リポジトリ
ねらい
宇宙科学総合研究会(LYNCS)という団体で、団体内の知識共有・蓄積にMediaWikiを使っています。Wikipediaのような巨大サイトでも動いているだけあって非常に使いやすいのですが、細かい部分で小回りが利かないことも出てきました。
Wikiに記事が増えてくると、カテゴリを整備したくなってきます。ところが、肝心のページ一覧があまり見やすくないのです。
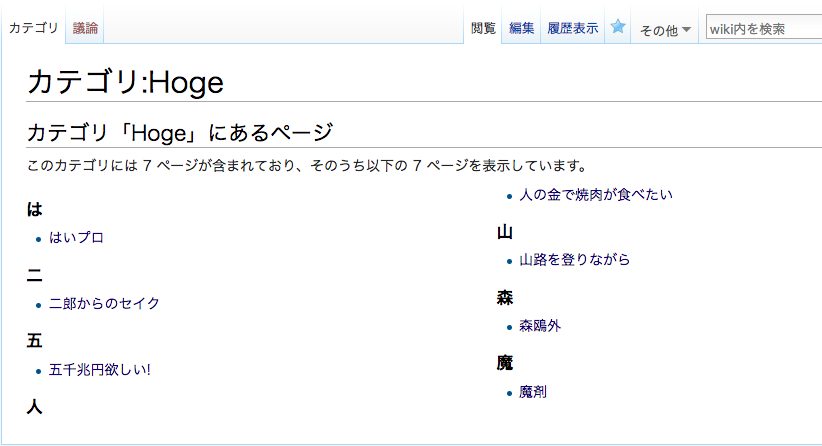
画像の通り、記事名の一文字目からUnicode順でソート・グループ化されます。漢字圏には厳しい仕様ですね。このままでは、日本語タイトルの記事を一覧にすると一文字目の漢字に従ってグループが大量にできてしまいます。
ただし、MediaWikiにはソートキーをユーザ側で指定する機能が用意されています。記事内に {{DEFAULTSORT: そおときい}} などと記述すれば、記事名の代わりに指定した文字列を使ってソートしてくれるのです。
とはいえ既存記事をポチポチ編集してデフォルトソートを追加するのは骨が折れます(Wikipediaは人力だそうです。すごい……)。また、今後の新規記事に、忘れずにデフォルトソートを設定してもらうのはおそらく無理でしょう。
そこで、MediaWiki APIを使って記事を巡回し、記事名のよみがなを自動生成して追加するBotをnode.jsで作りました。
環境
- node.js v8.1.3
- npm v5.0.3
- MediaWiki v1.26.3
方針
MediaWiki API
MediaWikiには、外部からWikiを操作できるAPIが付属しています。これを使えば記事一覧の取得や編集など一通り行うことができます。
MediaWikiのAPIをnode.jsから使う前例がないかなと思って探したところ、npmにライブラリがいくつかありました。必要な機能が揃っていたので、nodemwを使用しています。実際のWikiでも運用されていて信頼できそうです。
const nodemw = require('nodemw');
// ...
const client = new nodemw({
server: '{Wikiのあるサーバ}',
path: '{api.phpのあるパス}',
});
のようにすると使えます。
nodemwのメソッドは全てコールバック方式になっており、そのまま使うと簡単に地獄が出現するので注意です。Node v8の新機能util.promisify()でPromise化してから使うことにします。初めメソッド内で参照するthisが変わってしまい動かなかったのですが、こちらの記事を参考にthisをbindするとうまく行きました。
const util = require('util');
// ...
await util.promisify(bot.logIn).bind(bot) (config.username, config.password); // login
なお、ユーザーネームやパスワードといった外に出せない情報はnode-configを使って外部ファイルから読み込むようにしました。
形態素解析
デフォルトソートのないページを見つけたら、タイトルの読みがなを生成しなければなりません。形態素解析ライブラリを使えば、漢字の読みを得ることができます。
const tokenize = require('kuromojin').tokenize;
const unorm = require('unorm');
// ...
const title = unorm.nfkc(pageTitle); // unicode normalization
const tokens = await tokenize(title);
let reading = tokens.reduce((res, token) => {
return (token.reading) ? (res + token.reading) : (res + token.surface_form);
}, '');
表記ゆれに備えるため、事前にunormによるUnicode正規化も挟みました。元々カタカナや数字だった部分のreadingは空になってしまうので、ない場合は代わりにsurface_formを読みとして追加します。
Wikipediaのルールに合わせる
Wikipediaのソートキーのつけ方にはルールが存在します。人名などに関する細かい規定を除けば、以下のようになります。
- ひらがなで読み仮名を記述する
- 濁音・半濁音は清音に(e.g. が→か)
- 拗音は直音に(e.g. ちょくおん→ちよくおん)
- 長音は母音に(e.g. そーときー→そおときい)
- アルファベットや数字はそのまま記載する
形態素解析の段階では読みはカタカナなので、hakatashi氏のjapanese.jsでひらがなに変換します。
const japanese = require('japanese');
// ...
reading = japanese.hiraganize(reading);
reading = normalizeForDefaultSort(reading);
normalizeForDefaultSort()でWikipediaルール準拠に修正していきます。
まずは濁音/半濁音/拗音。文字コードや正規表現でかっこよくやる方法が特に思いつかず、地道に全通り書き出してreplaceしました。
const defaultSortDictionary = {
'ぁ' : 'あ', 'ぃ' : 'い', 'ぅ' : 'う', 'ぇ' : 'え', 'ぉ' : 'お',
'が' : 'か', 'ぎ' : 'き', 'ぐ' : 'く', 'げ' : 'け', 'ご' : 'こ',
'ざ' : 'さ', 'じ' : 'し', 'ず' : 'す', 'ぜ' : 'せ', 'ぞ' : 'そ',
'だ' : 'た', 'ぢ' : 'ち', 'っ' : 'つ', 'づ' : 'つ', 'で' : 'て',
'ど' : 'と', 'ば' : 'は', 'ぱ' : 'は', 'び' : 'ひ', 'ぴ' : 'ひ',
'ぶ' : 'ふ', 'ぷ' : 'ふ', 'べ' : 'へ', 'ぺ' : 'へ', 'ぼ' : 'ほ',
'ぽ' : 'ほ', 'ゃ' : 'や', 'ゅ' : 'ゆ', 'ょ' : 'よ', 'ゎ' : 'わ',
'ゐ' : 'い', 'ゑ' : 'え', 'ゔ' : 'う'
};
for(const key in defaultSortDictionary) {
if(!defaultSortDictionary.hasOwnProperty(key)) { continue; }
str = str.replace(new RegExp(key, 'g'), defaultSortDictionary[key]);
}
長音はもう少し面倒で、'ー'の直前の文字の母音が何か判定しなければなりません。これもうまい方法が浮かばないので書き出しました。
const cyoonDictionary = {
'あ' : ['あ', 'か', 'さ', 'た', 'な', 'は', 'ま', 'や', 'ら', 'わ'],
'い' : ['い', 'き', 'し', 'ち', 'に', 'ひ', 'み', 'り', 'ゐ'],
'う' : ['う', 'く', 'す', 'つ', 'ぬ', 'ふ', 'む', 'ゆ', 'る'],
'え' : ['え', 'け', 'せ', 'て', 'ね', 'へ', 'め', 'れ', 'ゑ'],
'お' : ['お', 'こ', 'そ', 'と', 'の', 'ほ', 'も', 'よ', 'ろ', 'を']
};
// ...
str = str.replace(/.[\u30FC\u2010-\u2015\u2212\uFF70-]/g, (match) => {
const firstLetter = match.slice(0, 1);
const result = Object.keys(cyoonDictionary).reduce((res, key) => {
return (cyoonDictionary[key].indexOf(firstLetter) >= 0) ? key : res;
}, null);
return result ? (firstLetter + result) : match;
});
return str;
firstLetterが'ー'直前の1文字です。これがcyoonDictionaryの5つの配列のどれかに入っていれば、resultに'あ'〜'お'のいずれかが返ります。
「2017-07-07」のように、長音でない長音符やハイフンの使い方もあり得ます。この場合はresultがnullになり、reduce最後の三項演算子で元のマッチ文字列が採用されます。
実装
メインの処理の流れはこんな感じです。
-
bot.logIn()でログイン(ログイントークン取得) - 名前空間(後述)ごとに全ページ取得(
bot.getPagesInNamespace())- ページごとに本文取得(
bot.getArticle())-
/{{DEFAULTSORT:.*}}/を含むページはスキップ - Unicode正規化・形態素解析・読みがな取得・ひらがな化
- ソートキーのルール通りに変換
- デフォルトソートを末尾に追加して編集(
bot.edit())
-
- ページごとに本文取得(
ログインはトークン取得・トークン送信の二回に分ける、編集の際は別途「編集トークン」を取得するなどの面倒な部分は全てnodemwがやってくれます。
if (require.main === module) { main(); }
function main() {
(async() => {
await util.promisify(bot.logIn).bind(bot) (config.username, config.password); // login to get permisson
for(const ns of config.namespaces) {
const allpage = await util.promisify(bot.getPagesInNamespace).bind(bot) (ns.id); // get page data as JSON
for(const page of allpage) {
let pageData = await util.promisify(bot.getArticle).bind(bot) (page.title);
const pageTitle = (page.title.indexOf(ns.prefix + ':') >= 0) ? page.title.substr(ns.prefix.length + 1) : page.title;
let editSummary = 'Bot: Add DEFAULTSORT ';
if(/\{\{DEFAULTSORT:.*\}\}/.test(pageData)) { continue; } // skip if page already have DEFAULTSORT
const title = unorm.nfkc(pageTitle); // unicode normalization
const tokens = await tokenize(title);
let reading = tokens.reduce((res, token) => {
return (token.reading) ? (res + token.reading) : (res + token.surface_form);
}, '');
reading = japanese.hiraganize(reading);
reading = normalizeForDefaultSort(reading);
pageData += '\n{{DEFAULTSORT: ' + reading + '}}';
editSummary += reading;
await util.promisify(bot.edit).bind(bot) (page.title, pageData, editSummary);
console.info('Edited ' + page.title + '/ ' + editSummary);
}
}
})().catch((err) => {
console.error(err);
});
}
名前空間
MediaWikiのページは「名前空間」で分類されています。カテゴリは「カテゴリ」名前空間、ファイルは「ファイル」名前空間といった具合です。
カテゴリを上位のカテゴリに入れて一覧にすることもあるので、カテゴリにもデフォルトソートを設置することにします。
標準以外の名前空間に属する記事には、タイトルの前に「カテゴリ:」「ファイル:」といった接頭辞がつきます。タイトルを取得するとこれもくっついてくるため、読みがなにする場合は取り除く必要があります。
namespaces: # namespace id and prefix to process
-
id: 0
prefix: ""
-
id: 14
prefix: "カテゴリ"
node-configの設定ファイルに、処理したい名前空間を配列で書いておきます。
idは名前空間を識別する番号で、APIに渡すのに使います。
prefixが除去対象となる接頭辞です。
const pageTitle = (page.title.indexOf(ns.prefix + ':') >= 0) ? page.title.substr(ns.prefix.length + 1) : page.title;
実行例
自分のアカウントで実行すると更新履歴が埋まってしまうので、Bot用に新しくアカウントを発行します。
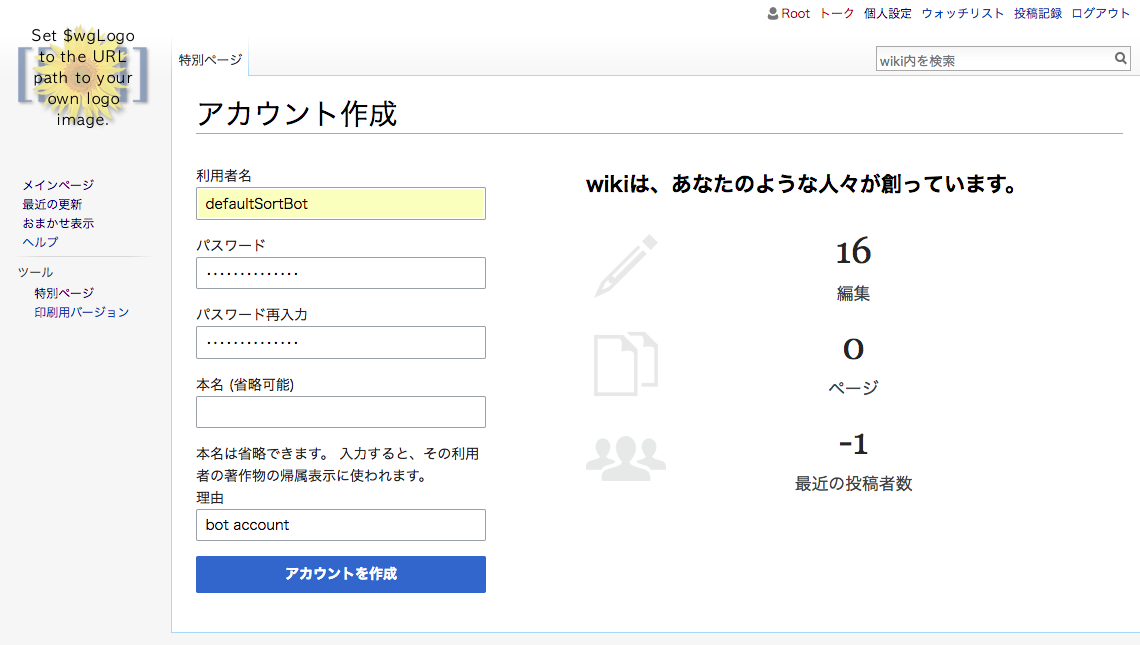
次に、作ったアカウントを「利用者権限を管理」のページでbotグループに追加します。これで更新履歴にデフォルトでは表示されなくなりました。
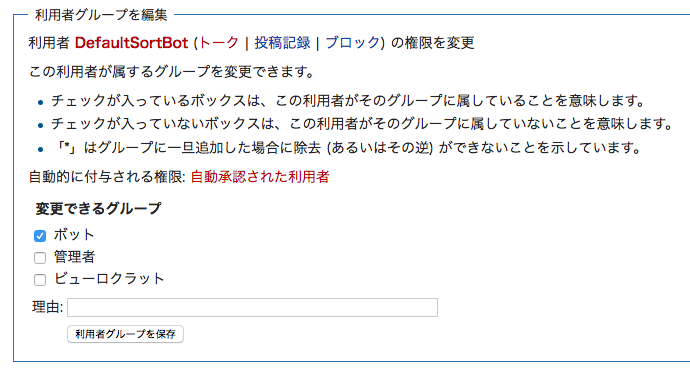
設定ファイルにホスト・api.phpのパス・Botのユーザ名・パスワードを記入してから実行してみます。
$ node main.js
Edited はいプロ/ Bot: Add DEFAULTSORT はいふろ
Edited メインページ/ Bot: Add DEFAULTSORT めいんへえし
Edited 二郎からのセイク/ Bot: Add DEFAULTSORT しろうからのせいく
Edited 五千兆円欲しい!/ Bot: Add DEFAULTSORT こせんちようえんほしい!
Edited 人の金で焼肉が食べたい/ Bot: Add DEFAULTSORT ひとのきんてやきにくかたへたい
Edited 山路を登りながら/ Bot: Add DEFAULTSORT やましをのほりなから
Edited 森鴎外/ Bot: Add DEFAULTSORT もりおうかい
Edited 魔剤/ Bot: Add DEFAULTSORT まさい
Edited カテゴリ:Hoge/ Bot: Add DEFAULTSORT Hoge
/以降は、編集のサマリーとしてWikiの更新履歴にも残ります。所々間違えているものの、ソートに使う分には最初の数文字しか見ないことがほとんどですからそれほど気になりません。
Botの編集履歴にも、結果がきちんと残っていますね。
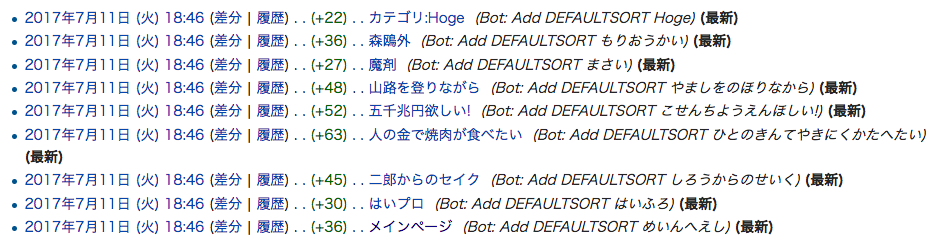
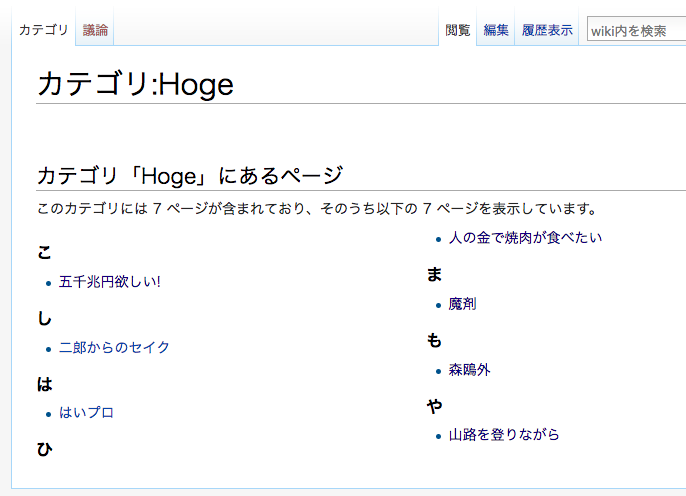
カテゴリ一覧を見ると、ちゃんとひらがなでグループ分けされるようになっています。この例では記事が少なくあまり見た目が変わっていませんが、さらに記事数が増えても50音順に並んでグループ分けされるので、大幅に記事を探しやすくなりそうです。
Tips
参照読み込み時の注意
Mediawikiには、{{}}でページ名などを囲むことでそのページの中身を呼び出せる「参照読み込み」という機能があります。テンプレート機能などで広く使われていますが、呼び出し先ページにもデフォルトソートが設定されていると、「ソートキーが前のソートキーを上書きしている」旨の警告が出てしまいます。
他のページに読み込まれるページではそもそも使わないか、空のデフォルトソートを設定しておくことで回避できるようです。
{{DEFAULTSORT: そおときい}} <- 他ページから読み込むと警告が出る
{{DEFAULTSORT: }} <- 警告が出ない
定期的に実行する
今後の新規ページにもデフォルトソートを追加するために、Botを一定時間おきに稼働させることにします。
書き方が楽そうだったのでnode-cronを使いました。別ファイルにmain.jsを読み込んでcronを設定します(例では1日おき)。
'use strict';
const cron = require('node-cron');
const main = require('./main');
cron.schedule('0 0 * * *', () => { main(); });
foreverを使ってデーモン化します。
sudo npm i -g forever
forever start schedule.js
これで1日以内にできたページにはデフォルトソートが設定されるようになりました。