こんにちは、 @kmotohas です。SB-AI Advent Calendar 2019 の2日目、よろしくお願いします。
本稿ではJavaベースの機械学習モデルデプロイツールである Konduit-Serving の紹介をします。
が、実は私、ソフトバンク株式会社公認のクラブ活動である SB AI部 の発起人でして、この団体の紹介や設立の背景から始めようと思います。
SB AI部とは
ソフトバンク株式会社には福利厚生の一環としてクラブ活動をサポートする制度があります。
社内には多数の部活がありますが、大きく分けてスポーツ系、文化系のジャンルがあります。
スポーツ系はイメージしやすいかと思いますが、バスケやフットサルなど、いわゆるクラブ活動感があるラインナップとなっています。
文化系にはテクノロジー企業らしく、ロボットやIoTを扱うPepper部やドローンレースに参加する団体などがあったりします。
そこに昨年私が新たに設立したのが SB AI部 という団体です。
専用のSlackワークスペースには2019年12月2日現在568名(アクティブメンバーは160名くらい)のソフトバンク関連企業のメンバーが参加しています。
そちらでAI関連の話題の共有、イベント情報、質問、議論、企画、雑談、希望メンバー同士のシャッフルランチなどなどが行われています。
SB AI部設立の背景
ソフトバンク株式会社のテクノロジーユニットではこれまた素敵な Technical Meister という社内認定制度があります。
Yahoo Japanの黒帯制度を参考に設立された制度で、社内に散らばっている技術に強い人にスポット当てるものです。
認定されると年間 😃😄😊万円(見せられないよ!)の個人予算が割り当てられ、国際会議やイベントへの参加費や渡航費に用いたり、イベント開催の費用に用いたり、ハイスペックなPCを買ったり、何かしらの発注を行ったりできるわけです。
認定される「技術」には様々あり、ネットワーク、5G通信、インフラストラクチャ、ディープラーニング、画像処理、自然言語処理、ロボット制御などの分野でそれぞれ認定されている方がいます。
毎年審査があり、今後ももしかしたら量子コンピューターやブロックチェーンなど、先進的な分野においてTechnical Meister認定される方が出てくるかもしれません。
認定されたTechnical Meisterの人々にはある程度社内外発信などの貢献が求められます。
そこで僭越ながらディープラーニング分野のTechnical Meisterとして認定された私はSB AI部を立ち上げたのです。
設立以前から全社を上げて**"AI"を推進していく**というスローガンが掲げられていました。
エンジニアのみならず、経理・事務等バックオフィス系の方々や営業の方々もそれぞれ独自のAI施策を企画・実行していて非常に盛り上がっています。
それぞれがそれぞれで頑張っていると多様性が出て色々独創的なアイデアが創出されます。
もちろんこれは素晴らしいことなのですが、どんな分野でも初学者は得てして同じようなところでつまずいたり、疑問を持ったりするものですよね。
そこで、部署横断的にAI関連の話題を扱えるコミュニティスペースを作ったわけです。
なお現在部長の座は、学生時代全脳アーキテクチャー若手の会副理事をやっていた松岡さんに譲っており、彼がまた精力的に部を盛り上げてくれています。
Twitterなどで有名なコミさんも春から社員となり、きっとまた部の熱量が上がっていくことでしょう。
機械学習モデルのデプロイ
導入部分を書いていたら熱中してしまいつい長くなりました。本題に入ります。
近年のディープラーニングの発展には目を見張るものがあります。コンピュータービジョンや自然言語処理、レコメンデーション、自動運転、はたまたゲームの世界などの幅広い領域においてディープラーニングが応用され、華々しい研究成果が毎日のようにニュースとして流れてきています。TensorFlow、Keras、PyTorch、Chainerなど、研究開発向けの優れた Python ベースの開発フレームワークの存在もこの成功の一翼を担ってるかと思います。しかし、ディープラーニングのモデルを本番環境へデプロイする際の方法論にはまだ確固たるものはなく、実務者の方々がそれぞれ試行錯誤しているのが現状です。
と、いきなり引用しましたが、こちらはオライリージャパンの「詳説Deep Learning --- 実務者のためのアプローチ」の監訳者前書きの一説です。拙文です。(ステマ)
近年におけるディープラーニングなど機械学習分野の発達はそれはもう本当に凄まじいことになっており、個人で最新論文を追うのはもはや不可能なレベルになっています。
開発フレームワークとしてはGoogleが開発したTensorFlowが長らく圧倒的人気を誇っていたのですが、FaceBookが開発したPyTorchというフレームワークのユーザーが急増してきて、現在TensorFlowとPyTorchが二大ライブラリとなっています。
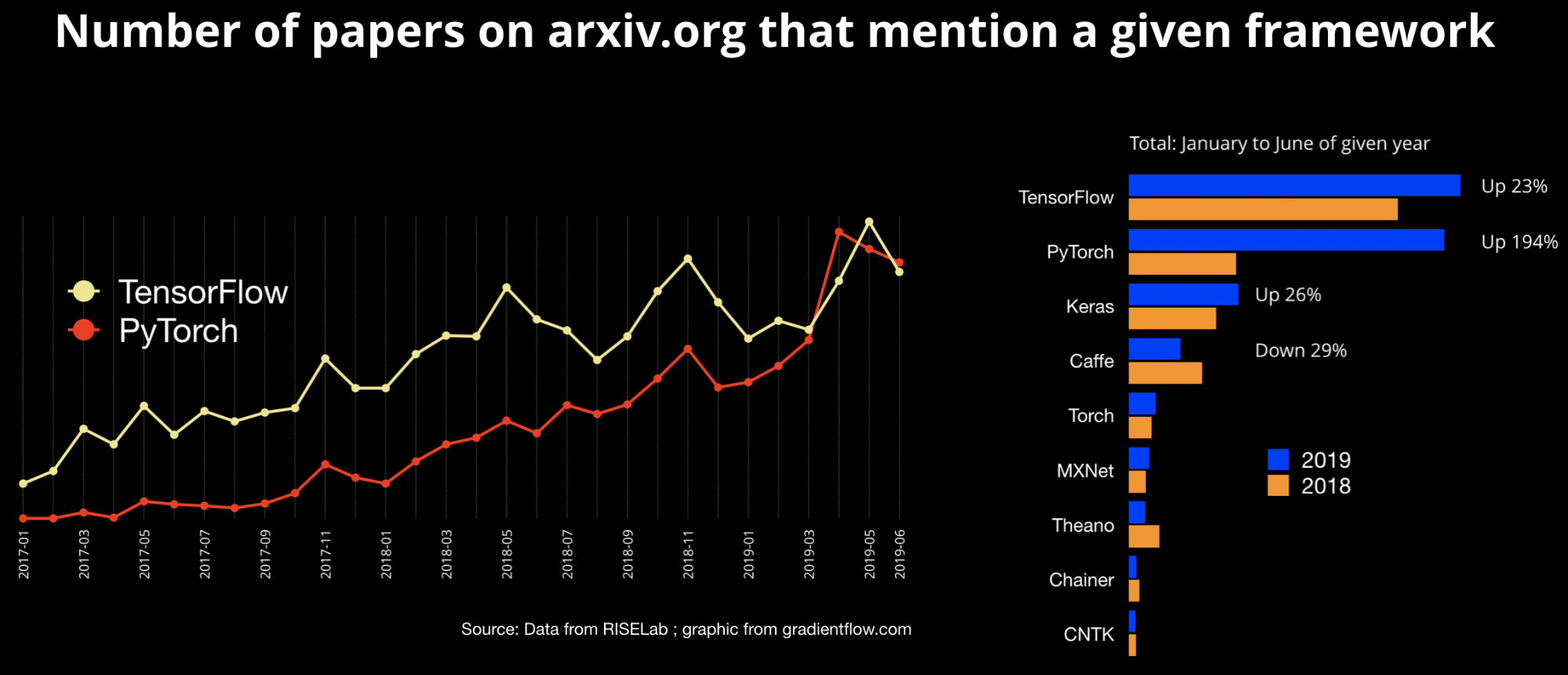
出典 https://www.oreilly.com/ideas/one-simple-graphic-researchers-love-pytorch-and-tensorflow
ただ注意したいのは、ディープラーニングとかいわゆるAIの文脈ではしばしば研究分野と産業分野がごっちゃに語られていることです。
PyTorchは学術研究分野やイノベーター・アーリーアダプター達に広く用いられていますが、産業分野ではまだまだTensorFlowに軍配が上がるようです1。
The State of Machine Learning Frameworks in 2019 では、研究者は試行錯誤のしやすさを重視し、産業ではパフォーマンスが重視されると述べています。
また、モデルのデプロイにおける要件について以下のように述べています。
- No Python. Some companies will run servers for which the overhead of the Python runtime is too much to take.
- Mobile. You can’t embed a Python interpreter in your mobile binary.
- Serving. A catch-all for features like no-downtime updates of models, switching between models seamlessly, batching at prediction time, and etc.
企業のシステムをPythonで動かしている事例はまだ全体に比べると少なく、iOSやAndroidアプリのバイナリにPythonインタープリターを組み込むことはできないし、ダウンタイムなしにモデルを切り替えたり、バッチ推論したいという事情があります。
こういった要望に対してTensorFlowは静的なグラフ構築やTensorFlow Lite、TensorFlow Serving (TensorFlow Extended)といったサービスで対応しているのですね。
そもそも「デプロイ」とは
関係あるのかないのか微妙なところですが、学生の頃、捻くれていたので「ソリューション」って言葉が苦手でした。
就活時に企業研究としていろんな会社のホームページを見ていると「○○のソリューション」みたいな何だかよくわからない何も言っていない気がする言葉が並んでいて気色悪く感じたものです。
今はもう慣れてむしろソリューションとしか表現できないなって気持ちになっているのですが、「デプロイ」も初めに聞いたとき何のこっちゃよくわかりませんでした。
要するに「システムを利用可能な状態にすること」ですね。
Javaで開発したWebアプリケーションをパックしたJARファイルをサーバーに配置することをデプロイと呼んだりするって感じです。
こと機械学習モデルにおいては以下の三つのアプローチがよく用いられています。(参考: Continuously Delivery for Machine Learning)
- モデルの組み込み: 一番単純なアプローチ。指定したモデルを読み込んで利用するコードを直接メインのアプリケーションの中に記述する。
- 外部サービスとしてモデルをデプロイ: メインのアプリケーションとは別のサービス(REST APIなど)としてモデルを配布する。モデルの更新を独立して個別にリリース、バージョニングできる。予測ごとにリモートの呼び出しが必要なので、レイテンシーが発生する可能性あり。
- データとしてモデルを配布: 2番目のアプローチと同様にモデルを独立に扱う。ただし、メインのアプリケーションの実行時にデータとしてモデルをsubscribeする。新しいバージョンのモデルがリリースされたらそのモデルをメモリに読み込んで利用する。
メインのシステムがJavaで記述されていて、そこに機械学習モデルをデプロイするケースを考えます。
1のアプローチが右図で、2のアプローチが左図にあたります。

1のアプローチでは例えばDeeplearning4jなどJavaで開発できるフレームワークで最初からモデル構築したりデータフローを作ったりします。
また、機械学習エンジニアの方々がTensorFlowなどPythonベースのフレームワークで作ったモデルを用いたい場合はTensorFlow for JavaやDeeplearning4j suiteのSameDiffを用いたりしてJavaのオブジェクトに変換します。
ただし、モデルがやってくれることはテンソルに変換されたデータを受け取り、推論をし、結果のテンソルを出力することです。
その前後に必要な前処理や後処理は再度Javaで記述し直す必要があります。
開発の分業のしやすさやモジュール化(マイクロサービス化)による柔軟性の利点から、感覚的には2のアプローチがよく用いられている気がします。
Javaプロセスの役割はREST APIなどを経由して生データを渡し、結果を受け取ることだけで、前処理や後処理は外部サービスに押し込めることができます。
このREST API作成のサポートをしてくれる「ソリューション」のひとつがKonduit-Servingです。
Konduit-Servingとは
Konduit-Servingとは、Deeplearning4j 開発者 Adam Gibson を中心に開発されているJavaベースのオープンソースの機械学習モデルデプロイツールのことです。

TensorFlowやKeras、DL4Jといったフレームワークで作成されたモデルや、PMML、ONNX、PFAといった汎用的なフォーマットのモデルをREST APIとしてデプロイすることができます。
また、面白いのはPythonコードそのものをデプロイできる点です。これについては後述します。
Konduit-Servingは主に以下の3つのライブラリをベースに開発されています。
- JavaCPP: C++で書かれたコード (CUDA/TensorFlow/NumPy/etc) のJavaラッパーを作成
- Eclipse Deeplearning4j: JVM用ディープラーニングフレームワーク
- Eclipse Vert.x: イベントドリブンアプリ開発フレームワーク
JavaCPPによりJavaでもCUDAによるGPUアクセラレーションの恩恵を受けることができ、TensorFlowやNumpyなどPython界隈で広く用いられているライブラリをJava上で用いることができます2。
また、Deeplearning4jのツール群を用いてND4JによるJava上での行列計算や、Keras model importの機能を利用しています。
そして、Vert.xベースにノンブロッキングで効率的なスケール性のあるAPIを構築できます。
Javaの知識がないと利用できないかというとそういうこともなく、Python SDKが用意されているため、機械学習エンジニアにも安心です。
その他流行りのコンテナオーケストレーターKubernetes統合もサポートされており、PrometheusとGrafanaと連携してパフォーマンスや様々なメトリックのモニタリングも簡単に行うことができます。
Java上の組み込みPythonインタープリターを利用してPythonコードそのままデプロイ
上記の「Pythonコードをそのままデプロイ」の意味を解説します。
Konduit-ServingにはPythonインタープリターが内包されています。
先ほど「Mobile. You can’t embed a Python interpreter in your mobile binary.」と書いたばかりですが、工夫すれば何とかなるのです。
Pythonコードに含まれているオブジェクトはメモリに展開され、そのポインターに直接アクセスすることでゼロコピーでJavaからPythonコードを扱えるようになります。
まあ正直私も詳しいところは理解していないのですが、とにかくJava上でPythonを扱うことができるのです。
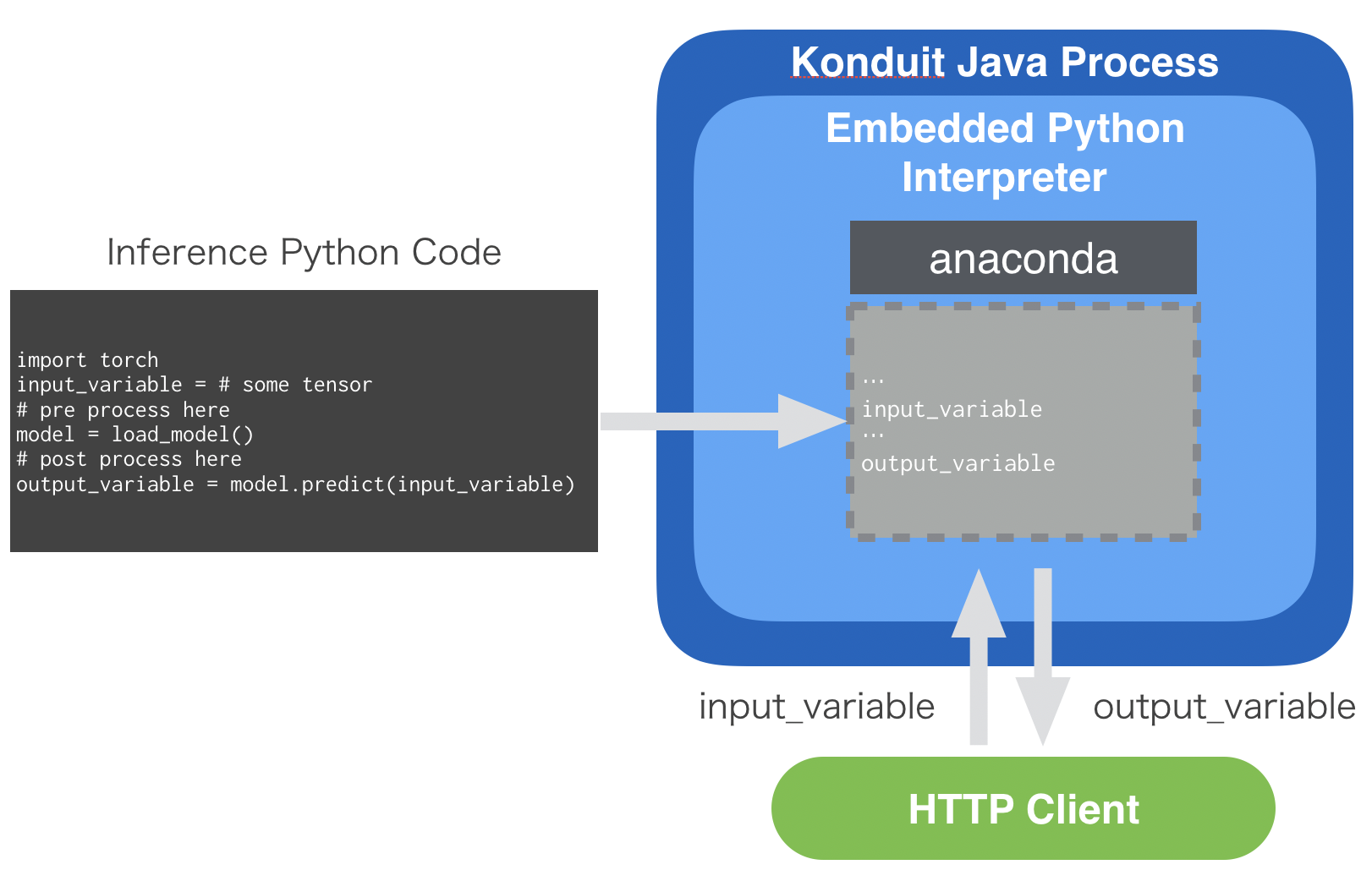
利用方法としてはKonduit-ServingでデプロイされたPythonコードに対して、HTTPのクライアントから入力データを送信します。
すると同名の変数のポインタが書き換えられ、組み込みのPythonが実行され、結果を格納した変数の中身をクライアントに返します。
これの何が嬉しいかというと、機械学習エンジニアの方が実験に用いたコードをプロダクションに流用できるので、コード書き直しの工数を減らすことができるというのと、任意のPythonライブラリを利用できるメリットがあります。
(勘がいい方はお気づきかもしれませんが、Pythonを用いるとGILに囚われてしまい、せっかくのJavaのマルチスレッド性を失ってしまいます。トレードオフということですね。Konduit-Servingを用いてモデルをそのままデプロイする場合はマルチスレッドで高パフォーマンスを発揮できます。)
サンプル: 顔認識モデルのデプロイ
ここではPyTorchで開発された顔認識モデルを用いた推論コードをKonduit-Servingでデプロイするデモを紹介します。
Konduit-Servingのセットアップ
それではKonduit-Servingのセットアップから初めてみましょう。
なお、私は Ubuntu 18.04 (w/o GPU) で検証しました。
git、Java Development Kit 8 (1.8)、Javaのビルド管理ツールのMavenが必要です。
まず、Anacondaなどを用いて環境を切ります。Pythonのバージョンは3.7(以上?)が推奨されています。
conda create -n konduit python=3.7
conda activate konduit
GitHubからソースコードをクローンし、また、Python SDKをインストールします。
git clone https://github.com/KonduitAI/konduit-serving.git
cd konduit-serving/python
# conda install cython 必要かも
python setup.py install
cd ..
プロジェクトをビルドし、uber jarファイルを作成します。
konduit init --os <your-platform>
# windows-x86_64, linux-x86_64`, linux-x86_64-gpu,
# macosx-x86_64, linux-armhf and windows-x86_64-gpu
# e.g.) konduit init --os linux-x86_64
現在のバージョンでは ~/.konduit/konduit-serving/konduit-serving-uberjar/target/konduit-serving-uberjar-1.2.1-bin.jar に生成されます。
1.2.1の部分はバージョンによります。
ドキュメントには~/.konduit/konduit-serving/konduit.jarにコピーが生成されると書いてありますが、私の環境ではできませんでした。
(すぐ修正されるでしょう。)
以下ではドキュメントに沿った解説をします。今のところは cp ~/.konduit/konduit-serving/konduit-serving-uberjar/target/konduit-serving-uberjar-1.2.1-bin.jar ~/.konduit/konduit-serving/konduit.jar などしてあげてください。
次に、uber jarのパスを環境変数KONDUIT_JAR_PATHに設定します。
echo export KONDUIT_JAR_PATH="~/.konduit/konduit-serving/konduit.jar" >> ~/.bashrc
source ~/.bashrc
# conda activate konduit し直す必要あるかも
# conda activateとすると環境変数がリセットされることがあるので
# export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 などする
これで準備完了です。
顔認識プロジェクトの準備とREST API化
サンプルが置いてあるディレクトリに移動します。
# konduit-servingのディレクトリにいると仮定
cd python/examples/face_detection_pytorch
ここで用いるモデルはPytorchで開発された非常に軽量な顔認識モデルです。
コードをクローンし、依存ライブラリをインストールします。
git clone https://github.com/Linzaer/Ultra-Light-Fast-Generic-Face-Detector-1MB
pip install -r ./Ultra-Light-Fast-Generic-Face-Detector-1MB/requirements.txt
こちらのリポジトリで公開されている推論コードはこちらです。
https://github.com/Linzaer/Ultra-Light-Fast-Generic-Face-Detector-1MB/blob/master/detect_imgs.py
このコードではディレクトリを指定するとそこに含まれる画像をモデルに入力し、検出された顔のbounding boxを描画した画像を出力します。

今回のサンプルではもう少し単純なものになっています。
インプットはBase64エンコードされた画像データ、アウトプットは画像から検出された顔の数とします。
上記の推論コードをサンプル用に修正し、簡略化したものがこちらです。
https://github.com/KonduitAI/konduit-serving/blob/master/python/examples/face_detection_pytorch/detect_image.py
import os
import sys
work_dir = os.path.abspath('./Ultra-Light-Fast-Generic-Face-Detector-1MB')
sys.path.append(work_dir)
from vision.ssd.config.fd_config import define_img_size
from vision.ssd.mb_tiny_RFB_fd import create_Mb_Tiny_RFB_fd, create_Mb_Tiny_RFB_fd_predictor
from utils import base64_to_ndarray
threshold = 0.7
candidate_size = 1500
define_img_size(640)
test_device = 'cpu'
label_path = os.path.join(work_dir, "models/voc-model-labels.txt")
test_device = test_device
class_names = [name.strip() for name in open(label_path).readlines()]
model_path = os.path.join(work_dir, "models/pretrained/version-RFB-320.pth")
net = create_Mb_Tiny_RFB_fd(len(class_names), is_test=True, device=test_device)
predictor = create_Mb_Tiny_RFB_fd_predictor(net, candidate_size=candidate_size, device=test_device)
net.load(model_path)
# The variable "image" is sent from the konduit client in "konduit_server.py", i.e. in our example "encoded_image"
image = base64_to_ndarray(image)
boxes, _, _ = predictor.predict(image, candidate_size / 2, threshold)
# "num_boxes" is then picked up again from here and returned to the client
num_boxes = str(len(boxes))
大事なのは下記の部分です。
# The variable "image" is sent from the konduit client in "konduit_server.py", i.e. in our example "encoded_image"
image = base64_to_ndarray(image)
boxes, _, _ = predictor.predict(image, candidate_size / 2, threshold)
# "num_boxes" is then picked up again from here and returned to the client
num_boxes = str(len(boxes))
imageがクライアントから送信される入力で、num_boxesが出力です。
こちらをKonduit-Servingでデプロイし、クライアントからリクエストを送ってみます。
python run_server.py
うまく動作すれば、長々とログやデバッグメッセージが表示されたあと以下のように顔の数(この場合51)が返されます。
...
02:37:13.585 [vert.x-worker-thread-6] INFO a.k.s.executioner.PythonExecutioner - Exec done
02:37:13.586 [vert.x-worker-thread-6] INFO a.k.s.executioner.PythonExecutioner - CPython: PyEval_SaveThread()
02:37:13.586 [vert.x-worker-thread-6] INFO a.k.s.executioner.PythonExecutioner - CPython: PyEval_RestoreThread()
02:37:13.586 [vert.x-worker-thread-6] INFO a.k.s.executioner.PythonExecutioner - temp_27_main.json
02:37:13.586 [vert.x-worker-thread-6] INFO a.k.s.executioner.PythonExecutioner - Executioner output:
02:37:13.586 [vert.x-worker-thread-6] INFO a.k.s.executioner.PythonExecutioner - {"num_boxes": "51"}
02:37:13.586 [vert.x-worker-thread-6] INFO a.k.s.executioner.PythonExecutioner - CPython: PyEval_SaveThread()
02:37:13.586 [vert.x-worker-thread-6] INFO a.k.s.executioner.PythonExecutioner - CPython: PyEval_RestoreThread()
51
run_konduit.py の中身は以下の通りです。
from konduit import *
from konduit.server import Server
from konduit.client import Client
from konduit.utils import default_python_path
import os
from utils import to_base_64
# Set the working directory to this folder and register the "detect_image.py" script as code to be executed by konduit.
work_dir = os.path.abspath('.')
python_config = PythonConfig(
python_path=default_python_path(work_dir), python_code_path=os.path.join(work_dir, 'detect_image.py'),
python_inputs={'image': 'STR'}, python_outputs={'num_boxes': 'STR'},
)
# Configure a Python pipeline step for your Python code. Internally, konduit will take Strings as input and output
# for this example.
python_pipeline_step = PythonStep().step(python_config)
serving_config = ServingConfig(http_port=1337, input_data_format='JSON', output_data_format='JSON')
# Start a konduit server and wait for it to start
server = Server(serving_config=serving_config, steps=[python_pipeline_step])
server.start()
# Initialize a konduit client that takes in and outputs JSON
client = Client(input_data_format='JSON', output_data_format='RAW',
return_output_data_format='JSON', host='http://localhost', port=1337)
# encode the image from a file to base64 and get back a prediction from the konduit server
encoded_image = to_base_64(os.path.abspath('./Ultra-Light-Fast-Generic-Face-Detector-1MB/imgs/1.jpg'))
predicted = client.predict({'image': encoded_image})
# the actual output can be found under "num_boxes"
print(predicted['num_boxes'])
server.stop()
今回はBase64エンコードされた画像(image)をJSONで送って顔の数(num_boxes)をJSONに入れて返すというデモでした。
そのためPythonConfigで入出力の型を'STR'と指定しています。
ServingConfigではフォーマットを'JSON'にしています。
参考:
server.start()でサーバーを走らせ、REST APIを準備します。
そして、predicted = client.predict({'image': encoded_image})の行でエンコードした画像を'image'という文字列をセットにしてサーバーにPOSTしています。
返ってきた結果のJsonがpredicted変数に格納されます。
print(predicted['num_boxes'])の出力が先ほどの51だったのです。
おわりに
いかがでしたでしょうか。
Konduit-Servingはまだ公開されて間もないライブラリですので、変更が多かったりややドキュメントに不整合があったりしますが、デプロイ支援ツールとして可能性があると思っています。
今後また解説記事など公開していくつもりなので乞うご期待。
SB-AI Advent Calendar 2019、次回は営業の期待のホープ、那俄牲さんです :)
-
https://thegradient.pub/state-of-ml-frameworks-2019-pytorch-dominates-research-tensorflow-dominates-industry/ ↩
-
余談ですが、OpenCVのJavaラッパーであるJavaCVはJavaCPPを用いて移植されています。JavaCPPを用いて移植されたパッケージのプリセットたちはここで公開されています。 ↩