24-2016_9-30-2017.csv',low_memory=False)
chicago_df = pd.read_csv('a-year-of-pumpkin-prices/chicago_9-24-2016_9-30-2017.csv',low_memory=False)
boston_chicago_df = pd.concat([boston_df, chicago_df],ignore_index=True)
boston_chicago_df = boston_chicago_df.where((boston_chicago_df['Package'] == '36 inch bins') | (boston_chicago_df['Package'] == '24 inch bins'))
続いてグラフの表示。
先ほど、Originの色分けについては自動で行ってくれていましたが、任意の色を指定することもできるので、paletteで色を指定して見やすさを調整してみました。
また、BostonとChicagoのデータは同じ産地(CANADA, MICHIGAN)のものがあるので、そのデータのみ違うマーカーにしたいと思います。
マーカーはmarkersオプションで指定できるのですが…
paletteのようにディクショナリで指定できるかと思いきや、配列でしか指定できず…
そのため読み込まれる順番に依存して配列で指定する、というちょっとカッコ悪い書き方になりました。
最後のsubplots_adjustは、グラフのキャプションが長く字が被ってしまうのを避けるために、グラフとグラフの間の幅を調整するために入れたものです。
pal = dict(CANADA="blue", MICHIGAN="orange", MASSACHUSETTS="lightgreen", PENNSYLVANIA="red", VERMONT="purple",
NEWYORK="brown", ILLINOIS="green", OHIO="lightblue", MEXICO="yellow", INDIANA="purple")
markers = ["*", ".", "*", ".", ".", ".", ".", ".", ".", "."]
grid = sns.lmplot(x='Mostly High', y='Mostly Low', col='Package', row='City Name', hue='Origin',
palette=pal, markers=markers, fit_reg=False, data=boston_chicago_df)
grid.fig.subplots_adjust(wspace=.3)
グラフ表示は以下のようになります。
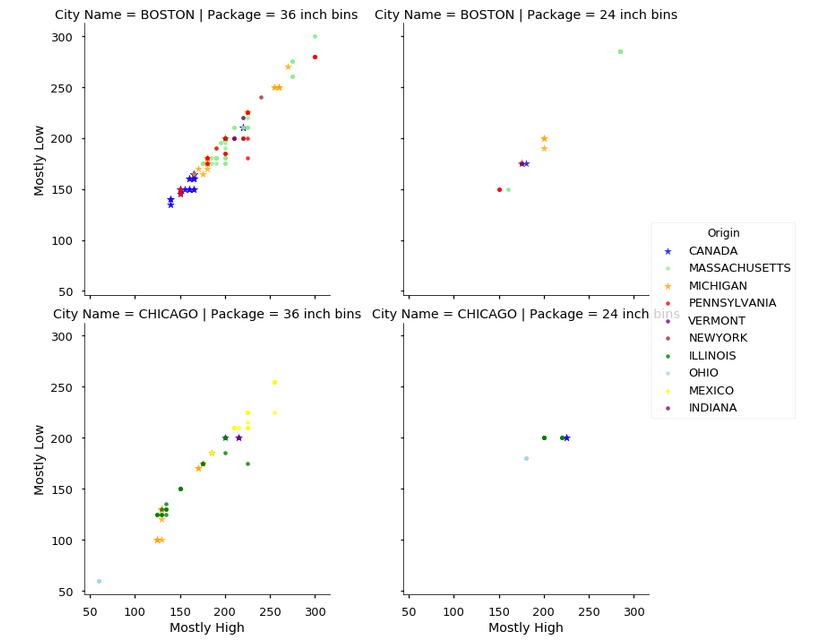
意図するグラフはおおよそできたかと思います。
一つ、どうしても凡例がグラフにかぶってしまい…legend_outオプション(デフォルトはTrue)で位置は変えられるようなのですが、細かい調整ができませんでした、、残念。
おわりに
2回に渡ってpandasとseabornを使った様々な分析を行ってみました。
Python及びデータ分析に関して初心者レベルでできる範囲でも、なかなか面白いグラフが描けたと思います。
seabornに関しては、デフォルトでもそこそこ綺麗なグラフが描ける点が良さそうです。